keras 使用DCGAN生成二次元人物头像
import msvcrt
import os
import time
import tensorflow as tf
from keras import backend as K
import keras.backend.tensorflow_backend as KTF
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
import keras
from keras import layers, Sequential, models
import numpy as np
# 手动分配GPU
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # 不全部占满显存, 按需分配
# config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 指定分配50%空间
sess = tf.Session(config=config) # 设置session
KTF.set_session(sess)
# IO参数
latent_dim = 100
img_shape = (96, 96, 3)
# ************************** 生成器
def build_generator():
model = Sequential()
model.add(layers.Dense(512 * 6 * 6, activation='relu', input_dim=latent_dim)) # 输入维度为100
model.add(layers.Reshape((6, 6, 512)))
model.add(layers.UpSampling2D()) # 进行上采样,变成14*14*128
model.add(layers.Conv2D(256, kernel_size=5, padding='same'))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.Activation("relu")) #
model.add(layers.UpSampling2D())
model.add(layers.Conv2D(128, kernel_size=5, padding="same"))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.Activation("relu"))
model.add(layers.UpSampling2D())
model.add(layers.Conv2D(64, kernel_size=5, padding="same"))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.Activation("relu"))
model.add(layers.UpSampling2D())
model.add(layers.Conv2D(img_shape[-1], kernel_size=5, padding="same"))
model.add(layers.Activation("tanh"))
model.summary() # 打印网络参数
noise = models.Input(shape=(latent_dim,))
img = model(noise)
return models.Model(noise, img) # 定义一个 一个输入noise一个输出img的模型
# ************************** 判别器
def build_discriminator():
model = Sequential()
dropout = 0.4
model.add(layers.Conv2D(64, kernel_size=5, strides=2, input_shape=img_shape, padding="same"))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(128, kernel_size=5, strides=2, padding="same"))
model.add(layers.ZeroPadding2D(padding=((0, 1), (0, 1))))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(256, kernel_size=5, strides=2, padding="same"))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(512, kernel_size=5, strides=1, padding="same"))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dropout(dropout))
model.add(layers.Flatten())
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
img = models.Input(shape=img_shape)
validity = model(img)
return models.Model(img, validity)
def load_dir_img(sorcedir):
print('正在读取图片...')
files = os.listdir(sorcedir)
data = np.zeros((files.__len__(),) + image.img_to_array(image.load_img(os.path.join(sorcedir, files[0]))).shape)
for i in range(files.__len__()):
data[i] = image.img_to_array(image.load_img(os.path.join(sorcedir, files[i])))
return data / 127.5 - 1
