python正则表达式(re模块)
【Jupyter notebook】
正则表达式
- 正则表达式是用来简洁的表达一组字符串的表达式,它代表着那组字符串的特征。
- 正则表达式简洁、一言胜千言
- 编译: 将一组符合正则表达式语法的字符串转换为正则表达式特征
正则表达式语法由字符和操作符组成
- 正则表达式常用的操作符如下所示:
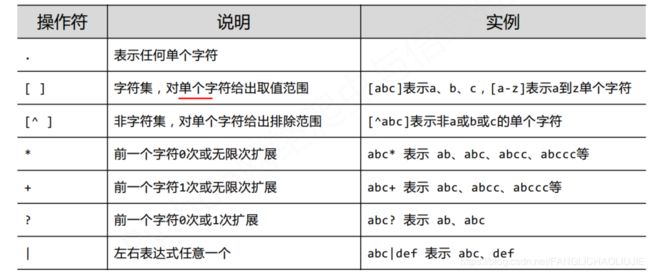
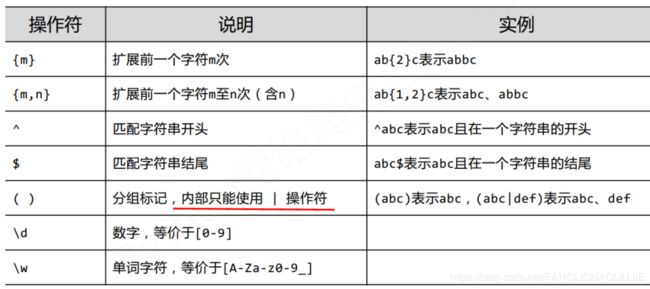
常用的表达式示例


re库的主要功能函数

1、re.search(pattern, string, flags=0)
- 在一个字符串中搜索匹配正则表达式的第一个位置返回match对象

import re
match = re.search(r'[1-9]\d{5}', 'BIT 100081')
if match:
print(match.group(0))
100081
2、re.match(pattern, string, flags=0)
- 从一个字符串的开始位置起匹配正则表达式返回match对象
match = re.match(r'[1-9]\d{5}', 'BIT 100081')
if match:
print(match.group(0))
else:
print("not found")
not found
match = re.match(r'[1-9]\d{5}', '100081 BIT')
if match:
print(match.group(0))
else:
print("not found")
100081
3、re.findall(pattern, string, flags=0)
- 搜索字符串,以列表的形式返回全部能够匹配的子串
ls = re.findall(r'[1-9]\d{5}','BIT100081 TSU100084 000008DUX')
ls
['100081', '100084']
4、re.split(pattern, string, maxsplit=0, flags=0)
- 将一个字符串按照正则表达式匹配结果进行分割返回列表类型
re.split(r'[1-9]\d{5}','BIT 100081 TSU 100084 000008DUX')
['BIT ', ' TSU ', ' 000008DUX']
re.split(r'[1-9]\d{5}','BIT100081 TSU100084 000008DUX', maxsplit=1)
['BIT', ' TSU100084 000008DUX']
5、finditer(pattern, string, flags=0)
- 搜索字符串,返回一个匹配结果的迭代对象,每个迭代元素是match对象
for m in re.finditer(r'[1-9]\d{5}','BIT100081 TSU100083'):
if m:
print(m.group(0))
else:
print('not found')
100081
100083
7、sub(pattern, repl, string, count, flags=0)
- 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串。
re.sub(r'[1-9]\d{5}', ':zipcode','BIT100081 TSU100084')
'BIT:zipcode TSU:zipcode'
re库的另一种等价用法
- 也可以先对匹配正则表达式进行编译,然后再使用。这样做的好处是可以重复使用。

pat = re.compile(r'[1-9]\d{5}')
pat.findall('BIT100081 TSU100083')
['100081', '100083']
for item in pat.finditer('BIT100081 TSU100083 100038UAB U100032AS'):
print(item.group(0))
100081
100083
100038
100032
pat.search('BIT100081 TSU100083 100038UAB U100032AS')
<_sre.SRE_Match object; span=(3, 9), match='100081'>
match对象
-
上文提到match对象,该对象主要有以下几个属性
-

