Hadoop安装环境2.x
【环境安装Centos 7】Hadoop2.x
0. Hadoop源码包下载
http://mirror.bit.edu.cn/apache/hadoop/common
1. 集群环境
Master 192.168.10.10
Slave1 192.168.10.11
Slave2 192.168.10.12
2. 下载安装包
#Master
cd /usr/local/src/
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.2/hadoop-2.8.2.tar.gz
tar zxvf hadoop-2.8.2.tar.gz
2.1关闭系统防火墙及内核防火墙
#Master、Slave1、Slave2
启动: systemctl start firewalld
关闭: systemctl stop firewalld
查看状态: systemctl status firewalld
开机禁用 : systemctl disable firewalld
开机启用 : systemctl enable firewalld
#临时关闭内核防火墙
setenforce 0
#永久关闭内核防火墙
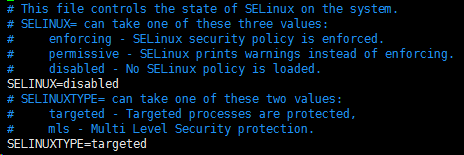
vim /etc/selinux/config
SELINUX=disabled
3. 修改主机名
#Master
hostnamectl set-hostname master【永久修改,重启生效】
hostname master【临时修改,重启失效】
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
#Slave1
hostnamectl set-hostname slave1【永久修改,重启生效】
hostname master【临时修改,重启失效】
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave1
#Slave2
hostnamectl set-hostname slave2【永久修改,重启生效】
hostname master【临时修改,重启失效】
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave2
4. 修改IP地址
#Master、Slave1、Slave2
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
NAME=ens33
#UUID=c03dd2ee-8d79-4a0f-9237-fb4d1039abf0
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.10.10
NETMASK=255.255.255.0
GATEWAY=192.168.10.2
DNS1=192.168.10.2
5. 修改主机文件
#Master、Slave1、Slave2
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# 以下是添加的
192.168.11.x master
192.168.11.x slave1
192.168.11.x slave2
# 将master节点的hosts文件分发到slave节点:
scp /etc/hosts root@slave1:/etc/
scp /etc/hosts root@slave2:/etc/
6.启动ssh无密码登录
#Master、Slave1、Slave2
#在master节点的/etc/ssh/sshd_config文件中去掉注释
#在这个文件中只有“Authentication:”选项,修改这个就行~~
vim /etc/ssh/sshd_config
RSAAuthentication yes #开启私钥验证
PubkeyAuthentication yes #开启公钥验证
#再次通过scp命令将sshd_config文件分发到其他节点
scp /etc/ssh/sshd_config root@slave1:/etc/ssh/
scp /etc/ssh/sshd_config root@slave2:/etc/ssh/
6. SSH互信配置
#Master、Slave1、Slave2
#生成密钥对(公钥和私钥)
ssh-keygen -t rsa -P ' '
#三次回车
结果如下:
[root@master ~]# ssh-keygen -t rsa -P ''
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
22:42:2d:15:39:cc:f6:4a:9c:da:57:5b:55:b8:18:5d root@master
The key's randomart image is:
+--[ RSA 2048]----+
| ooo . +E |
| o* . + |
| oo.+ + . |
| . .+ . . o . |
| .+....So |
| ..o.... |
| . |
| |
| |
+-----------------+
#在master节点执行:
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
#相互追加Key
#Master
ssh slave1 cat /root/.ssh/authorized_keys >> /root/.ssh/authorized_keys
ssh slave2 cat /root/.ssh/authorized_keys >> /root/.ssh/authorized_keys
#Slave1
ssh master cat /root/.ssh/authorized_keys > /root/.ssh/authorized_keys
#Slave2
ssh master cat /root/.ssh/authorized_keys > /root/.ssh/authorized_keys
#重启sshd服务:【每个节点都要重启】
systemctl restart sshd.service
#验证ssh无密码登录
[root@master]#
[root@master]# ssh slave1
Last login: Tue Jun 26 11:35:53 2018 from master
[root@slave1 ~]#
第一次会提示你输入密码,在选择yes/no的 时候,输入yes
成功,结束~~
7. 安装JDK
http://www.oracle.com/technetwork/java/javase/downloads/index.html

卸载
查看已经安装的jdk
[root@master]# rpm -qa|grep jdk
java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
卸载命令:
[root@master]#yum -y remove java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
卸载完之后java命令不被识别:
[root@master]# java -version
bash: java: command not found...