# ************************** 建模
optimizer = keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
# 对判别器进行构建和编译
discriminator = build_discriminator()
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
# 对生成器进行构造
generator = build_generator()
# 构造对抗模型
# 总体模型只对生成器进行训练
discriminator.trainable = False
input_noise = models.Input(shape=(latent_dim,))
combined = models.Model(input_noise, discriminator(generator(input_noise)))
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
# ************************** Load Data
# 数据来源:https://drive.google.com/drive/folders/1mCsY5LEsgCnc0Txv0rpAUhKVPWVkbw5I?usp=sharing
x = load_dir_img(r'C:\Users\78753\.keras\data\2faces\96\faces')
# ************************** 训练
"""
gdrate:额外的生成器训练比率(判别器50%额外训练0次,100%额外训练gdrate次)
save_interval:保存间隔(steap)
"""
def run(epochs=100, batch_size=256, save_interval=50, gdrate=3, save_dir='.\\gan_image', history=None):
last_time = time.clock()
start_epoch = 0
if history is None:
history = []
else:
start_epoch = history[-1][0]
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
for step in range(x.shape[0] // batch_size):
# 按q终止
while msvcrt.kbhit():
char = ord(msvcrt.getch())
if char == 113:
return history
g_loss = -1
# 训练判别器
imgs = x[step * batch_size:step * batch_size + batch_size]
noise = np.random.normal(0, 1, (batch_size, latent_dim))
gen_imgs = generator.predict(noise)
d_loss_real = discriminator.train_on_batch(imgs, valid)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 训练生成器(动态训练比例)
for i in range(1 + int(gdrate * np.maximum(d_loss[1] - .5, 0) * 2)):
noise = np.random.normal(0, 1, (batch_size, latent_dim))
g_loss = combined.train_on_batch(noise, valid)
# Log
if step % save_interval == 0:
print(
"%d:%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch+start_epoch, step, d_loss[0], 100 * d_loss[1], g_loss))
history.append((epoch+start_epoch, step, d_loss[0], 100 * d_loss[1], g_loss))
combined.save('gan.h5')
# 保存生成的图像
img = image.array_to_img(gen_imgs[0] * 127 + 127., scale=False)
img.save(os.path.join(save_dir, 'train_' + str(epoch+start_epoch) + '_' + str(step) + '.png'))
# 保存真实图像,以便进行比较
# img = image.array_to_img(imgs[0] * 127 + 127., scale=False)
# img.save(os.path.join(save_dir, 'real_' + str(epoch+start_epoch) + '_' + str(step) + '.png'))
# 计时
print('epoch run %d s, total run %d s' % (time.clock() - last_time, time.clock()))
last_time = time.clock()
combined.save('gan.h5')
return history
# ************************** 生成
def generate(generator, num=10, save_dir=r'gan_image'):
noise = np.random.normal(0, 1, (num, K.int_shape(generator.layers[0].input)[1]))
gen_imgs = generator.predict(noise)
for i in range(gen_imgs.shape[0]):
img = image.array_to_img(gen_imgs[i] * 127 + 127., scale=False)
