《Human Semantic Parsing for Person Re-identification》论文阅读之SPReID
论文地址
GitHub代码
Introduction
目前大部分的Person ReID方法都开始集中于提取更加具有表征能力的局部特征辅助全局特征用于行人检索。这篇文章是CVPR2018中关于Person ReID的一篇,文章的主体思路就是part-base的方法,但是跟大部分part-base不一样的地方在于本文使用了行人分割支路的输出作为mask,然后对人体的各部件进行局部特征提取。这种方法很直观的就能知道比使用横条、竖条或者关键点连接然后外扩矩形的部件mask靠谱,但是个人觉得在CNN模型中,这些直观、很符合逻辑的策略可能并不一定能想想象的那么work。本文中作者使用了ResNet152和Inception-V3作为backbone并且说明了使用SPReID可以在任何一个backbone上带来提升。最终文章在4个数据集上进行了测试并且在rank-1和mAP上取得了目前最好的结果(目前最好的应该是云从的MGN)。
Person ReID是现在的热门方向,有着太多的实际应用需求,同时也有很多的难点需要去攻克,跨镜头中存在不同场景和不同相机的成像偏差,就算在同一个摄像头的取景中,人员出现角度、姿态的不同都会成为检索的难点,而且在目前的监控场景中,往往截取到的行人图像都是低分辨率的,这也是Person ReID的难点之一。其实从总的来看,Person ReID也是图像检索的一部分,所以提取一个表征能力强的特征作为每一个identity的“身份信息”,是解决目前所有问题的根本方向。过去CNN会对整张图像提取特征进行特定化任务训练(分类,分割和检测),但是在Person ReID中我们的关注点在于如何获取行人的特征,不一样的背景还有遮挡等因素都会使得最终提取出来的特征对于行人并没有太强的代表性。所以目前很多方法都是在global feature和part feature中寻找一个权衡。很多方法还分为多个stages去训练模型,对此,论文作者提出了两个疑问:
- 这些复杂的训练过程或者模型真的对提升Person ReID有用么?
- 使用box去切分人体的部件提取局部特征是合适的方法么?
对于第一个问题,作者使用Inception-V3结合两种不同的输入分辨率,然后都使用Softmax Loss作为评价指标去训练模型。并且使用re-ranking作为检索后处理手段,实验显示这样做是能够对Person ReID的性能带来提升的。对于第二个问题,作者认为使用box去框取人体的部件进行局部特征提取是不太合理的,一个box中有可能会引入太多的干扰信息比如背景,这样去提取的局部特征是“不干净”的。所以本文提出使用分割支路去辅助提取人体的特征。
本文的贡献点主要为以下三点:
- 通过实验可以证明使用一个简单但高效的训练过程结合一些普通的网络是能够对Person ReID的性能带来提升的。本文使用了ResNet152和Inception-V3去论证了这一观点;
- 作者提出了SPReID,在这个方法中人体分割模型被引入辅助用于局部特征提取。同时作者的这个分割模型也在特定的分割任务中取得了目前最好的成绩;
- 作者的方法取得了目前最优的性能,在Market-1501数据集上取得了17%的mAP提升和6%的rank-1提升(跟自己最差的一个结果比较),在CUHK03上取得了4%的rank-1提升,在DukeMTMC-reID上取得24%的mAP提升和~10%的rank-1提升。
Related Work
讨论了目前大部分主流的Person ReID方法,感兴趣的可以阅读原文。
Methodology
不做特殊说明的话,本文使用SPReID的backbone都是Inception-V3。首先简单的介绍了一下Inception-V3结构,然后对本文使用的方法进行详细介绍。
Inception-V3 Architecture
假定读者都具备一定的深度学习知识,对于Inception-V3结构这里不做太多介绍。关于这一小节,论文作者的描述除了基本知识,还会告诉大家他将原结构的怎么做了微笑的改动,比如使用GAP(global average pooling)在网络的末端输出2048-D的特征向量。
Human Semantic Parsing Model
作者说明了使用人体部件分割代替bbox的局部特征提取方法有更大的优越性。然后介绍了SPReID中的人体部件分割支路使用了Inception-V3作为backbone,然后为了使最终输出的feature map具有更高的的分辨率,作者将Inception-V3最后一层卷积stage中的stride由2改为了1,也就意味着经过一次网络前向以后这个降采样的倍率由32降到了16,最终的输出feature map分辨率提升了一倍;同时为了使得计算量不增加,对于输出的feature map,论文移除了GAP并增加了ASPP(atrous spatial pyramid pooling)(rates=3,6,9,12),之后接入1x1的卷积层,最后对人体部件的类型进行分类输出。
