Stream(一)入门实战
像 Stream 这种 Fluent API,虽然不好调试,但是用着爽啊,我找了下我写的最长的应该就是这个了(希望以后有机会能写出更长的):
List<String> list = Stream.of(rsheet.getColumn(2)).skip(2).map(cell -> StringUtils.trim(cell.getContents())).collect(Collectors.toList()).stream().collect(Collectors.toMap(e -> e, e -> 1, (v1, v2) -> v1 + v2)).entrySet().stream().filter(entry -> entry.getValue() > 1).map(Map.Entry::getKey).collect(Collectors.toList());
其实 Stream 内容还是比较多的,准备分为多篇文章进行学习总结。个人感觉主要可以分为两部分,一部分是 API,API 其实就是多写写,用熟练了就行,不会就 Google 一下,而且由于 Stream 与集合关联性很大,学习使用 Stream API 没有概念上的学习成本;还有一部分是原理和扩展部分,本人也是初学者,不敢说对原理有多么深刻的认识,只能说是一些学习和总结吧。
函数式接口
在网上找到了一段比较好的描述(链接见文末):
A functional interface is an interface that contains only one abstract method. They can have only one functionality to exhibit. From Java 8 onwards, lambda expressions can be used to represent the instance of a functional interface. A functional interface can have any number of default methods. Runnable, ActionListener, Comparable are some of the examples of functional interfaces.
函数式接口一般会使用 @FunctionalInterface 声明,这个注解没有特殊的功能,主要是在编译期进行检查。Java 8 也内置了很多函数式接口,在网上看到一篇文章对此进行了总结(链接见文末):
| 函数式接口 | 参数类型 | 返回类型 | 描述 |
|---|---|---|---|
Supplier |
无 | T | 接收一个T类型的值 |
Consumer |
T | 无 | 处理一个T类型的值 |
BiConsumer |
T,U | 无 | 处理T类型和U类型的值 |
Predicate |
T | boolean | 处理T类型的值,并返回true或者false. |
ToIntFunction |
T | int | 处理T类型的值,并返回int值 |
ToLongFunction |
T | long | 处理T类型的值,并返回long值 |
ToDoubleFunction |
T | double | 处理T类型的值,并返回double值 |
Function |
T | R | 处理T类型的值,并返回R类型值 |
BiFunction |
T,U | R | 处理T类型和U类型的值,并返回R类型值 |
BiFunction |
T,U | R | 处理T类型和U类型的值,并返回R类型值 |
UnaryOperator |
T | T | 处理T类型值,并返回T类型值, |
BinaryOperator |
T,T | T | 处理T类型值,并返回T类型值 |
在介绍 Stream 之前为什么要提一下函数式接口呢,因为 Stream 是用函数式编程方式对集合(Collection)对象进行了功能上的增强,某种程度上也可以把它们看成遍历数据集的高级迭代器。
API 实战
Stream 的 API 还不少,这里就以我写的那个比较长的 API 为例进行简单的说明,我讲上面的代码略微修改了一下:
public static void main(String[] args) {
String[] arr = {"-1", "-2", "1 ", "2", "1", "3", "4", " 3", "5", "6", "5"};
List<String> list = Stream.of(arr)
.skip(2)
.map(StringUtils::trim)
.collect(Collectors.toList())
.stream().collect(Collectors.toMap(e -> e, e -> 1, (v1, v2) -> v1 + v2))
.entrySet().stream()
.filter(entry -> entry.getValue() > 1)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
System.out.println(list);
}
这里再截一张图,因为 IDEA 可以将每个函数返回类型展示出来:
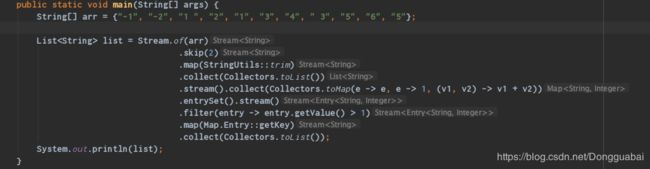
创建流
在上述代码中使用的是 Stream.of() 创建的流,可以看到这个函数会返回一个 Stream,而且是一个静态方法,会创建一个 Stream。这个方法会接受任意给定数量的参数,比如我上面的例子中入参就是一个数组。
平时用的比较多的就是直接通过集合创建流,Java 8 在 Collection 中增加了一个 default 方法:
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