img.save(os.path.join(save_dir, 'generated_' + str(i) + '.png'))
# ************************** 运行
history = run()
batch_size=64,epochs=100运行
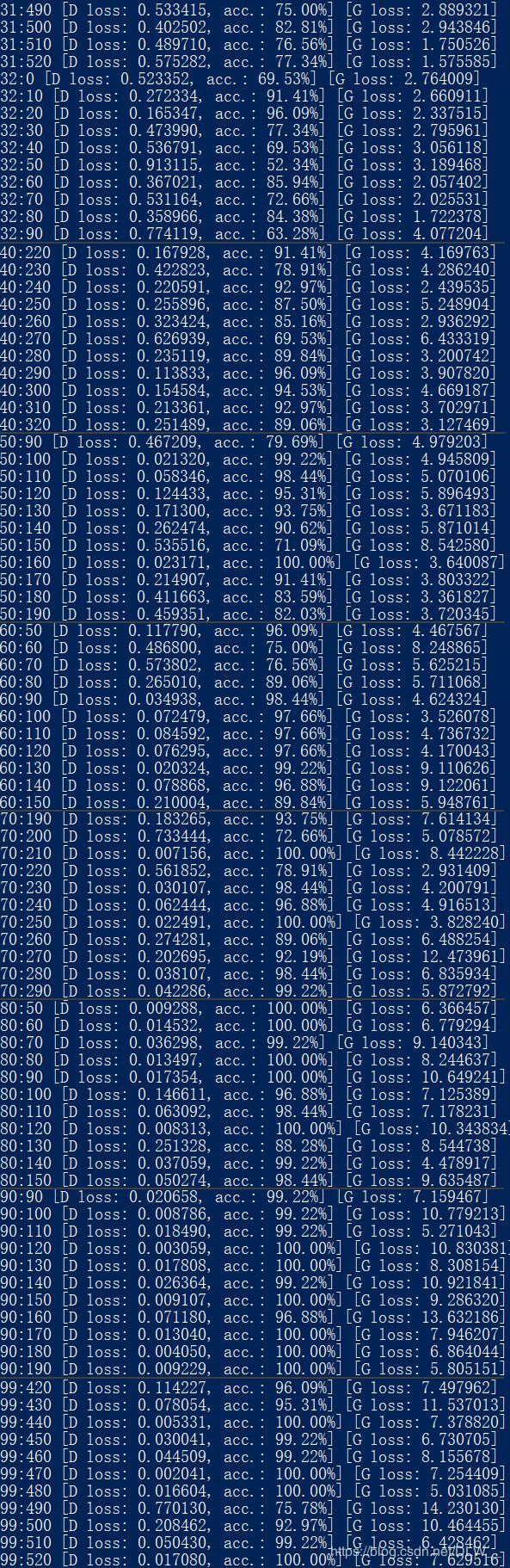
训练过程中的生成:
使用训练好的模型进行生成:
使用Conv2DTranspose代替UpSampling2D+Conv2D
def build_generator():
model = Sequential()
model.add(layers.Dense(512 * 6 * 6, activation='relu', input_dim=latent_dim)) # 输入维度为100
model.add(layers.Reshape((6, 6, 512)))
model.add(layers.Conv2DTranspose(256, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(128, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(64, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(img_shape[-1], 5, strides=2, padding='same'))
model.add(layers.Activation("tanh"))
model.summary() # 打印网络参数
noise = models.Input(shape=(latent_dim,))
img = model(noise)
return models.Model(noise, img) # 定义一个 一个输入noise一个输出img的模型
batch_size=64,epochs=85运行

运行了85个epoch可见效果比之前好了不少
取消ZeroPadding2D
def build_discriminator():
dropout = 0.4
model = Sequential()
model.add(layers.Conv2D(64, kernel_size=5, strides=2, input_shape=img_shape, padding="same"))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(128, kernel_size=5, strides=2, padding="same"))
# model.add(layers.ZeroPadding2D(padding=((0, 1), (0, 1))))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(256, kernel_size=5, strides=2, padding="same"))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(512, kernel_size=5, strides=1, padding="same"))
model.add(layers.BatchNormalization(momentum=0.8))
model.add(layers.LeakyReLU(alpha=0.2))
model.add(layers.Dropout(dropout))
model.add(layers.Flatten())
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
img = models.Input(shape=img_shape)
validity = model(img)
return models.Model(img, validity)
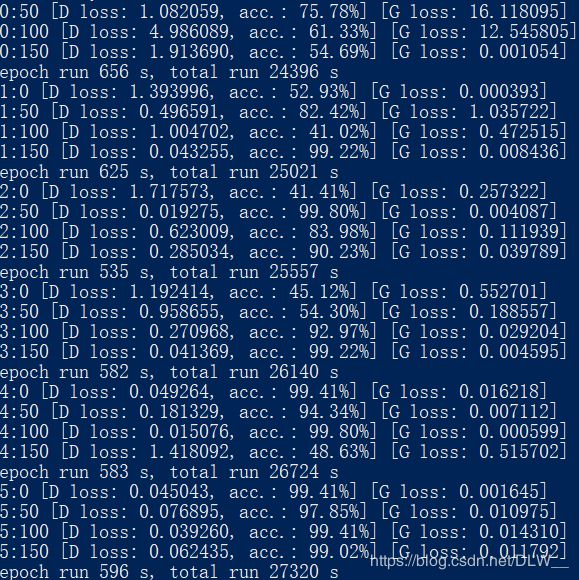
batch_size=256,epochs=45运行


从生成历史中可见训练速度更快了
取消Dropout
Discriminator准确率100%,Generator无法训练
BatchNormalization和LeakyReLU超参数使用默认值
def build_generator():
model = Sequential()
model.add(layers.Dense(512 * 6 * 6, activation='relu', input_dim=latent_dim)) # 输入维度为100
model.add(layers.Reshape((6, 6, 512)))
model.add(layers.Conv2DTranspose(256, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(128, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(64, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(img_shape[-1], 5, strides=2, padding='same'))
model.add(layers.Activation("tanh"))
model.summary() # 打印网络参数
noise = models.Input(shape=(latent_dim,))
img = model(noise)
return models.Model(noise, img) # 定义一个 一个输入noise一个输出img的模型
# ************************** 判别器
def build_discriminator():
dropout = 0.4
model = Sequential()
