CentOS7下搭建Hadoop2.9.1完全分布式集群过程(超详细)
Hadoop 集群搭建
本文主要对完全分布式Hadoop集群环境的安装与配置步骤进行介绍。
使用VMware Workstation Pro 14.0、CentOS7和Hadoop2.9.1
集群的节点规划信息如下:
| Host Name |
IP Address |
Node Type |
User Name |
| master |
192.168.223.100 |
DataNode/NodeManager /NameNode |
hadoop / root |
| salve1 |
192.168.223.101 |
DataNode / NodeManager /SecondaryNameNode |
hadoop / root |
| slave2 |
192.168.223.102 |
DataNode / NodeManager /ResourceManager |
hadoop / root |
Hadoop官方地址:http://hadoop.apache.org
环境配置
1. All nodes are disabled SELinux and firewalld
2. All nodes can ping with each other
3. All nodes have same hadoop directory structure and a same user account
4. Create a hadoop user, home directory is /home/hadoop, add into root group
5. hadoop directory is /usr/local/hadoop, directory owner is hadoop
6. Master node and slave node can SSH with no password publick key authentication
7. All nodes have same /etc/hosts, add master node and slave node record line
1、Hadoop - 安装准备
1.1添加Hadoop用户、创建相关目录并分配权限
在CentOS 7下新建hadoop用户,官方推荐的是hadoop、mapreduce、yarn分别用不同的用户安装,本文相关环境全部在hadoop用户下安装。首先需要添加Hadoop用户,为了方便部署,并为其分配管理员权限:
[root@localhost ~]# groupadd hadoop
[root@localhost ~]# useradd -m hadoop -G hadoop -s /bin/bash
[root@localhost ~]# passwd hadoop
[root@localhost ~]# visudo
使用 visudo 命令后找到 root ALL=(ALL) ALL 这一行(应该在90到100行之间,vi命令模式下输入 :set nu 就会显示行号,可以输入例如 :92 回车跳转到92行。),
然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL (当中的间隔为tab),然后保存退出。
在 /usr/local/ 目录下创建目录:java、hadoop、hive三个目录并分配权限给hadoop用户:
[root@localhost local]# chown -R hadoop:hadoop /usr/local/java
[root@localhost local]# chown -R hadoop:hadoop /usr/local/hadoop
[root@localhost local]# chown -R hadoop:hadoop /usr/local/hive
1.2 修改主机名(root权限)
由于 Hadoop 集群内部有时需要通过主机名来进行相互通信,因此我们需要保证每一台机器的主机名都不相同。
下面给出不同CentOS版本下修改主机名的操作命令:
Centos6:
[root@localhost ~]# hostname # 查看当前的 hostname
localhost
[root@localhost ~] # vim /etc/sysconfig/network # 编辑 network 文件修改hostname行(重启生效)
[root@localhost ~]# cat /etc/sysconfig/network # 检查修改
NETWORKING=yes
HOSTNAME=master
[root@localhost ~]# hostname hadoop34 # 设置当前的hostname(立即生效)
Centos7:
[root@localhost ~]# hostname #查看当前的 hostnmae
localhost
[root@localhost ~]# hostnamectl set-hostname master #永久修改hostname(立即生效)
[root@localhost ~]# hostname # 检查修改
master
1.3 网络配置
采用NAT方式联网。
如果创建的是桌面版的CentOS7系统,可以在安装完毕后通过图形页面进行编辑。如果是mini版本的,可通过编辑ifcfg-ens*配置文件进行配置。
注意: BOOTPROTO、GATEWAY、NETMASK。
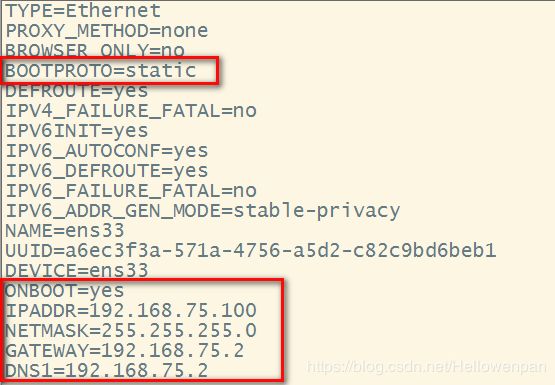
1.4 修改HOSTS(root权限)
修改HOSTS的原因主要有两点:
1.Hadoop 内部机制需要通过主机名对主机进行访问。
2.使用主机名对 Hadoop 集群进行配置,看起来更加一目了然。
在CentOS7中修改HOSTS 操作命令如下:
# 修改每台机器的 /etc/hosts 文件
[root@localhost ~]# vi /etc/hosts
