DualGAN
ICCV 2017 《DualGAN:Unsupervised Dual Learning for Image-to-Image Translation》
github

这篇论文和前面看过的《Learning to Discover Cross-Domain Relations with Generative Adversarial Networks》(参见:https://blog.csdn.net/Forlogen/article/details/89003879) 和《Image-to-Image Translation with Conditional Adversarial Networks》(参见:https://blog.csdn.net/Forlogen/article/details/89045651) 中的内容基本上是相近的。作者也是提出了一种DualGAN的模型,在没有标签数据的前提下,实现在两个不同的域之间的图像转换。整体的算法思想和DiscoGAN、CycleGAN是一致的,并没有什么不同之处,只是名字不一样~~
算法
所以下面主要介绍一下这篇论文的某些好的地方,其余和上面提到过的两篇论文相同的地方就不赘述了。
先看下它的模型架构:
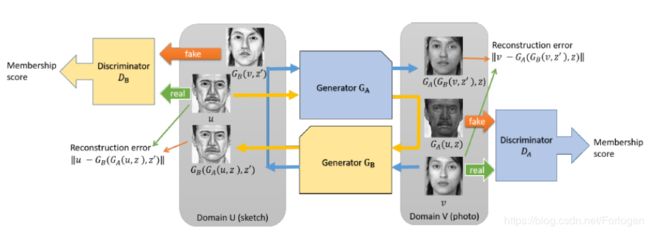
这里也是两个生成器和两个判别器,计算判别损失和重构损失。不同之处在于他这里使用的是WGAN中的损失函数Wasseratein loss,而不是标准GAN中使用的交叉熵,它的优点如下:
- 生成模型的收敛性好
- 生成的样本质量高
- 优化过程稳定性好
- 任何地方都是可微的,方便求梯度
因此 D A D_{A} DA 和 D B D_{B} DB 的损失函数定义如下:
l A d ( u , v ) = D A ( G A ( u , z ) ) − D A ( v ) l B d ( u , v ) = D B ( G B ( v , z ′ ) ) − D B ( u ) l_{A}^d(u,v) = D_{A}(G_{A}(u,z))-D_{A}(v) \\ l_{B}^d(u,v) = D_{B}(G_{B}(v,z'))-D_{B}(u) lAd(u,v)=DA(GA(u,z))−DA(v)lBd(u,v)=DB(GB(v,z′))−DB(u)
整体损失为:
l g ( u , v ) = λ U ∣ ∣ u − G B ( G A ( u , z ) , z ′ ) ∣ ∣ + λ V ∣ ∣ u − G A ( G B ( v , z ′ ) , z ) ∣ ∣ − D B ( G B ( v , z ′ ) ) − D A ( G A ( u , z ) ) l^g(u,v)=\lambda_{U}||u-G_{B}(G_{A}(u,z),z')||+\lambda_{V}||u-G_{A}(G_{B}(v,z'),z)||-D_{B}(G_{B}(v,z'))-D_{A}(G_{A}(u,z)) lg(u,v)=λU∣∣u−GB(GA(u,z),z′)∣∣+λV∣∣u−GA(GB(v,z′),z)∣∣−DB(GB(v,z′))−DA(GA(u,z))
其中 λ U \lambda_{U} λU 和 λ V \lambda_{V} λV 是两个常参数,取值范围为 [ 100.0 , 1 , 000.0 ] [100.0,1,000.0] [100.0,1,000.0] ,同时作者提出,如果U中包含自然的图像,而V中没有时,要使用的 λ U \lambda_{U} λU 小于 λ V \lambda_{V} λV 。
网络架构和《Image-to-Image Translation with Conditional Adversarial Networks》中的一样,这样既可以抓住图像局部高频的信息,也可以通过重构损失抓住全局的、低频的信息。
算法伪代码如下:

训练的过程和WGAN一样,使用小批次随机梯度下降,并使用RMSProp优化器(有关梯度下降的相关优化方法可参见:https://blog.csdn.net/Forlogen/article/details/88778770) ;D的训练轮次是2-4;批大小为1-4;剪裁系数 c c c 取自 [ 0.01 , 0.1 ] [0.01,0.1] [0.01,0.1] 。其中 c l i p ( ω A , − c , c ) , c l i p ( ω B , − c , c ) clip(\omega_{A},-c,c),clip(\omega_{B},-c,c) clip(ωA,−c,c),clip(ωB,−c,c) 这一步的含义待下一篇WGAN在了解。
实验部分
通过在不同的多个数据及上进行试验,比较DualGAN、GAN 和CGAN的效果差异,评估手段和
《Image-to-Image Translation with Conditional Adversarial Networks》同样相同。通过多次试验证明,DualGAN在大多数的场景下,效果都优于GAN和CGAN,下面给出几张结果图:
白天和黑夜的转换

照片和素描图的转换

绘画风格的转变

更多的实验结果可见原论文。
但是在图像分割上,DualGAN的效果要差于CGAN,在FACDES->LABEL和AERIAL->MAP两个数据集上都是如此。结果如下:
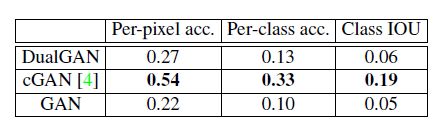
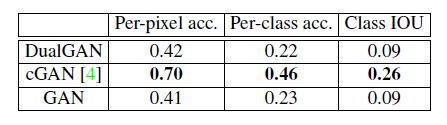
作者认为,可能是因为训练集中没有图像的对应信息,很难从中推断出合适的标记。所以最后作者提出能否在开始阶段往训练集中加一小部分带标签的数据来缓解这个问题,具体的工作并没有阐述。
此外在定性评估部分作者提出,DualGAN可能会将像素映射到错误的标签,或将标签映射到错误的纹理/颜色上,这也是一个急需解决的问题。