model.add(layers.Conv2D(64, kernel_size=5, strides=2, input_shape=img_shape, padding="same"))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(128, kernel_size=5, strides=2, padding="same"))
# model.add(layers.ZeroPadding2D(padding=((0, 1), (0, 1))))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(256, kernel_size=5, strides=2, padding="same"))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(512, kernel_size=5, strides=1, padding="same"))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dropout(dropout))
model.add(layers.Flatten())
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
img = models.Input(shape=img_shape)
validity = model(img)
return models.Model(img, validity)
batch_size=256,epochs=28运行
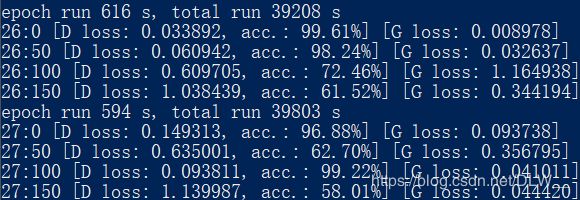
可见在判别器准确率过高的情况下生成器基本上没有进步
训练时共用noise
def run(epochs=100, batch_size=128, save_interval=100, gdrate=3, save_dir='.\\gan_image', history=None):
last_time = time.clock()
start_epoch = 0
if history is None:
history = []
else:
start_epoch = int(history[-1][0])
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
for step in range(x.shape[0] // batch_size):
# 按q终止
while msvcrt.kbhit():
char = ord(msvcrt.getch())
if char == 113:
return history
g_loss = -1
# 训练判别器
imgs = x[step * batch_size:step * batch_size + batch_size]
noise = np.random.normal(0, 1, (batch_size, latent_dim))
gen_imgs = generator.predict(noise)
d_loss_real = discriminator.train_on_batch(imgs, valid)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 训练生成器(动态训练比例)
for i in range(1 + int(gdrate * np.maximum(d_loss[1] - .5, 0) * 2)):
noise = np.random.normal(0, 1, (batch_size, latent_dim))
g_loss = combined.train_on_batch(noise, valid)
# Log
if step % save_interval == 0:
print(
"%d:%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch+start_epoch, step, d_loss[0], 100 * d_loss[1], g_loss))
history.append([epoch+start_epoch, step, d_loss[0], 100 * d_loss[1], g_loss])
combined.save('gan.h5')
generator.save('gan_g.h5')
discriminator.save('gan_d.h5')
# 保存生成的图像
img = image.array_to_img(gen_imgs[0] * 127 + 127., scale=False)
img.save(os.path.join(save_dir, 'train_' + str(epoch+start_epoch) + '_' + str(step) + '.png'))
# 保存真实图像,以便进行比较
# img = image.array_to_img(imgs[0] * 127 + 127., scale=False)
# img.save(os.path.join(save_dir, 'real_' + str(epoch+start_epoch) + '_' + str(step) + '.png'))
# 计时
print('epoch run %d s, total run %d s' % (time.clock() - last_time, time.clock()))
last_time = time.clock()
combined.save('gan.h5')
generator.save('gan_g.h5')
discriminator.save('gan_d.h5')
return history
训练60g
acc:
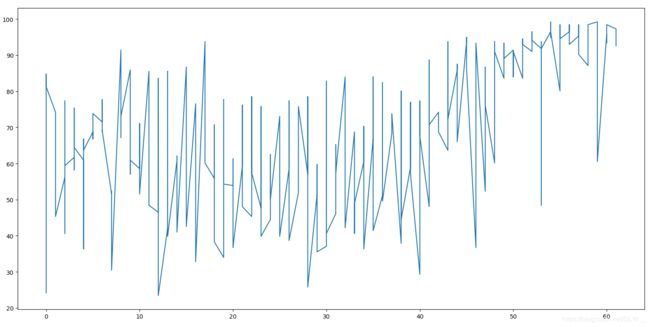
这个其实影响并不大
应用LSGAN
D(x)最后的Sigmoid激活层删除并使用’mse’loss函数:优化生成器训练速度,防止生成器训练停滞
训练120g
acc(70g~120g):

并没有达到预想的效果而且明显看出效果很差,估计是因为网络结构太差的原因
总结
import msvcrt
import os
import time
