Python3网络爬虫:爬取漫画
那个网站漫画爬不到了,等有时间换个网站爬。
1、前言
本文使用了requests、bs4、os库与自动化测试工具Selenium。
Selenium安装详情请看
https://germey.gitbooks.io/python3webspider/content/1.2.2-Selenium%E7%9A%84%E5%AE%89%E8%A3%85.html
2、 问题分析
URL: http://www.gugumh.com/manhua/200/
我们先看一下每一章的url。
![]()
再到主页看一下源代码,发现只要将主页的URL与li标签中的路径连接起来便可得到每一章的URL。
下面是爬取li标签中每一个路径的代码。
import requests
from bs4 import BeautifulSoup
def Each_chapter():
url = 'http://www.gugumh.com/manhua/200/'
response = requests.get(url)
response.encoding = 'utf-8'
sel = BeautifulSoup(response.text, 'lxml')
total_html = sel.find('div', id='play_0')
total_chapter = []
for i in total_html.find_all('li'):
href = i.a['href']
every_url = 'http://www.gugumh.com' + href
total_chapter.append(every_url)
print(total_chapter)
if __name__ == '__main__':
Each_chapter()
然后再爬取每一章的页数
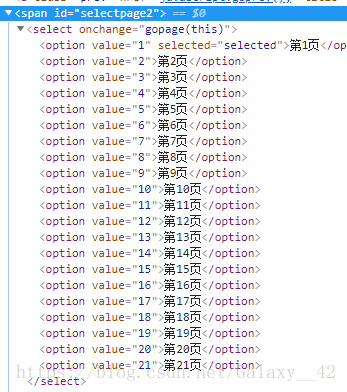
使用requests请求到的HTML发现没有页数
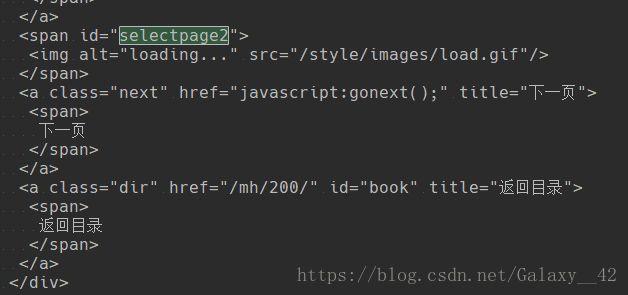
之前用bs4找了大半天页数一直都找不到,才发现每一章的页面是用js渲染的。
接下来我们可以使用selenium来获取页面源代码
Selenium使用详细内容查看官方文档:http://selenium-python.readthedocs.io/index.html
from selenium import webdriver
url = 'http://www.gugumh.com/manhua/200/697280.html'
browers = webdriver.Chrome()
browers.get(url)
html = browers.page_source
print(html)
然后我们把获取到的网页源代码放入BeautifulSoup中解析,并找到每一章的页数。
soups = BeautifulSoup(html, 'lxml')
soup = soups.find('span', id="selectpage2")
pages = soup.find_all('option')
every_page = []
for page in pages:
every_page.append(page.get_text())
print(len(every_page))
browers.close() # 获取源代码之后把开出了的网页关了3、整合代码
整合下代码就可以得到整部漫画所有页面的URL了
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import os
def headers(referer):
headers = {
'Host': 'www.gugumh.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
'Referer': '{}'.format(referer)
}
return headers
def Each_chapter():
url = 'http://www.gugumh.com/manhua/200/'
response = requests.get(url, headers(url))
response.encoding = 'utf-8'
sel = BeautifulSoup(response.text, 'lxml')
total_html = sel.find('div', id='play_0')
total_chapter = []
for i in total_html.find_all('li'):
total_title = i.get_text() #找到每一章的名字
href = i.a['href']
total_chapter.append(href)
# 创造存放图片的文件夹
dirName = u"{}".format(total_title)
os.mkdir(dirName)
return total_chapter
def Each_page(url):
every_page_url = 'http://www.gugumh.com{}'.format(url)
html = main(every_page_url)
# print(browers.page_source)
# 页数放在js中,只能使用selenium
soups = BeautifulSoup(html, 'lxml')
soup = soups.find('span', id="selectpage2")
pages = soup.find_all('option')
every_page = []
for page in pages:
every_page.append(page.get_text())
return len(every_page)
#browers.close()
def main(whole_url):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browers = webdriver.Chrome(chrome_options=chrome_options)
# 上面三行代码表示可以无界面爬取
browers.get(whole_url)
html = browers.page_source
return html
if __name__ == '__main__':
for i in Each_chapter():
#print(i)
each_page = Each_page(i)
for a in range(1, each_page + 1):
page = a
whole_url = 'http://www.gugumh.com' + i + '?page=' + str(a)
print(whole_url)
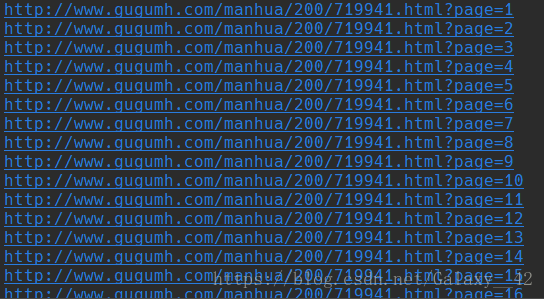
4、下载图片
import requests, os
from bs4 import BeautifulSoup
from selenium import webdriver
def img_headers(referer):
headers = {
