吴恩达视频学习课后作业(01.神经网络和深度学习--week2/assignment2_2)
最近从头开始学习深度学习,想借此记录学习过程用于日后复习或者回看,以下是个人见解,如有错误请见谅并指出,谢谢。
目的
Assignment2_2作业主要是引导新手从头开始建一个用逻辑回归分类器( classififier, LR)来识别图像中是否有猫。简单来说,逻辑回归是二值分类器,可以看作是仅含有一个神经元的单层神经网络。
主要步骤
- 读取数据集并做预处理
- 初始化参数(权重w、偏置b、迭代次数、学习速率learning_rate等)
- 计算cost function和其梯度值
- 优化网络,更新参数,最小化cost function的值
- 计算预测值与ground truth做比较,得出正确率
在这过程中,你需要定义几个方法{sigmoid_function()、initiolize_with_zeros()、propagation()、optimize()、predict()},最后将所有方法整合到model()中。
文件介绍
数据集:m个样本的训练集和n个样本的测试集,训练/测试集数据维数为(m,64,64,3)/(n,64,64,3),每个样本为3通道(RGB),分辨率64*64的彩色图像,图像被标记为cat(y=1)和non-cat(y=0)两种类型。每个像素值实际上是含有3个值的向量,值域为[0,255]
数据读取文件:lr_utils.py
调用该文件中的load_dataset()函数可获得输入、输出数据和类别(train_set_x_orig,train_set_y,test_set_x_orig,test_set_y, classes)
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
具体步骤
加载数据集,對图像做预处理:
将每张图像的维数[64,64,3]改为[64*64*3,1],那么输入数组的行代表样本数,列代表样本数据。一般预处理的方法是将数据进行归一化(将数据缩放到一个小的区间内,这样可以将数据转化为无量纲的纯数值,打破数据的单位限制,方便不同单位或量级的数据进行加权比较的操作),最简单的方法就是将每个像素值都除以255,使其落到[0,1]区间内
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
###preprocessing
###reshape images[x,x,3] in a numpy-array[x*x*3,1]
###each column represents a flattened image
m_train = train_set_x_orig.shape[0]
m_test = test_set_x_orig.shape[0]
num_px = train_set_x_orig.shape[1]
train_set_x_flatten = train_set_x_orig.reshape(m_train,-1).T ##equals to reshape(m_train, num_px*num_px*3)
test_set_x_flatten = test_set_x_orig.reshape(m_test,-1).T
##center and standardize the data
train_set_x = train_set_x_flatten / 255.
test_set_x = test_set_x_flatten / 255.
经预处理后得到的train_set_x,test_set_x便作为网络的输入数据。
构建逻辑回归分类器,定义相关函数:
首先先给出逻辑回归的定义式:任意输入![]() ,有
,有
![]()
![]()
其中nx表示特征数,![]() 表示当输入为x时,y =1的概率。上面说到,逻辑回归是二分类,所以y的取值为{0,1}。
表示当输入为x时,y =1的概率。上面说到,逻辑回归是二分类,所以y的取值为{0,1}。![]() 的计算公式如下:
的计算公式如下:
![]()
![]()
即用sigmoid方程计算,也可说是激励函数(Activation function):
![]()
![]()
当已知{(![]() ),.....,(
),.....,(![]() )}(m是样本数目),我们希望的是
)}(m是样本数目),我们希望的是![]() ,因此我们需要计算损失函数的值,并最小化损失函数。这里面有两个概念,Lost(error) function 和Cost function。
,因此我们需要计算损失函数的值,并最小化损失函数。这里面有两个概念,Lost(error) function 和Cost function。
Lost function 是定义在单个样本上的函数:
![]()
![]()
Cost function 是定义在整个样本集上的函数,也可以看作是Lost function的均值:
![J(w,b)=\frac{1}{m}\sum_{i}^{m}L(\hat{y}^{i},y^{i})=-\frac{1}{m}\sum_{i}^{m}[y^{i}log\hat{y^{i}}+(1-y^{i})log(1-\hat{y^{i}})]](http://img.e-com-net.com/image/info8/9a4c0067ebb9404f995e19ff750dedec.gif)
![]()
归根结底要做的就是找出最佳参数w、b的值,来使J(或者cost)达到最小。
那么怎么找到最佳参数呢?用Back Propagation来计算w和b的值,再用Front Propagation计算cost的值,然后重复此过程直至迭代停止。而计算w,b的值就需要用到梯度下降法了。我们根据式(5)分别求出w和b的偏导数,每次迭代中更新w和b的值:
![]()
![]()
![]()
其中![]() 是学习速率,用来控制参数下降的快慢或者说收敛速度,在编写程序的过程中,
是学习速率,用来控制参数下降的快慢或者说收敛速度,在编写程序的过程中,![]() 初始化为0.05,设置每一次迭代学习速率都降为其原本的99.9%,使当cost越靠近最小值时,w和b走的越小步(更新变化越小),这样可避免cost收敛过快反而跳过最小值。
初始化为0.05,设置每一次迭代学习速率都降为其原本的99.9%,使当cost越靠近最小值时,w和b走的越小步(更新变化越小),这样可避免cost收敛过快反而跳过最小值。
那么从以上分析我们就可以来写代码了,这里提醒几点,一般输入特征都不止一个,所以当更新多个w值时,应该向量化w,一次更新便可用一句代码完成,这样可以加快程序的运行速度。同时,我将每次迭代算出的cost依次比较,并保存使cost达到最小值的参数w和b:
##definition of sigmoid function
def sigmoid_function(z):
s = 1 / (1 + np.exp(-z))
return s
##initializing parameters w&b, create a vector of zeros of shape((dim,1),type = float64)
def initiolize_with_zeros(dim):
w = np.zeros((dim,1))
b = 0
return w, b
##propagation
def propagation(w, b, x ,y):
##forward propagation
y_hat = sigmoid_function(np.dot(w.T,x) + b)
y_diff = y_hat - y
L = -(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat)) ##Loss function
cost = np.sum(L) / x.shape[1]
##backward propagation
dw = np.dot(x, y_diff.T) / x.shape[1]
db = np.sum(y_diff) / x.shape[1]
assert(dw.shape == w.shape)
assert(db.dtype == float)
cost = np.squeeze(cost)
assert(cost.shape == ())
##save as dictionary
grads = {"dw" : dw, "db" : db}
return grads, cost
##optimization, learn w&b by minimizing the cost
##update parameters using gradient descent
def optimize(w, b, x, y, num_iterations, learning_rate):
costs = []
best_cost = np.array([1.])