Stream 中还有一个 parallel() 方法(Collection 中是 parallelStream() 方法),这个方法可以将流转换为并行流,并行相关的特点会放在后面的文章中。
创建流还有两种比较特殊的方式:根据文件创建流、创建无限流。
在 Files 中有一个静态方法 lines(),返回的 Stream 中包含了文件的每一行数据,比如文件内容为:
1张三
2李四
3王五
4赵六
5周期
@Test
public void test2() {
//根据文件路径创建流
try (Stream<String> lines = Files.lines(Paths.get("/Users/dongguabai/Desktop/temp/520.txt"))) {
lines.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
}
输出结果:
1张三
2李四
3王五
4赵六
5周期
Stream 中有两个静态方法可以生成所谓的无限流:iterate() 和 generate()。无限流就意味着是没有限制的,所以一般需要结合 limit() 一起用:
@Test
public void test39(){
Stream.iterate(1,a->a+1).limit(10).forEach(System.out::println);
}
输出结果:
1
2
3
4
5
6
7
8
9
10
skip(long n)
这个方法就是跳过前 n 个元素的意思,比如:
@Test
public void test39(){
IntStream.range(1,11).boxed().skip(5).forEach(System.out::print);
System.out.println();
IntStream.range(1,11).boxed().forEach(System.out::print);
}
输出结果:
678910
12345678910
map(Function mapper)
这个方法的参数是函数式接口 Function,返回一个经过 Function 转化后的结果的 Stream,直接看例子吧:
@Test
public void test3(){
IntStream.range(1,11).forEach(System.out::print);
System.out.println();
//将 1-10 每个数字加 1
IntStream.range(1,11).map(a->a+1).forEach(System.out::print);
}
输出结果:
12345678910
234567891011
R collect(Collector collector)
示例中使用的这个方法入参是 Collector 接口,关于 Collector 接口会在后面的文章中详细介绍。
先看一个简单例子:
@Test
public void test4(){
//获取所有 User 的用户名集合
List<User> list = Lists.newArrayList(new User("1","张三"),new User("2","李四"),new User("3","王五"));
List<String> collect = list.stream().map(User::getUsername).collect(Collectors.toList());
collect.forEach(System.out::println);
}
运行结果:
张三
李四
王五
还有一个 Collector.toMap 方法,可以将结果转化为 Map,有三个重载方法:
![]()
先看一个简单的例子:
@Test
public void test6(){
List<User> list = Lists.newArrayList(new User("1","张三"),new User("2","李四"),new User("3","王五"));
//获取一个 Map,key 是用户的 id,value 是用户
Map<String, User> map = list.stream().collect(Collectors.toMap(User::getId, Function.identity()));
map.forEach((k,v)-> System.out.println(String.format("k:%s,v:%s",k,v)));
}
k:1,v:User(id=1, username=张三)
k:2,v:User(id=2, username=李四)
k:3,v:User(id=3, username=王五)
但是这个方法有很多比较坑的地方,比如当出现 key 相同的时候:
@Test
public void test7(){
//有两个用户的 id 是相同的
List<User> list = Lists.newArrayList(new User("1","张三"),new User("1","李四"),new User("3","王五"));
//获取一个 Map,key 是用户的 id,value 是用户
Map<String, User> map = list.stream().collect(Collectors.toMap(User::getId, Function.identity()));
map.forEach((k,v)-> System.out.println(String.format("k:%s,v:%s",k,v)));
}
运行结果:
java.lang.IllegalStateException: Duplicate key User(id=1, username=张三)
at java.util.stream.Collectors.lambda$throwingMerger$0(Collectors.java:133)
at java.util.HashMap.merge(HashMap.java:1254)
...
...