Person Re-identification Model
在SPReID中的Inception-V3移除了GAP,这样输出为2048通道的32 output stride
本文的baseline person re-identification model使用GAP汇聚了卷积输出的特征,产生2048维的全局表示,softmax cross-entropy loss训练
局部视觉线索的利用:使用由human semantic parsing model产生的五个身体不同区域的概率图
在SPReID中,利用每个概率图对卷积backbone的输出进行了汇总得到了5*2048的特征图,每一行对应通过一个概率图汇总得到的特征向量,相比GAP,这样的方法对空间位置有一定可知性,也可以将概率图看成身体各部分的权重
实现细节:
将两个分支的输出特征图flatten进行了矩阵乘:eg.对于一个身体部位概率图:30x30x2048 –> 900x2048;30x30x1 –> 900x1; 1x900 x 900x2048 –> 1x2048
将head、upper-body、lower-body、shoes的结果进行了元素间的max操作并与背景以及global representation拼接起来
语义分割模型通常需要较高分辨率的图片,对于送入re-identification backbone的图片先通过双线性插值缩小,再在最后的激活值处通过双线性插值放大来匹配human semantic parsing branch的分支
最终作者提出的SPReID如同下图所示: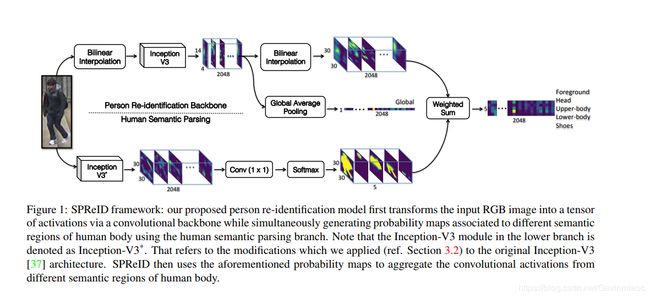
总共包含了一个卷积backbone和一个人体分割的branch,然后将两者的结果结合在一起。对于上图中的上部分分支,如果是走GAP分支的话,输出的是2048-D的特征矢量。在SPReID中,分割支路的输出feature map(其实就是个mask)可以看做是一个activation map,然后将这个activation map与上一条支路输出的feature map尺寸匹配之后做乘加运算。最后对于这些特征,使用多类别的Softmax来训练。在上图中,没有将分类部分给画出来,在之后的Person ReID检索中提取最后的特征即可。
需要注意的是分割支路给出的activation map总共有五类,分别是前景,头部,上半身,下半身和鞋子部分。对于每一个输出的activation map,使用l1-normalized方法将其归一化处理。这种乘加做法可以很直观的理解成,每一个部件都会在相应的区域产生一个weights,将其与feature map进行乘加运算之后可以增强特定部件的特征表示,并且降低其他区域的特征表示。由于是乘加操作,最终输出的就是一个2048-D的特征矢量,对于5个activation map,那么最终将产生5个2048-D的矢量。对于该输出特征,作者对除了前景部分的4个2048-D向量做一个element-wise的max操作,最终得到了一个2048-D矢量。最终这个输出矢量,前景的矢量再加上上图中GAP产生的2048-D矢量,总共3x2048的特征被用于分类(训练)和特征检索(测试)。
Experiments
这部分介绍了实验的结果。
Datasets and Evaluation Measures
作者在3个公开数据集上进行了输入大尺度测试,分别是Market-1501,CUHK03和DukeMTMC-reID。最后训练的时候除了刚才提到的三个数据集,还使用了额外7个数据集的训练集进行训练。(这是本文最大的槽点)分别是 3DPeS, CUHK01,CUHK02,PRID,PSDB,Shinpuhkan和VIPeR。不光是训练数据得到了极大的补充,ID类别数也有了极大的增长。训练过程通过了3DPeS、CUHK01、CUHK02、PRID、PSDB、Shinpukan、VIPeR数据集进行了扩增,训练集达到了11100张,17000个人物。
Training the Networks
在训练过程中,作者首先设置了一个Baseline类似的实验,为了证明在10个数据集上训练一定程度之后在特定数据集上以更大的input size输入fine-tune的性能提升。所以最开始,作者使用了没有分割支路的结构,以492x164的尺寸作为输入,在10个数据集上迭代20W次,之后根据这个训练模型以748x246的input size在特定数据集(比如Market-1501)上进行fine-tune,迭代5W次。