best_params = {}
decay = 0.999 ##decay of learning_rate
for i in range(num_iterations):
grads, cost = propagation(w, b ,x ,y)
dw = grads["dw"]
db = grads["db"]
##update params
w = w - learning_rate * dw
b = b - learning_rate * db
learning_rate *= decay
##record cost every 100 iteration
if i % 100 == 0:
costs.append(cost)
# print "cost after iteration %d: %+f" %(i, cost)
# print "learning_rate:%f"%learning_rate
##when the data_set is big enough
##save the params at the smallest cost
if cost < best_cost:
best_cost = cost
best_params["w"] = w
best_params["b"] = b
print "best cost : %f"%best_cost
params = {"w" : w, "b" : b, "learning_rate" : learning_rate, "best_w" : best_params["w"], \
"best_b" : best_params["b"]}
grads = {"dw" : dw , "db" : db}
return params, grads, costs我们还需定义预测值计算函数,并判断![]() 时,预测为1(cat);
时,预测为1(cat);![]() 时,预测为0(non-cat):
时,预测为0(non-cat):
##prediction
##step1:calculate y_hat
##step2:1(y_hat>0.5),0(y_hat<=0.5)
def predict(w, b, x):
y_hat = sigmoid_function(np.dot(w.T,x) + b)
assert(y_hat.shape[1] == x.shape[1])
y_pred = np.zeros((1,y_hat.shape[1]))
for i in range(y_hat.shape[1]):
if y_hat[:,i] <= 0.5:
y_pred[:,i] = 0
else:
y_pred[:,i] = 1
return y_pred
将函数包装起来,计算正确率来评估识别效果:
我用最后一次迭代时的参数与最佳参数分别来计算正确值,并做了对比。得到的结果是两者的正确率完全一致,没有不同,我认为应该是数据集小、识别难度小的原因,所以即时不需要用最佳参数也可以达到高识别率的效果:
##(4)merge all functions into a model
def model(x_train, y_train, x_test, y_test, num_iterations = 2000, \
learning_rate = 0.05):
features_num = x_train.shape[0]
w, b = initiolize_with_zeros(features_num)
params, grads, costs = optimize(w, b, x_train, y_train, \
num_iterations , learning_rate)
w, b, learning_rate = params["w"],params["b"],params["learning_rate"]
y_pred_train = predict(w, b, x_train)
y_pred_test = predict(w, b, x_test)
accuracy_train = 100 - np.mean(np.abs(y_pred_train - y_train) * 100)
accuracy_test = 100 - np.mean(np.abs(y_pred_test - y_test) * 100)
##predict y_hat with best_params
best_w, best_b = params["best_w"], params["best_b"]
best_y_pred_train = predict(best_w, best_b, x_train)
best_y_pred_test = predict(best_w, best_b, x_test)
best_accuracy_train = 100 - np.mean(np.abs(best_y_pred_train - y_train) * 100)
best_accuracy_test = 100 - np.mean(np.abs(best_y_pred_test - y_test) * 100)
##comparison between last w&b and best w&b
print "learning_rate : %f"%learning_rate
print "train accuracy -- %f%% : %f%%"%(accuracy_train,best_accuracy_train)
print "test accuracy -- %f%% : %f%%"%(accuracy_test, best_accuracy_test)
result = {"costs" : costs, "y_pred_test" : y_pred_test, \
"y_pred_train" : y_pred_train, "w" : w, "b" : b, \
"learning_rate" : learning_rate, "num_iterations" : num_iterations}
return result
结果
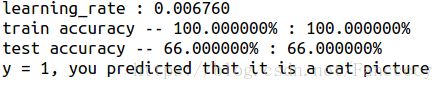

总结
- 预处理很重要,不同的情况选择哪种预处理方法会造成不同的结果,此实验中我试了试计算数据集的2范数来进行归一化,但结果不尽人意。
- 定义函数,构建神经网络
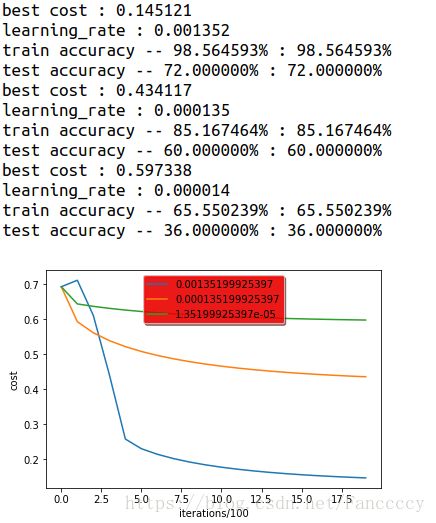
- 选择不同的学习速率也会對结果产生不同的效果,当分别用{0.1, 0.01, 0.001}来训练数据集时,得到的结果如下:
源代码可在此处下载:https://github.com/FancccyRay/Cat-images-recognization-using-logistic-regression.git