import tensorflow as tf
from keras import backend as K
import keras.backend.tensorflow_backend as KTF
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
import keras
from keras import layers, Sequential, models
import numpy as np
import matplotlib.pyplot as plt
# 手动分配GPU
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # 不全部占满显存, 按需分配
# config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 指定分配50%空间
sess = tf.Session(config=config) # 设置session
KTF.set_session(sess)
# IO参数
latent_dim = 100
img_shape = (96, 96, 3)
# 通用参数
optimizer = keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
norm_momentum = 0.8
lrelu_alpha = 0.2
# ************************** 生成器
def build_generator():
model = Sequential()
model.add(layers.Dense(512 * 6 * 6, activation='relu', input_dim=latent_dim)) # 输入维度为100
model.add(layers.Reshape((6, 6, 512)))
model.add(layers.Conv2DTranspose(256, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization(momentum=norm_momentum))
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(128, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization(momentum=norm_momentum))
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(64, 5, strides=2, padding='same'))
model.add(layers.BatchNormalization(momentum=norm_momentum))
model.add(layers.Activation("relu"))
model.add(layers.Conv2DTranspose(img_shape[-1], 5, strides=2, padding='same'))
model.add(layers.Activation("tanh"))
model.summary() # 打印网络参数
noise = models.Input(shape=(latent_dim,))
img = model(noise)
return models.Model(noise, img) # 定义一个 一个输入noise一个输出img的模型
# ************************** 判别器
def build_discriminator():
dropout = 0.4
model = Sequential()
model.add(layers.Conv2D(64, kernel_size=5, strides=2, input_shape=img_shape, padding="same"))
model.add(layers.LeakyReLU(alpha=lrelu_alpha))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(128, kernel_size=5, strides=2, padding="same"))
model.add(layers.BatchNormalization(momentum=norm_momentum))
model.add(layers.LeakyReLU(alpha=lrelu_alpha))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(256, kernel_size=5, strides=2, padding="same"))
model.add(layers.BatchNormalization(momentum=norm_momentum))
model.add(layers.LeakyReLU(alpha=lrelu_alpha))
model.add(layers.Dropout(dropout))
model.add(layers.Conv2D(512, kernel_size=5, strides=1, padding="same"))
model.add(layers.BatchNormalization(momentum=norm_momentum))
model.add(layers.LeakyReLU(alpha=lrelu_alpha))
model.add(layers.Dropout(dropout))
model.add(layers.Flatten())
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
img = models.Input(shape=img_shape)
validity = model(img)
return models.Model(img, validity)
# 从文件夹加载图片数据
def load_dir_img(sorcedir):
print('正在读取图片...')