在SPReID训练过程中,除了网络结构不一样,其余和上述步骤保持一致,还有一个不同的地方就在于20W迭代的时候在SPReID中使用的是512x170的input size进行样本输入。
作者的分割支路使用了上文中所提到的结构在LIP数据集上进行预训练,分割的种类为上文提到的五类。在本文中作者也提到了他的这种分割做法在目前该数据集上取得了最好的成绩,实验结果和性能对比如下图所示:

Person Re-identification Performance
这部分考察了三个实验,首先第一个,在较小分辨率上训练,然后在大分辨率上特定数据集fine-tune;第二个,选择不同的网络结构作为方法的backbone;第三个,对于卷积backbone和行人部件分割的backbone是否使用权重共享的策略。
首先第一组实验的结果如下:
可以看到作者首先在10个数据集上使用三种不同size的分辨率进行输入训练,然后在一个更大的分辨率,上图中为748x246,对特定数据集进行fine-tune,结果会提升很多。这个情况其实挺正常的,在测试的时候增加分辨率不管是在分类还是检测任务中都被证明是更有效的,但是分辨率的提升带来的是性能的额外增长。
之后作者讨论了使用不同backbone的实验,实验结果如下:
上述实验结果也展示了,在大部分任务中,其实使用ResNet152作为backbone往往能得到比Inception-V3更好的结果,但在部分任务中这个结论也不一定成立。而且Inception-V3的结构和计算量都比ResNet152要下,跟差不多计算量和深度的ResNet50作对比的话,能看出Inception-V3性能是明显好于它的。
接下来讨论SPReID的作用,首先实验结果如下:
我们这里为了方便只看Market-1501的实验结果,第一行表示的是只使用Inception-V3结构的baseline结果,2,3行表示在SPReID中是否使用前景的2048-D矢量,直观来说就是考察了2x2048和3x2048的检索性能对比,第4行这个实验就做得有些莫名其妙了,将2,3的模型做ensemble,具体做法是对于两个模型的输出特征使用了l2-normalization和concatenation,总共得到5x2048的特征矢量用于检索,显然性能会更高一点。
之后作者讨论了是否让SPReID中的卷积backbone和人体部件分割支路共享权重,实验结果如下所示:
上图中我们只看Market-1501实验结果,从流程上来看1,3行和2,4行分别表示的是SPReID训练的一个完整流程。即首先在10个数据集上训练,然后再在特定数据集上进行fine-tune。可以看到,不使用权值共享的策略是能够得到更好的结果的,这也能想明白,分割支路的权值更新,理论上应该使用Person ReID的分割groundtruth监督训练才行,这里如果都使用identity softmax loss来监督更新,是不合适的。
最终作者对比了自己的方法和目前最好的方法性能,这里只列出了Market-1501上的结果,感兴趣的朋友可以查看原论文。性能对比如下表所示:
Implementation Details
论文实现细节,单卡的batch-size为15(其实在代码中是16,这里应该是写错了),momentum设置为0.9,weight_decay和gradient_clip分别是0.0005和2.0。训练过程中初始学习率为0.01,在fine-tune中初始学习率为0.001。学习率的下降总共分为10个step,每个step下降结果为下面公式所示:
训练的优化方法使用的是Nesterov Accelarated Gradient并且使用ImageNet进行模型的初始化。
Conclusion
文章表示这种SPReID的方法可以无缝衔接目前的大部分网络结构,并且通过实验是能够证明有性能提升的。方法简单且高效。但笔者认为,在复现这篇论文的过程中,有一点被忽视的地方就是使用10个数据集进行训练再fine-tune其实有些不太公平了,虽然最终讨论的结果是在特定数据集上使用训练集训练的模型,但是一开始初始化过程中10个数据集是或多或少对模型的学习能力有帮助的。
本文提出的两个问题:
实现SOTA的model需要这么复杂吗?
bbox是处理局部视觉线索最好的方法吗?
通过大量的实验解决上述问题:
仅使用简单的model在大量高分辨率的图片上训练即可超越SOTA
使用human sematic parsing来处理局部视觉线索可以进一步提高性能
这里是不是应该再做个bbox的实验?
参考文献:
1.https://www.jianshu.com/p/46a7670be6c5
2.https://blog.csdn.net/weixin_41427758/article/details/80723698