#Master
cd /usr/local/src
wget 具体已上面的链接地址为准
tar zxvf jdk1.8.0_152.tar.gz
#Master、Slave1、Slave2
#安装完毕后在/etc/profile文件末尾添加:
vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_101
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
使文件生效:
[root@master]# source /etc/profile
JDK拷贝到Slave主机
#Master
scp -r /usr/local/src/jdk1.8.0_152 root@slave1:/usr/local/src/
scp -r /usr/local/src/jdk1.8.0_152 root@slave2:/usr/local/src/
8. 下载Hadoop
#Master
cd /usr/local/src
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-2.6.5.tar.gz
tar zxvf hadoop-2.6.5.tar.gz
cd hadoop-1.2.1
# 修改配置文件 在第24行添加Java的环境变量
cd hadoop-2.6.5/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
# 修改配置文件 在第24行添加Java的环境变量
vim yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
# 修改配置文件添加从节点主机名
vim slaves
slave1
slave2
# 修改配置文件 添加RPC配置
vim core-site.xml
fs.defaultFS
hdfs://192.168.10.10:9000
hadoop.tmp.dir
file:/usr/local/src/hadoop-2.6.5/tmp
# 修改配置文件 添加DFS配置
vim hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.namenode.name.dir
file:/usr/local/src/hadoop-2.6.5/dfs/name
dfs.datanode.data.dir
file:/usr/local/src/hadoop-2.6.5/dfs/data
dfs.replication
3
# 修改配置文件 添加MR配置
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
mapreduce.framework.name
yarn
# 修改配置文件 添加资源管理配置
vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8035
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
创建临时目录和文件目录
mkdir /usr/local/src/hadoop-2.6.5/tmp
mkdir -p /usr/local/src/hadoop-2.6.5/dfs/name
mkdir -p /usr/local/src/hadoop-2.6.5/dfs/data
配置环境变量,在配置最后加入
vim /etc/profile
HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin
# 复制环境变量到从节点
scp /etc/profile root@slave1:/etc/profile
scp /etc/profile root@slave2:/etc/profile
# 复制Hadoop包到从节点
scp -r /usr/local/src/hadoop-2.6.5 root@slave1:/usr/local/src/
scp -r /usr/local/src/hadoop-2.6.5 root@slave2:/usr/local/src/
# 重新加载环境变量
source /etc/profile
格式化Namenode
[root@master src]# hadoop namenode -format
# 提示下列内容即是成功完成格式化
common.Storage: Storage directory /usr/local/src/hadoop-2.6.5/dfs/name has
been successfully formatted
启动集群
[root@master src]# /usr/local/src/hadoop-2.6.5/sbin/start-all.sh
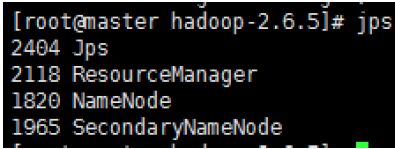
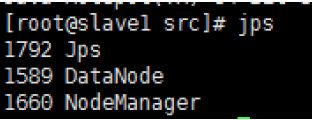
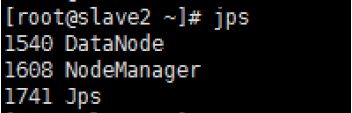
查看服务进程
[root@master src]# jps