files = os.listdir(sorcedir)
data = np.zeros((files.__len__(),) + image.img_to_array(image.load_img(os.path.join(sorcedir, files[0]))).shape)
for i in range(files.__len__()):
data[i] = image.img_to_array(image.load_img(os.path.join(sorcedir, files[i]))) / 127.5 - 1
return data
# ************************** 训练
"""
gdrate:额外的生成器训练比率(判别器50%额外训练0次,100%额外训练gdrate次)
save_interval:保存间隔(steap)
"""
def run(epochs=100, batch_size=128, save_interval=100, gdrate=3, save_dir='.\\gan_image', history=None):
last_time = time.clock()
start_epoch = 0
if history is None:
history = []
else:
start_epoch = int(history[-1][0])
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
for step in range(x.shape[0] // batch_size):
# 按q终止
while msvcrt.kbhit():
char = ord(msvcrt.getch())
if char == 113:
return history
g_loss = -1
# 训练判别器
imgs = x[step * batch_size:step * batch_size + batch_size]
noise = np.random.normal(0, 1, (batch_size, latent_dim))
gen_imgs = generator.predict(noise)
d_loss_real = discriminator.train_on_batch(imgs, valid)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 训练生成器(动态训练比例)
for i in range(1 + int(gdrate * np.maximum(d_loss[1] - .5, 0) * 2)):
noise = np.random.normal(0, 1, (batch_size, latent_dim))
g_loss = combined.train_on_batch(noise, valid)
# Log
if step % save_interval == 0:
print(
"%d:%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch+start_epoch, step, d_loss[0], 100 * d_loss[1], g_loss))
history.append([epoch+start_epoch, step, d_loss[0], 100 * d_loss[1], g_loss])
save('.\\')
# 保存生成的图像
img = image.array_to_img(gen_imgs[0] * 127 + 127., scale=False)
img.save(os.path.join(save_dir, 'train_' + str(epoch+start_epoch) + '_' + str(step) + '.png'))
# 保存真实图像,以便进行比较
# img = image.array_to_img(imgs[0] * 127 + 127., scale=False)
# img.save(os.path.join(save_dir, 'real_' + str(epoch+start_epoch) + '_' + str(step) + '.png'))
# 计时
print('epoch run %d s, total run %d s' % (time.clock() - last_time, time.clock()))
last_time = time.clock()
save('.\\')
return history
# ************************** 生成
def generate(generator, save_dir=r'gan_image', num=100):
noise = np.random.normal(0, 1, (num, K.int_shape(generator.layers[0].input)[1]))
gen_imgs = generator.predict(noise)
for i in range(gen_imgs.shape[0]):
img = image.array_to_img(gen_imgs[i] * 127 + 127., scale=False)
img.save(os.path.join(save_dir, 'generated_' + str(i) + '.png'))
def plot_history():
h = np.array(history)
plt.scatter(h[:,0], h[:,3])
plt.show()
# ************************** 中途保存
def save(folder):
combined.save(os.path.join(folder, 'gan.h5'))
generator.save(os.path.join(folder, 'gan_g.h5'))
discriminator.save(os.path.join(folder, 'gan_d.h5'))
np.save(os.path.join(folder, 'history.npy'), history)
def load(folder):
history = np.load(os.path.join(folder, 'history.npy')).tolist()
generator = models.load_model(os.path.join(folder, 'gan_g.h5'))
discriminator = models.load_model(os.path.join(folder, 'gan_d.h5'))
discriminator.trainable = False
input_noise = models.Input(shape=(latent_dim,))
combined = models.Model(input_noise, discriminator(generator(input_noise)))
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
return history, generator, discriminator, combined
# ************************** Load Data
# 数据来源:https://drive.google.com/drive/folders/1mCsY5LEsgCnc0Txv0rpAUhKVPWVkbw5I?usp=sharing
# x = load_dir_img(r'C:\dataset\faces3m96')
print('正在加载数据')
x = np.load(r'C:\dataset\faces5m96.npy')
# ************************** 建模
# 对判别器进行构建和编译
discriminator = build_discriminator()
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
# 对生成器进行构造
generator = build_generator()
# 构造对抗模型
# 总体模型只对生成器进行训练
discriminator.trainable = False
input_noise = models.Input(shape=(latent_dim,))
combined = models.Model(input_noise, discriminator(generator(input_noise)))
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
# ************************** 运行
history = run()
# 从断点开始训练
# history, generator, discriminator, combined=load(r'C:\temp\DCGAN')
# history = run(history=history)