-
match对象的方法

m = pat.search('BIT100081 TSU100083 100038UAB U100032AS')
m.string
'BIT100081 TSU100083 100038UAB U100032AS'
m.re
re.compile(r'[1-9]\d{5}', re.UNICODE)
m.start()
3
m.end()
9
m.span()
(3, 9)
re的贪婪匹配和最小匹配
- re 模块默认的是贪婪匹配
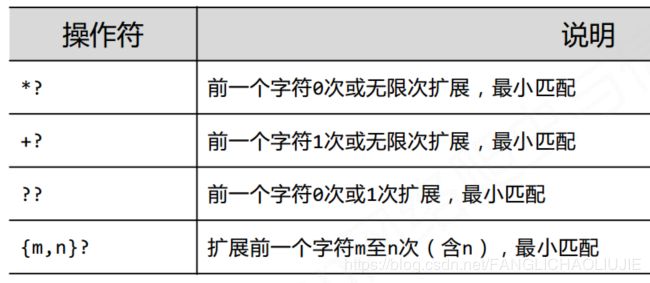
pat = re.compile(r'PY.*N')
m = pat.search("PYANBNCNDN")
m.group(0)
'PYANBNCNDN'
# 但是如果我们只想匹配最短的即“PYAN”,怎么办?
pat = re.compile(r'PY.*?N')
m = pat.search("PYANBNCNDN")
m.group(0)
'PYAN'
以下为re.py中的函数定义
match()函数
- 从字符串的开始匹配模式,如果匹配到,返回一个match对象;否则返回None
def match(pattern, string, flags=0):
"""Try to apply the pattern at the start of the string, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).match(string)
fullamtch()
- 对整个字符串进行模式匹配,如果匹配到,返回一个match对象,否则返回None
def fullmatch(pattern, string, flags=0):
"""Try to apply the pattern to all of the string, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).fullmatch(string)
search()
- 在一个字符串中搜索匹配正则表达式的第一个位置返回match对象
def search(pattern, string, flags=0):
"""Scan through string looking for a match to the pattern, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).search(string)
sub()
- 对string进行模式匹配,将匹配到的字符使用repl进行替换,返回替换后的字符串。其中count为匹配的次数
def sub(pattern, repl, string, count=0, flags=0):
"""Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used."""
return _compile(pattern, flags).sub(repl, string, count)
subn()
- 对string进行模式匹配,将匹配到的字符使用repl进行替换,返回一个元组(new_string, number)。new_string为替换后的字符串,number为实际替换的次数。其中count为匹配的次数
def subn(pattern, repl, string, count=0, flags=0):
"""Return a 2-tuple containing (new_string, number).
new_string is the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in the source
string by the replacement repl. number is the number of
substitutions that were made. repl can be either a string or a
callable; if a string, backslash escapes in it are processed.
If it is a callable, it's passed the match object and must
return a replacement string to be used."""
return _compile(pattern, flags).subn(repl, string, count)
split()
- 按照指定的模式对字符串进行分隔,返回一个分隔后的字符串组成的列表
def split(pattern, string, maxsplit=0, flags=0):
"""Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings. If
capturing parentheses are used in pattern, then the text of all
groups in the pattern are also returned as part of the resulting
list. If maxsplit is nonzero, at most maxsplit splits occur,
and the remainder of the string is returned as the final element
of the list."""
return _compile(pattern, flags).split(string, maxsplit)
findall()
- 在字符串中进行模式匹配,并将匹配到的结果以列表的形式返回
def findall(pattern, string, flags=0):
"""Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result."""
return _compile(pattern, flags).findall(string)
finditer()
- 返回一个迭代器
def finditer(pattern, string, flags=0):
"""Return an iterator over all non-overlapping matches in the
string. For each match, the iterator returns a match object.
Empty matches are included in the result."""
return _compile(pattern, flags).finditer(string)
compile()
- 编译一个字符串形式的正则表达式,返回一个pattern对象
def compile(pattern, flags=0):
"Compile a regular expression pattern, returning a pattern object."
return _compile(pattern, flags)
purge()
- 清除正则表达式的缓存
def purge():
"Clear the regular expression caches"
_cache.clear()
_compile_repl.cache_clear()