其实原因也很简单,这里的 toMap 方法本质是调用的另一个重载方法:
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}
mergeFunction 参数的作用就是当 key 相同的时候会执行相应的操作,而这里传入的 mergeFunction 是:
private static <T> BinaryOperator<T> throwingMerger() {
return (u,v) -> { throw new IllegalStateException(String.format("Duplicate key %s", u)); };
}
所以处理方式就很简单了,我们传入符合自己需求的 mergeFunction 即可:
@Test
public void test6(){
List<User> list = Lists.newArrayList(new User("1","张三"),new User("1","李四"),new User("3","王五"));
//获取一个 Map,key 是用户的 id,value 是用户,id 相同,后面覆盖前面的
Map<String, User> map = list.stream().collect(Collectors.toMap(User::getId, Function.identity(), (user, user2) -> user2));
map.forEach((k,v)-> System.out.println(String.format("k:%s,v:%s",k,v)));
}
运行结果:
k:1,v:User(id=1, username=李四)
k:3,v:User(id=3, username=王五)
还有一个比较坑的地方就是当 value 为 null 的时候:
@Test
public void test5(){
List<User> list = Lists.newArrayList(new User("1","张三"),new User("2",null),new User("3","王五"));
//获取一个 Map,key 是用户的 id,value 是用户的名称(这里有一个User对象的username是null),如果 key 相同,后面的覆盖前面的
Map<String, String> map = list.stream().collect(Collectors.toMap(User::getId, User::getUsername));
map.forEach((k,v)-> System.out.println(String.format("k:%s,v:%s",k,v)));
}
java.lang.NullPointerException
at java.util.HashMap.merge(HashMap.java:1225)
...
...
原因也很简单,java.util.HashMap#merge 方法不允许 value 为 null:
@Override
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
if (value == null)
throw new NullPointerException();
...
...
}
解决方法有很多,这里提供一种方法。其实 Stream.collect 还有另外一个重载方法:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
第一个参数 supplier 就是说会返回一个我们所需要的 container,第二个参数 accumulator 就是将元素添加进 container 的具体实现,第三个 combiner 就是将组合多个 supplier,要注意的是第三个参数只有在使用并行流的时候才会调用,也很好理解,只有在并行的时候才会出现多个 supplier 的情况。所以当 key 为 null 的时候,可以使用这个方式:
@Test
public void test5(){
List list = Lists.newArrayList(new User("1","张三"),new User("2",null),new User("3","王五"));
//获取一个 Map,key 是用户的 id,value 是用户的名称(这里有一个User对象的username是null)
Map map = list.stream().collect(HashMap::new, (m, v) -> m.put(v.getId(), v.getUsername()), HashMap::putAll);
map.forEach((k,v)-> System.out.println(String.format("k:%s,v:%s",k,v)));
}
输出结果:
k:1,v:张三
k:2,v:null
k:3,v:王五
关于 combiner 可以简单测试一下:
@Test
public void test5(){
List<User> list = Lists.newArrayList(new User("1","张三"),new User("2",null),new User("3","王五"));
//获取一个 Map,key 是用户的 id,value 是用户的名称(这里有一个User对象的username是null)
Map<String, String> map = list.stream().collect(HashMap::new, (m, v) -> m.put(v.getId(), v.getUsername()), (stringStringHashMap, m) -> {
System.out.println("。。。。。。。");
stringStringHashMap.putAll(m);
});
map.forEach((k,v)-> System.out.println(String.format("k:%s,v:%s",k,v)));
Map<String, String> map2 = list.stream().parallel().collect(HashMap::new, (m, v) -> m.put(v.getId(), v.getUsername()), (stringStringHashMap, m) -> {
System.out.println("。。。parallel。。。。");
stringStringHashMap.putAll(m);
});
map2.forEach((k,v)-> System.out.println(String.format("k:%s,v:%s",k,v)));
}
发现使用并行流的时候才会调用 combiner。
filter(Predicate predicate)
这个方法也很好理解,入参是 Predicate,很明显就是过滤出符合要求的结果,看这个例子:
@Test
public void test8(){
List<User> list = Lists.newArrayList(new User("1","张三"),new User("2","李四"),new User("3","王五"));
//获取 id 大于 1 的 User
List<User> collect = list.stream().filter(user -> Integer.valueOf(
user.getId()
) > 1).collect(Collectors.toList());
System.out.println(collect);
}
运行结果:
[User(id=2, username=李四), User(id=3, username=王五)]
最后
本文主要是简单介绍了几个比较简单常用的 Stream API,其实这些 API 上手很简单,特别是理解了函数式接口的特点之后,后面会开始介绍 Stream 及与 Stream 相关的原理和扩展方面的内容,欢迎大家一起探讨学习。
References
- https://www.geeksforgeeks.org/functional-interfaces-java/
- https://cloud.tencent.com/developer/article/1347532
欢迎关注公众号