#在文件中添加集群所有主机的IP和主机名的对应关系,IP 与主机名之间使用一个 TAB 键分隔
192.168.223.100 master
192.168.223.101 slave1
192.168.223.102 slave2
如果想要多个主机名路由到同一个 IP,只需要在 IP 后边添加多个主机名即可,多个主机名之间同样使用 TAB 键进行分隔,例如:
192.168.223.100 master namenode34 resourcemanager34
1.5 关闭SELinux(root权限)
因为CentOS的所有访问权限都是有SELinux来管理的,为了避免我们安装中由于权限关系而导致的失败,需要先将其关闭,以后根据需要再进行重新管理。
在CentOS中关闭SELinux使用如下操作命令:
[root@localhost ~]# getenforce # 查看当前的 SELinux 状态Enforcing
# setenforce 1 可以设置 SELinux 为 enforcing 模式
[root@localhost ~]# setenforce 0 # 将 SELinux 的状态临时设置为 Permissive 模式(立即生效)
[root@localhost ~]# getenforce # 检查修改Permissive
[root@localhost ~]# vi /etc/selinux/config
# 编辑 config 文件将 SELINUX=enforcing 修改为 SELINUX=disabled(重启生效)
[root@localhost ~]# cat /etc/selinux/config # 检查修改
注意:使用 getenforce 命令获取当前 SELinux 的运行状态为 permissive 或者 disabled 时均表示关闭。
1.6 关闭防火墙(root权限)
关闭防火墙(root权限)
为避免由于防火墙策略导致安装失败问题,需要先关闭防火墙,下面给出不同CentOS版本下关闭防火墙的操作命令:
Centos6:
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
集群内部相当于一个内部网络,所以,防火墙一般都需要关闭。
Centos7:
# Centos7 中使用 systemctl 命令来管理服务,命令格式如下
# systemctl [start 开启]|[stop 停止]|[restart 重启]|[status 状态][enable 开机启动]| [disable 禁止开机启动] 服务名称
[root@localhost ~]# systemctl start firewalld # 开启防火墙
[root@localhost ~]# systemctl status firewalld # 查看防火墙状态
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: active (running) since Wed 2018-08-08 09:18:09 CST; 24s ago
# active (running) 表示防火墙开启
Docs: man:firewalld(1)
Main PID: 21501 (firewalld)
CGroup: /system.slice/firewalld.service
└─21501 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
Aug 08 09:18:07 localhost.localdomain systemd[1]: Starting firewalld - dynamic firewall daemon...
Aug 08 09:18:09 localhost.localdomain systemd[1]: Started firewalld - dynamic firewall daemon.
[root@localhost ~]# systemctl disable firewalld # 永久关闭防火墙(重启生效)
[root@localhost ~]# systemctl stop firewalld # 临时关闭防火墙(立即生效)
[root@localhost ~]# systemctl status firewalld # 检查修改
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
# inactive (dead) 表示防火墙关闭
Docs: man:firewalld(1)
Aug 08 09:18:07 localhost.localdomain systemd[1]: Starting firewalld - dynamic firewall daemon...
Aug 08 09:18:09 localhost.localdomain systemd[1]: Started firewalld - dynamic firewall daemon.
Aug 08 09:19:24 localhost.localdomain systemd[1]: Stopping firewalld - dynamic firewall daemon...
Aug 08 09:19:24 localhost.localdomain systemd[1]: Stopped firewalld - dynamic firewall daemon.
关闭或者禁用防火墙, systemctl stop firewalld.service 关闭防火墙;systemctl disable firewalld.service 关闭防火墙
firewall-cmd --state 查看状态
1.7 同步时间
#手动同步集群各机器时间(这里三台:master、slave1、slave2)
date -s "2018-9-18 10:10:10"
yum install ntpdate
#网络同步时间
ntpdate cn.pool.ntp.org
单台机器的时间:

