Scala 从入门到入土之 Scala Actor
1, 什么是Scala Actor
Scala中的Actor能够实现并行编程的强大功能,它是基于事件模型的并发机制,Scala是运用消息(message)的发送、接收来实现多线程的, 而Actor正是实现消息传递的。
2, 传统java并发编程与Scala Actor编程的区别
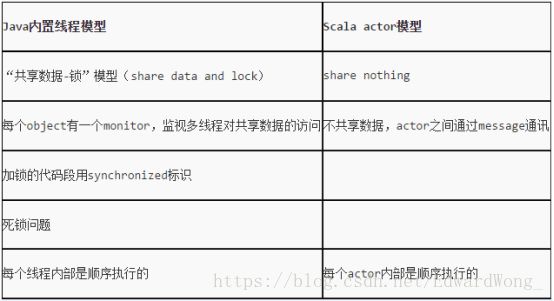
对于Java,我们都知道它的多线程实现需要对共享资源(变量、对象等)使用synchronized 关键字进行代码块同步、对象锁互斥等等。而且,常常一大块的try…catch语句块中加上wait方法、notify方法、notifyAll方法是让人很头疼的。原因就在于Java中多数使用的是可变状态的对象资源,对这些资源进行共享来实现多线程编程的话,控制好资源竞争与防止对象状态被意外修改是非常重要的,而对象状态的不变性也是较难以保证的。 而在Scala中,我们可以通过复制不可变状态的资源(即对象,Scala中一切都是对象,连函数、方法也是)的一个副本,再基于Actor的消息发送、接收机制进行并行编程。
3, Actor方法执行顺序
1.首先调用start()方法启动Actor
2.调用start()方法后其act()方法会被执行
3.向Actor发送消息
例如下面这个简单的例子
import scala.actors.Actor
object ActorDemo1 {
def main(args: Array[String]): Unit = {
// 启动Actor
MyActor1.start()
MyActor2.start()
}
}
/**
* 创建Actor
*/
object MyActor1 extends Actor{
override def act(): Unit = {
for (i <- 1 to 10){
println(s"actor1: $i")
Thread.sleep(1000)
}
}
}
object MyActor2 extends Actor{
override def act(): Unit = {
for (i <- 1 to 10){
println(s"actor2: $i")
Thread.sleep(1000)
}
}
}上面分别调用了两个单例对象的start()方法,他们的act()方法会被执行,相当于在java中开启了两个线程,线程的run()方法会被执行,
这两个Actor是并行执行的,act()方法中的for循环执行完成后actor程序就退出
4, 发送消息的方式
! 发送异步消息,没有返回值
!? 发送同步消息,等待返回值
!! 发送异步消息,返回值是Future[Any] (此时不对future做研究 , 只需要知道future相当于一个容器 , 是用来存储获取的同步操作结果的)
例如下面这个简单的例子
import scala.actors.{Actor, Future}
object ActorDemo2 extends Actor {
override def act(): Unit = {
while (true) {
// 用到了偏函数
receive {
case "start"
=> println("starting...")
case AsyncMsg(id, msg) => {
println(s"id: $id, msg: $msg")
sender ! ReplyMsg(3, "sucess")
}
case SyncMsg(id, msg) => {
println(s"id: $id, msg: $msg")
Thread.sleep(2000)
sender ! ReplyMsg(4, "success")
}
}
}
}
}
object ActorTest{
def main(args: Array[String]): Unit = {
val actor = ActorDemo2.start()
// 发送异步消息,没有返回值
// actor ! AsyncMsg(1, "yangmi is my goddess")
// println("异步消息,没有返回值")
// 发送同步消息,有返回值,会线程等待
// val content: Any = actor !? SyncMsg(2, "feifei is my right girl")
// println("同步消息发送完毕")
// println(content)
// 发送异步消息,有返回值,返回值是 Future[Any]
val reply: Future[Any] = actor !! AsyncMsg(3, "yanyan is my love")
Thread.sleep(1000)
if (reply.isSet) {
val applyMsg: Any = reply.apply()
println(applyMsg)
} else {
println("Nothing ...")