'Host': 'img.manhuaba.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
'Referer': '{}'.format(referer)
}
return headers
def main(whole_url):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browers = webdriver.Chrome(chrome_options=chrome_options)
# 上面三行代码表示可以无界面爬取
browers.get(whole_url)
html = browers.page_source
return html
def get_image(page):
url = 'http://www.gugumh.com/manhua/200/697289.html?page={}'.format(page)
html = main(url)
soups = BeautifulSoup(html, 'lxml')
soup = soups.select('#viewimg')[0]
title = soups.find('h1').get_text()# 找到标题的字符串
Num = -4
if page >= 10: # 当第10页时,字符串就会增长一个长度
Num = Num - 1
dirName = title[4:Num] # 章节名称
src = soup['src']# 图片链接
filename = '%s\\%s\\第%d页.jpg' % (os.path.abspath('.'), dirName, page)
# os.path.abspath('.')表示返回当前文件夹在磁盘中的路径
with open(filename, "wb+") as jpg:
jpg.write(requests.get(src, img_headers(src)).content)
download = u'开始下载镇魂街:%s的第%d页' % (dirName, page)
return download
if __name__ == '__main__':
for i in range(1, 29):
a = get_image(i)
print(a)
5、最终代码
import requests, os
from bs4 import BeautifulSoup
from selenium import webdriver
def headers(referer):
headers = {
'Host': 'www.gugumh.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
'Referer': '{}'.format(referer)
}
return headers
def img_headers(referer):
headers = {
'Host': 'img.manhuaba.com',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
'Referer': '{}'.format(referer)
}
return headers
def Each_chapter():
url = 'http://www.gugumh.com/manhua/200/'
response = requests.get(url, headers(url))
response.encoding = 'utf-8'
sel = BeautifulSoup(response.text, 'lxml')
total_html = sel.find('div', id='play_0')
total_chapter = []
for i in total_html.find_all('li'):
total_title = i.get_text()
href = i.a['href']
total_chapter.append(href)
# 创造存放图片的文件夹
dirName = u"{}".format(total_title)
os.mkdir(dirName)
return total_chapter
def Each_page(url):
every_page_url = 'http://www.gugumh.com{}'.format(url)
html = main(every_page_url)
# 页数放在js中,只能使用selenium
soups = BeautifulSoup(html, 'lxml')
soup = soups.find('span', id="selectpage2")
pages = soup.find_all('option')
every_page = []
for page in pages:
every_page.append(page.get_text())
return len(every_page)
def get_image(html, page):
try:
soups = BeautifulSoup(html, 'lxml')
soup = soups.select('#viewimg')[0]
title = soups.find('h1').get_text()
Num = -4
if page >= 10: # 当第10页时,字符串就会增长一个长度
Num = Num - 1
dirName = title[4:Num]
src = soup['src']
#return src, dirName,
filename = '%s/%s/第%s页.jpg' % (os.path.abspath('.'), dirName, page) # 设置照片的路径
# os.path.abspath('.')表示返回当前文件夹在磁盘中的路径
with open(filename, "wb+") as jpg:
jpg.write(requests.get(src, headers=img_headers(src)).content)
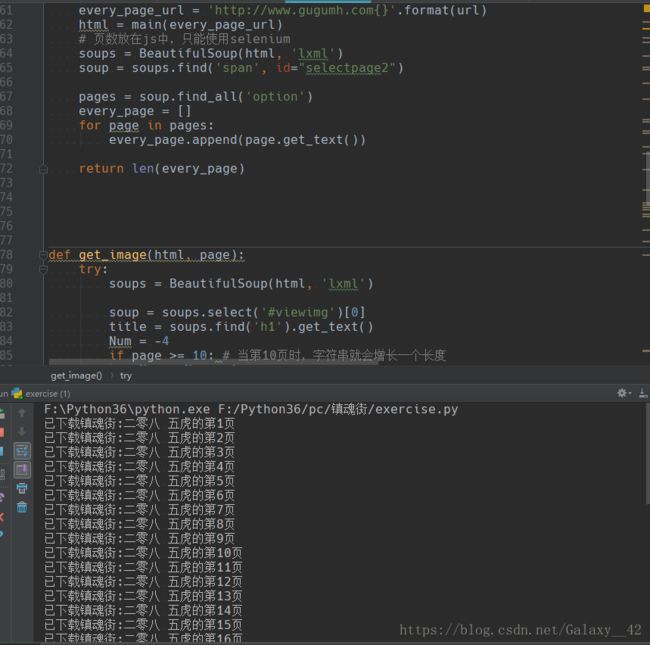
download = u'已下载镇魂街:%s的第%s页' % (dirName, page)
return download
except:
pass
def main(whole_url):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
# 上面三行代码表示可以无界面爬取
browser.get(whole_url)
html = browser.page_source
return html
if __name__ == '__main__':
for i in Each_chapter():
each_page = Each_page(i)
for a in range(1, each_page + 1):
page = a
whole_url = 'http://www.gugumh.com' + i + '?page=' + str(a)
html = main(whole_url)
print(get_image(html, page))
运行结果:
6、总结
这样爬取虽然可以爬到内容,但是运行是在太慢了,爬一晚上都不见得能爬完,加上多进程可能比较好。