要同步多台机器,可以打开远程工具的【Command Window】

选中【Command Window】后,在窗口最下边显示【Send commands to all sessions】,在里面右键单击,选择向所有sessions的发送命令


在上面的【Send commands to all sessions】输入date
可以查看台机器时间的误差



如果多台机器之间的时间差比较多,就要矫正,使得各台之间的时间误差不多,其中有两种方法来实现:
第1种:使用
date -s "2018-9-18 10:10:10"
第2种:
先使用 yum来进行安装
yum install ntpdate
再使用ntpdate来实现
#网络同步时间
ntpdate cn.pool.ntp.org
1.8 配置ssh免密登录
#生成ssh免密登录密钥
ssh-keygen –t rsa (四个回车)
执行完这个命令后,会生成id_rsa(私钥)、id_rsa.pub(公钥)
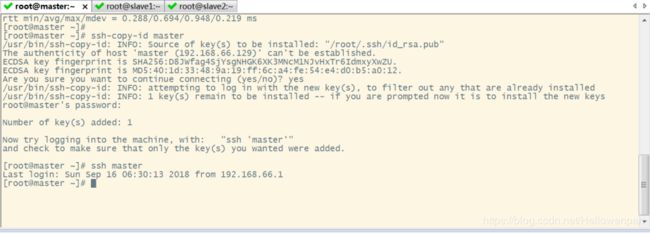
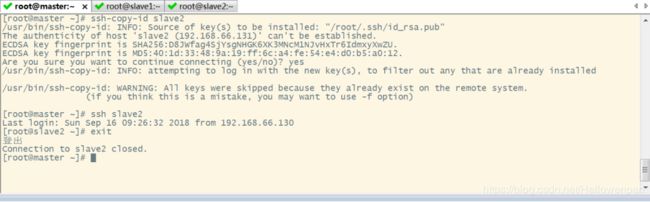
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id slave1
ssh-copy-id slave2
一般配置是从主节点到从节点
在配置免密登录时,先给主节点自己配置一个免密登录,因为后面一些程序在自己内部调用是需要免密登录的
第1步: 在客户端生成公钥和私钥
[root@localhost ~]# ssh-keygen -t rsa
t表示类型,使用rsa算法,还是使用dsa算法


2、JDK环境安装
2.1 JDK安装准备
第1步 卸载系统自带的OpenJDK以及相关的java文件
一些开发版的CentOS会自带jdk,我们一般用自己的jdk,把自带的删除。先看看有没有安装java -version。
关于OpenJDK和JDK的区别可以查看:http://www.cnblogs.com/sxdcgaq8080/p/7487369.html
如果CentOS7是安装的Minimal版本,那么里面就没有JDK;
如果CentOS7是安装的桌面版本,那么里面很可能有JDK,它是openjdk组织提供的,需要把它卸载掉
1) 卸载现有jdk
(1) 首先是,搜索或查找是否安装java软件:
[root@master ~]# rpm -qa | grep java //搜索命令
(2) 如果安装的版本低于1.7,卸载该jdk:
[root@master ~]# sudo rpm -e --nodeps 软件包(java的安装包,一般为3个) //卸载掉JDK
2) 下载
先下载jdk-8u181-linux-x64.tar.gz与Hadoop-2.9.1.tar.gz安装包
3) 创建文件夹 [root@hadoop local]# mkdir java
4) 上传
上传到java目录下,先按下alt+p

查看一下在java目录,是否存在刚才传的文件

说明已经上传成功
4 ) 解压jdk安装包
[root@hadoop java]# tar zxvf jdk-8u181-linux-x64.tar.gz


#配置环境变量 /etc/profile
export JAVA_HOME= /root/apps/jdk1.8.0_181
export PATH= $PATH:$JAVA_HOME/bin
export CLASSPATH= . : $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tool.jar
#刷新配置
source /etc/profile

查看

查看路径
[root@hadoop java]# cd jdk1.8.0_181/
[root@hadoop jdk1.8.0_181]# pwd
/usr/local/java/jdk1.8.0_181
[root@hadoop jdk1.8.0_181]#

[root@hadoop ~]# vi /etc/profile
追加在文件的末尾

执行source /etc/profile使用生效
测试jdk是否安装成功:


3、Hadoop安装
3.1 Hadoop下载
https://archive.apache.org/dist/hadoop/common/hadoop-2.9.1/
https://archive.apache.org/dist/hadoop/common/

下载稳定版本
https://archive.apache.org/dist/hadoop/common/stable/

创建目录hadoop,即在/usr/local下面创建hadoop文件夹

3.2 Hadoop导入
用SecureCRT工具将hadoop-2.9.1.tar.gz导入到/usr/local/目录下面的hadoop文件夹下面
切换到sftp连接页面,选择Linux下编译的hadoop jar包拖入

3.3 Hadoop解压
1)解压
[root@hadoop java]# tar -zxvf hadoop-2.9.1.tar.gz //表示解压到当前目录下

2)查看解压是否成功


3.4 配置Hadoop环境变量
将hadoop添加到环境变量
(1) 获取hadoop安装路径:
[root@master hadoop-2.9.1]# pwd
/root/apps/hadoop-2.9.1
(2) 打开/etc/profile文件:
[root@master ~]# vi /etc/profile
在profie文件末尾添加jdk路径:(shitf+g)