}
}
}
case class AsyncMsg(id: Int, msg: String)
case class ReplyMsg(id: Int, msg: String)
case class SyncMsg(id: Int, msg: String)在act()方法中加入了while (true) 循环,就可以不停的接收消息
发送start消息和stop的消息是异步的,但是Actor接收到消息执行的过程是同步的按顺序执行
此段代码while循环和receive的配合可以使用react复用线程的方式替换 , 效率会更高 , 但是反复执行消息处理 , react外层要用loop , 不能使用while
5, 最后 , 我们可以使用一个小项目作为总结
项目需求:
用actor并发编程写一个单机版的WorldCount,将多个文件作为输入,计算完成后将多个任务汇总,得到最终的结果
准备工作:
我们先准备3个文档文件 分别命名为a.txt , b.txt , c.txt 文档内容均为 Hello Tom格式 , 由空格切分
我们可以先对3个文档分别进行局部处理
对三个文档分别进行wordCount处理时的核心思路如下
1, 把数据进行切分 , 生成一个个单词,并把多个Array压平到一起
2, 把数据中多余的空格过滤掉
3, 把一个个单词生成元组: (word,1)
4, 以key进行分组
5, 聚合相同key的value , 只需要统计单词对应的List的长度就可以得到单词出现的个数
然后我们在对处理完成后的3个文档结果进行处理
下面是代码
import scala.actors.{Actor, Future}
import scala.collection.mutable.ArrayBuffer
import scala.io.Source
object ActorWordCount {
def main(args: Array[String]): Unit = {
// 用来存储每个文件的统计结果,类型为Future
val replys = new ArrayBuffer[Future[Any]]()
// 用来存储过滤后并从Future提取出来的数据
val filteredReplys = new ArrayBuffer[Map[String, Int]]()
val files = Array("c://testfile/a.txt", "c://testfile/b.txt", "c://testfile/c.txt")
for (file <- files) {
// 启动Actor
val task = new Task
task.start()
// 向actor发送file数据并接收Actor响应的聚合数据
val reply: Future[Any] = task !! SubmitTask(file)
// 把某个文件的结果数据追加到replys
replys += reply
}
while (replys.size > 0) {
// 因为是异步接收数据,有可能replys里有空值的Future,需要过滤掉
val dones: ArrayBuffer[Future[Any]] = replys.filter(_.isSet)
for (done <- dones) {
// 把Future里的数据取出来,放到一个Map里
val mapped: Map[String, Int] = done.apply().asInstanceOf[Map[String, Int]]
filteredReplys += mapped
replys -= done
}
}
// val res = filteredReplys.flatten.groupBy(_._1).mapValues(_.reduce((x,y) => (x._1, x._2 + y._2))).map(_._2)
// foldLeft: (z: B)(op: (B, A) => B): B
// val res = filteredReplys.flatten.groupBy(_._1).mapValues(_.foldLeft(0)(_ + _._2))
val res = filteredReplys.flatten.groupBy(_._1).mapValues(_.foldLeft(0)((x, y) => x + y._2))
println(res)
}
}
class Task extends Actor {
override def act(): Unit = {
while (true) {
receive {
case SubmitTask(file) => {
val linesIt: Iterator[String] = Source.fromFile(file).getLines()
val lines: List[String] = linesIt.toList
val words: List[String] = lines.flatMap(_.split(" "))
val tuples: List[(String, Int)] = words.map((_, 1))
val grouped: Map[String, List[(String, Int)]] = tuples.groupBy(_._1)
val sumed: Map[String, Int] = grouped.mapValues(_.size)
// 异步发送数据,没有返回值
sender ! sumed
}
}
}
}
}
case class SubmitTask(file: String)
此段代码中,完成对各个文档的局部处理后由 sender ! sumed方法发送结果到 reply中 , 再添加进replys中 , 经由空文件过滤处理后 , 将内容存至filteredReplys中 , 再进行总处理 , 此处可以使用 reduce方法 , foldLeft折叠对filteredReplys中map的value进行聚合