(图文并茂)深度学习实战(4):从mnist数据集里面提取原始图片数据
(图文并茂)深度学习实战(4):从mnist数据集里面提取出图片数据
经过上一篇的(图文并茂)深度学习实战(3):mnist手写体识别案例,我们运行了caffe自带的mnist手写体案例,获得了一个mnist的模型,并且使用这个模型来预测了一下。但是是不是觉得不够可视化?数据集样子也看不到,而且都是使用sh脚本,很多不熟悉?
还有最重要的一点,就是官网提供的mnist数据并不是图片,但我们以后做的实际项目可能是图片,因此我们的练习就从图片开始。
所以今天介绍一下从mnist数据集里面提取出图片数据的做法。
1.mnist二进制数据集介绍
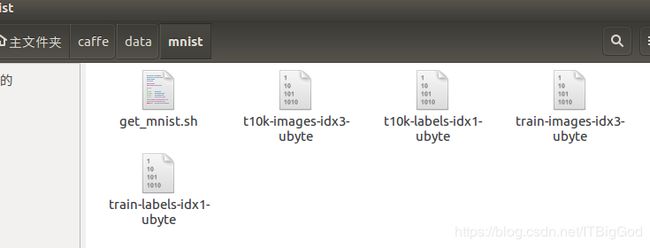
由于在caffe下下载好的mnist数据集是类似于t10k-images-idx3-ubyte这样的二进制文件,mnist 原二进制文件是一个训练图片集,一个训练标签集,一个测试图片集,一个测试标签集;
训练集是有60000个用例的,也就是说这个文件里面包含了60000个标签内容,每一个标签的值为0到9之间的一个数。
图示:
2.Python将MNIST数据集转化为图片
编写两个.py文件:分别用来提取测试集,训练集:
1.提取训练集mnist_tiqu.py:
(其中就涉及到重命名位数不足,而采取不足5位补0)
py实现重命名+补全位数版本源码:
# -*- coding:utf-8 -*-
# author zoutao
# 2017/11/2
import numpy as np
import struct
from PIL import Image
import os
data_file = '/home/nvidia/caffe/data/mnist/train-images-idx3-ubyte' #需要修改的路径
# It's 47040016B, but we should set to 47040000B
data_file_size = 47040016
data_file_size = str(data_file_size - 16) + 'B'
data_buf = open(data_file, 'rb').read()
magic, numImages, numRows, numColumns = struct.unpack_from(
'>IIII', data_buf, 0)
datas = struct.unpack_from(
'>' + data_file_size, data_buf, struct.calcsize('>IIII'))
datas = np.array(datas).astype(np.uint8).reshape(
numImages, 1, numRows, numColumns)
label_file = '/home/nvidia/caffe/data/mnist/train-labels-idx1-ubyte' #需要修改的路径
# It's 60008B, but we should set to 60000B
label_file_size = 60008
label_file_size = str(label_file_size - 8) + 'B'
label_buf = open(label_file, 'rb').read()
magic, numLabels = struct.unpack_from('>II', label_buf, 0)
labels = struct.unpack_from(
'>' + label_file_size, label_buf, struct.calcsize('>II'))
labels = np.array(labels).astype(np.int64)
datas_root = '/home/nvidia/桌面/zout_study/mnist_zt/mnist_data/train' #需要修改的路径
if not os.path.exists(datas_root):
os.mkdir(datas_root)
for i in range(10):
file_name = datas_root + os.sep + str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
for ii in range(numLabels):
img = Image.fromarray(datas[ii, 0, 0:28, 0:28])
label = labels[ii]
#不足5位补0版本
file_name = datas_root + os.sep + str(label) + os.sep + \
str(ii).zfill(5) + '.png'
img.save(file_name)
2.提取测试集mnist_tiqu_test.py:
源码:
#-*- coding:utf-8 -*-
# author zoutao
# 2017/11/2
import numpy as np
import struct
from PIL import Image
import os
data_file = '/home/nvidia/caffe/data/mnist/t10k-images-idx3-ubyte' #需要修改的路径
# It's 7840016B, but we should set to 7840000B
data_file_size = 7840016
data_file_size = str(data_file_size - 16) + 'B'
data_buf = open(data_file, 'rb').read()
magic, numImages, numRows, numColumns = struct.unpack_from(
'>IIII', data_buf, 0)
datas = struct.unpack_from(
'>' + data_file_size, data_buf, struct.calcsize('>IIII'))
datas = np.array(datas).astype(np.uint8).reshape(
numImages, 1, numRows, numColumns)
label_file = '/home/nvidia/caffe/data/mnist/t10k-labels-idx1-ubyte'#需要修改的路径
# It's 10008B, but we should set to 10000B
label_file_size = 10008
label_file_size = str(label_file_size - 8) + 'B'
label_buf = open(label_file, 'rb').read()
magic, numLabels = struct.unpack_from('>II', label_buf, 0)
labels = struct.unpack_from(
'>' + label_file_size, label_buf, struct.calcsize('>II'))
labels = np.array(labels).astype(np.int64)
datas_root = '/home/nvidia/桌面/zout_study/mnist_zt/mnist_data/test' #需要修改的路径
if not os.path.exists(datas_root):
os.mkdir(datas_root)
for i in range(10):
file_name = datas_root + os.sep + str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
for ii in range(numLabels):
img = Image.fromarray(datas[ii, 0, 0:28, 0:28])
label = labels[ii]
#加文字版本
file_name = datas_root + os.sep + str(label) + os.sep + \
'image_name_' + str(ii) + '.png'
#不足5位补0版本
file_name = datas_root + os.sep + str(label) + os.sep + \
str(ii).zfill(5) + '.png'
img.save(file_name)
分别运行即可!
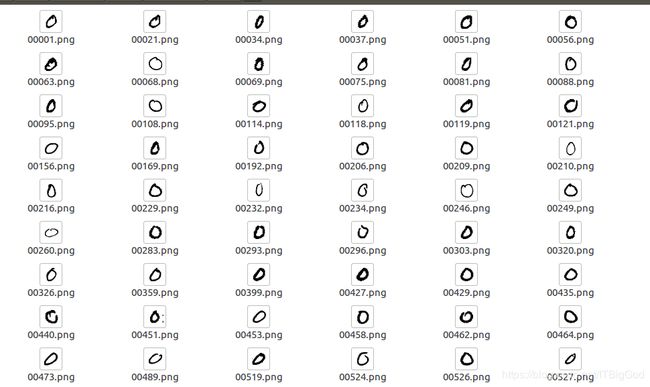
数据分成了训练集(60000张共10类)和测试集(共10000张10类),每个类别放在一个单独的文件夹0-9。
图:

提取出来的图片如下:
其中一些参考博客:
https://blog.csdn.net/qq_32166627/article/details/52640730
以上就是从mnist数据集里面提取原始图片数据,当然,caffe下使用python,是需要先编译python接口的,也就是你在终端下运行python,然后import cafe 不会报错。至于怎么编译的,可以参考这个系列的第一篇文章。
下一篇我们介绍mnist手写体项目的开发。