#JAVA_HOME
export JAVA_HOME=/root/apps/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/root/apps/hadoop-2.9.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3) 让修改后的文件生效:
[root@master ~]# source /etc/profile
(4) 测试是否安装成功
[root@master ~]# hadoop version


7)重启(如果hadoop命令不能用再重启):
[root@master ~]# sync
[root@master ~]# sudo reboot
scp只能单节点传输,即从一个节点传递到另外一个节点

[root@master ~]#
3.5、Hadoop安装包目录结构
解压hadoop-2.9.1.tar.gz,目录结构如下:

bin:Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。
etc: Hadoop配置文件所在的目录,包括core-site.xml、 hdfs-site.xml、mapred-site.xml等从hadoop 1.0继承而来的配置文件和yarn-site.xml等Hadoop 2.0新增的配置文件。
include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
lib:该目录包含了Hadoop对外提供的编辑动态库和静态库,与include目录中的头文件结合使用。
libexec: 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
sbin:Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
share: Hadoop各个模块编译后的jar包所在的目录。
4、Hadoop配置文件修改
Hadoop安装主要就是配置文件的修改,一般在主节点进行修改,完毕后下发给其它各个从节点机器。
hadoop-2.9.1解压后的目录

hadoop-2.9.1/etc/hadoop目录结构,下面主要是一些配置文件,如下。


4.1 集群部署规划
|
|
master |
slave1 |
slave2 |
| HDFS |
NameNode |
|
SecondaryNameNode |
| DataNode |
DataNode |
DataNode |
|
| YARN |
NodeManager |
NodeManager |
NodeManager |
|
|
ResourceManager |
|
4.2 配置文件
4.2.1 core-site.xml
[root@master hadoop]# vi core-site.xml
4.2.2 hadoop-env.sh
[root@master hadoop]# vi hadoop-env.sh



export JAVA_HOME=/root/apps/jdk1.8.0_181
4.2.3 hdf-site.xml
[root@hadoop1 hadoop]# vi hdfs-site.xml


4.2.4 yarn-env.sh
[root@hadoop1 hadoop]# vi yarn-env.sh



export JAVA_HOME=/root/apps/jdk1.8.0_181
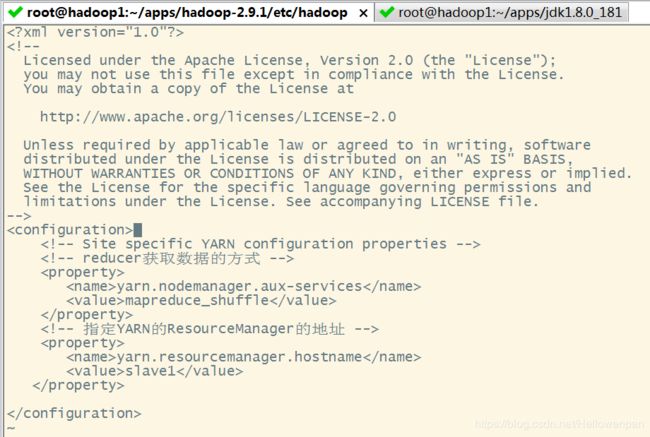
4.2.5 yarn-site.xml
[root@hadoop1 hadoop]# vi yarn-site.xml

4.2.6 mapred-env.sh
[root@hadoop1 hadoop]# vi mapred-env.sh



export JAVA_HOME=/root/apps/jdk1.8.0_181
4.2.7 mapred-site.xml
[root@master hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml


5、传递复制到从节点
接着下来传递
scp -r /root/apps root@slave1: ~/
scp -r /root/apps root@slave1: ~/
6、运行
6.1 格式化NameNode
hadoop namenode -format
6.2 运行方式
hadoop三种启动方式
第1种方式
启动:分别启动HDFS和MapReduce
命令如下:start-dfs.sh start-mapreted.sh
命令如下:stop-dfs.sh stop-mapreted.sh
第2种方式
全部启动或者全部停止
启动:
命令:start-all.sh
启动顺序:NameNode,DateNode,SecondaryNameNode,JobTracker,TaskTracker
停止:
命令:stop-all.sh
关闭顺序性:JobTracker,TaskTracker,NameNode,DateNode,SecondaryNameNode
第3种启动方式
每个守护线程逐一启动,启动顺序如下:
NameNode,DateNode,SecondaryNameNode,JobTracker,TaskTracker
命令如下:
启动:
hadoop-daemon.shdaemon(守护进程)
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datenode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start jobtracker
hadoop-daemon.sh start tasktracker
关闭命令:
hadoop-daemon.sh stop tasktracker
hadoop-daemons.sh 启动多个进程
datanode与tasktracker会分不到多台机器上,从节点启动,就使用
6.3 运行结果