数据分析技术:决策树分析;机器学习入门模型
基础准备
草堂君前面介绍过好几种用于结果分类和判别的数据分析方法,有以下几种,大家可以点击下方文章链接回顾:
-
数据分析技术:聚类分析;可怕的不是阶层固化,而是因此放弃了努力。
-
数据分析技术:判别分析;
-
数据分析技术:Logistic回归分析原理;好不好看疗效,两种治疗方法的效果比较!
在上面这些个案分类方法中,包括聚类分析、判别分析和逻辑回归分析,加上今天将要介绍的决策树分析,这些分类方法之间有什么区别呢?
分类方法对比
需要明确,聚类分析、判别分析、逻辑回归和决策树这些分类方法,它们的分类对象是个案(研究对象),比如人、家庭、公司或国家等,这些分类对象都有一个共同点,那就是它们身上的标签或属性是多维和复杂的。例如,当今时代,剩男与剩女问题严峻,选择合适的结婚对象,需要从身高、体重、长相、学历、人品、脾气、家庭条件等很多角度进行考察;同样的,评价一家公司的好坏,可以从工作量、福利待遇、公司文化、办公环境、盈利情况等角度进行评价;银行和商业公司在记录用户信息时,会记录包括年龄、性别、学历、收入、工作单位、家庭成员、银行存款、贷款情况、还款情况等信息。正是因为研究对象的多属性和多维度,所以研究对象的分类从来就不是一个简单的操作。
如何确定应该选择哪种分类方法呢?首选可以根据是否有分类目标将以上这些方法分成两大类:聚类分析与其它分析方法。聚类分析在将研究对象分类之前是没有目标类别的,或者说是探索性的,例如,某公司希望做细做深市场,那么就需要对它们目前的客户进行分类,分析不同类别客户的属性区别,然后才能有针对性的对不同类别客户采用不同的营销手段。第二类就是在分类之前已经有明确的分类目标,例如,银行希望根据客户还款记录的好坏,将所有客户分成两类,那么就可以使用判别分析、逻辑回归和决策树分析研究还款记录好的客户与还款记录坏的客户的属性组合,比如通过家庭情况、收入水平、学历水平、年龄、性别等属性来预测将来客户的还款结果是好是坏,最大可能的避免违约的情况出现。现在知道为什么在申请银行贷款的时候,需要查大家的祖宗十八代信息了吧,用来判断你有多大的概率会违约不还款。
属性变量是什么类型的数据?在数据分析领域,最终的数据分析方式就是将数据分成定类、定序和定距数据。判别分析适合定距数据,决策树和逻辑回归分析适合定类和定序数据。当然,这里的适合并不意味着决策树和逻辑回归分析就不能用于定距数据的分析。草堂君建议大家在充分掌握每种分析方法的分析原理以后,再结合实际的数据分析环境选择合适的分析方法。
决策树分析
从上面介绍的内容可知,决策树分析适用于有明确的研究对象分类结果,研究每种类别群体的属性特点和性质,换种说法就是通过建立模型,可以通过某个研究对象身上的属性特点,判断该研究对象最可能落在那个分类群体中。决策树分析在很多行业中应用得非常广泛,同时也是机器学习中最基础也是应用最广泛的算法模型。
我们举个具体的例子来说明决策树分析的应用。某个银行通过对其内部数据的分析,建立了一个决策树模型,用于预测申请贷款的用户是否具有偿还贷款的能力。该决策树模型需要考虑三个贷款用户的属性:是否拥有房产,是否结婚和平均月收入。这个决策树模型如下图所示:
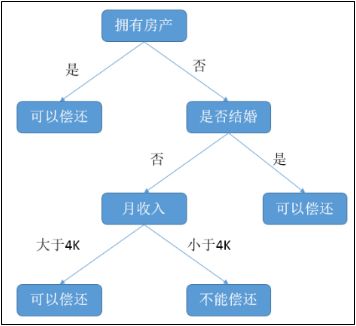
每个分叉点称为节点,表示一个属性条件的判断;每个终端点称为叶子节点,表示对贷款用户是否具有偿还能力的最终判断。假设现在有一个申请贷款的客户甲,他的情况是没有房产,没有结婚,月收入五千。通过上面决策树模型的判断,用户甲最终被判断为具备偿还贷款能力,银行可以考虑为其提供贷款,这就是决策树分析的作用。
决策树模型
从上面的决策树分析思路可知,建立决策树模型主要包括两个步骤:节点变量的选择以及每个节点的分支概率的确定。在决策树分析中,节点变量的选择可以通过卡方检验、最大熵减少量、基尼系数减少量等方式来完成,首先筛选与目标分类变量显著相关的变量,如果同时有几个变量与目标分类变量相关,那么再根据相关程度的大小,安排变量的进入顺序;分支概率则通过已有数据来确定即可。
以上这两个步骤都会随着样本数据量的变化而变化,这就引出了机器学习中的两个名词:训练集和测试集。训练集是用来进行训练的集合,也可以理解为原始数据;测试集是用来检测用训练集训练出来的模型的好坏。模型训练其实就是不断的增加进入模型的样本数据量,随着样本量的不断增加,以上两个步骤的结果也会不断修正,变得越来越准确。
决策树算法
SPSS提供了四种决策树算法:CHAID、Exhaustive CHAID、CART和QUEST。它们在变量相关性的判定准则上有区别,下面我们简要介绍下每种算法的特性。
CHAID,英文全称为Chi-squaredAutomatic Interaction Detector,也就是卡方自动交互检验。从名称就可以看出,该决策树算法是以卡方检验为判定准则的。需要注意,CHAID方法的变量都是分类变量(因变量和自变量),如果有连续型变量,系统会自动将其转换为分类变量。CHAID方法的决策树生长过程分成两个步骤:合并和分裂。软件首先对每个自变量与因变量之间的相关性进行卡方检验,如果自变量中有的水平没有显著性差异,那么就进行合并,然后再重新水平分类,直到自变量中所有的水平都有显著性差异为止。接着就是分裂过程,也就是决策树生长过程,考察重新水平分类后的自变量与因变量之间的相关性,决定自变量进入决策树的顺序,相关性由高到低依次进入,直到都有显著性差异,不需要继续分裂为止。
Exhaustive CHAID,穷举卡方自动交互检验,是CHAID方法的改进算法。它与CHAID算法的主要区别在于合并步骤。CHAID在水平合并过程中,如果发现水平之间有显著性差异,那么就停止合并,而ExhaustiveCHAID则不同,它会考察所有水平之间的差异性,最终形成两个大水平,然后再对两个大水平进行分组,形成有差异的水平组。
CART,英文全称为Classificationand Regression Trees,也就是分类与回归树。与CHAID和Exhaustive CHAID不同,CART决策树在每个节点上的分支数都是两支,并且CART算法的检验准则不是卡方值,而是采用了最大熵减小量或基尼系数减少量。
QUEST,英文全称quickunbiased efficient statistical tree,也就是快速无偏有效统计树。该算与CART一样,都只能生成二叉树,也就是每个节点的分支数只有两个。QUEST算法的优势在于能够快速且不偏的建立决策树。
总结一下
决策树分析是一种通过历史数据建立决策树模型,然后用于分类结果判断的分析方法。经常用在市场研究、信用风险分析、产品销售策略研究等领域。模型建立后,可以非常方便的帮助业务人员对于结果的判断,只需采集需要的研究对象属性变量,代入模型计算即可;同时,模型还会随着数据量的增大,数据的更新不断修正。
决策树分析是机器学习最基本的模型之一。因为模型设计的数学概念较多,草堂君在这里不详细介绍,这部分内容会在介绍数据挖掘技术时重点介绍。对于普通用户来说,只需理解决策树的概念,作用和宏观分析思路即可;对于决策树的四种算法,普通用户可以通过对比结果准确性来选择最合适自己的算法。
决策树分析的SPSS应用会在下篇文章中推送。
温馨提示:
-
数据分析课程私人定制,一对一辅导,添加微信(possitive2)咨询!
-
生活统计学QQ群:134373751,用于分享文章提到的各种案例资料、软件、数据文件等。支持各种资料的直接下载和百度云盘下载。
-
生活统计学微信交流群,用于各自行业的数据研究项目及其成果交流分享;由于人数大于100人,请添加微信possitive2,拉您入群。
-
数据分析咨询,请点击首页下方“互动咨询”板块,获取咨询流程!
