工作流调度器azkaban的安装和使用
前言
为什么需要工作流调度器?
1. 一个完整的数据分析系统通常都是由大量任务单元组成:
shell 脚本程序,java 程序,mapreduce 程序、hive 脚本等
2. 各任务单元之间存在时间先后及前后依赖关系
3. 为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行
例如,我们可能有这样一个需求,某个业务系统每天产生 20G 原始数据,我们每天都要对其进行处理,处理步骤如下所示:
1. 通过 Hadoop 先将原始数据同步到 HDFS 上;
2. 借助 MapReduce 计算框架对原始数据进行清洗转换,生成的数据以分区表的形式存储到多张 Hive 表中;
3. 需要对 Hive 中多个表的数据进行 JOIN 处理,得到一个明细数据 Hive 大表;
4. 将明细数据进行各种统计分析,得到结果报表信息;
5. 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使
简介
- 工作流调度实现方式:
简单的任务调度:直接使用 linux 的 crontab 来定义;
crontab 定时任务 计划任务
crontab -e
52 8 * * * echo 'hello' >> /home/hadoop/tt.txt
m h d m week 脚本位置
0 10 * * 1,2,3,4,5 echo 'hello' >> /home/hadoop/bd1804_cron.txt
复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如 ooize、azkaban 等
- 常见工作流调度系统
市面上目前有许多工作流调度器
在 hadoop 领域,常见的工作流调度器有 Oozie, Azkaban,Cascading,Hamake 等
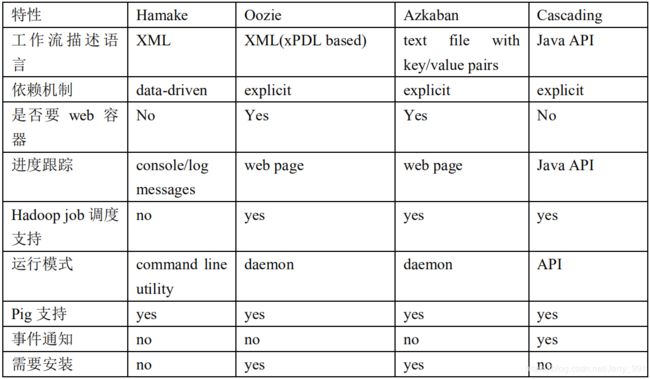
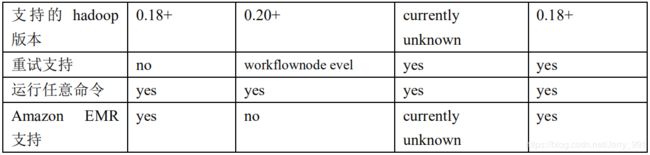
- 各种调度工具对比
下面的表格对上述四种 hadoop 工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考
- Azkaban 与 Oozie 对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比 azkaban 是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器 azkaban 是很不错的候选对象。
详情如下:
1. 功能
两者均可以调度 mapreduce,pig,java,脚本工作流任务
azakaban可以调度的任务:
java
shell
python
hadoop
spark
hql
sqoop
两者均可以定时执行工作流任务
2. 工作流定义
Azkaban 使用 Properties 文件定义工作流
Oozie 使用 XML 文件定义工作流
3. 工作流传参
Azkaban 支持直接传参,例如${input}
Oozie 支持参数和 EL 表达式,例如${fs:dirSize(myInputDir)} strust2(ONGL)
4. 定时执行
Azkaban 的定时执行任务是基于时间的
Oozie 的定时执行任务基于时间和输入数据
5. 资源管理
Azkaban 有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie 暂无严格的权限控制
6. 工作流执行
Azkaban 有两种运行模式,分别是 solo server mode(executor server 和 web server
部署在同一台节点)和 multi server mode(executor server 和 web server 可以部署在
不同节点)Oozie 作为工作流服务器运行,支持多用户和多工作流
7. 工作流管理
Azkaban 支持浏览器以及 ajax 方式操作工作流
Oozie 支持命令行、HTTP REST、Java API、浏览器操作工作流
优缺点:
oozie:
优点: 大型企业
调度机制比较全面
基于事件驱动的工作流调度 A B
高可用的
缺点:
不太好上手 使用的时候比较复杂
azkaban:
优点:易于上手操作
缺点:调度机制没有oozie完善 但是绝大部分的任务调度都是可以解决的 中小型公司
3.0之前不是高可用 存在单点故障的 3.0之后可以实现高可用的
共同特点:提供了比较优良的可视化界面
- Azkaban 介绍
Azkaban 是由 Linkedin 开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。
Azkaban 定义了一种 KV 文件(properties)格式来建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
它有如下功能特点:
Web 用户界面
方便上传工作流
方便设置任务之间的关系
调度工作流
认证/授权(权限的工作)
能够杀死并重新启动工作流
模块化和可插拔的插件机制
项目工作区
工作流和任务的日志记录和审计
Azkaban 安装部署
- 安装说明
将安装文件上传到集群,最好上传到安装 hive、sqoop 的机器上,方便命令的执行。并最好同一存放在同一个目录下,用于存放源安装文件.新建 azkaban 目录,用于存放 azkaban 运行程序
- 安装
1)上传
azkaban-executor-server-2.5.0.tar.gz 执行服务器
azkaban-sql-script-2.5.0.tar.gz 脚本文件
存的就是sql脚本 存储的元数据库
azkaban中将任务的调度进行存储 存储的时候就是二维表的形式进行存储 ---mysql中 这个脚本中存放的就是mysql的元数据初始化的脚本 手动操作
azkaban-web-server-2.5.0.tar.gz web服务
2)解压
tar -xvzf azkaban-web-server-2.5.0.tar.gz
tar -xvzf azkaban-executor-server-2.5.0.tar.gz
tar -xvzf azkaban-sql-script-2.5.0.tar.gz
3)配置环境变量
export AZKABAN_WEB_HOME=/home/hadoop/apps/azkaban/azkaban-web-2.5.0
export AZKABAN_EXE_HOME=/home/hadoop/apps/azkaban/azkaban-executor-2.5.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$HBASE_HOME/bin:$SQOOP_HOME/bin:$AZKABAN_WEB_HOME/bin:$AZKABAN_EXE_HOME/bin
source /etc/profile
4)生成数字证书文件 ssh-keygen生成秘钥的
生成结果在执行目录下 最好在azkaban目录下执行
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
What is the two-letter country code for this unit? [Unknown]:
将数字证书发送到web目录下:
cp keystore azkaban-web-2.5.0/
5)将时区文件发送到/etc/profile
sudo cp Shanghai /etc/localtime
6)初始化元数据库
在mysql上创建数据库:
create database azkaban;
use azkaban;
source /home/hadoop/apps/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql
7)修改配置文件
web的配置文件
1)vi azkaban.properties文件
#Azkaban Personalization Settings
azkaban.name=Test
azkaban.label=My Local Azkaban
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
web.resource.dir=/home/hadoop/apps/azkaban/azkaban-web-2.5.0/web/
default.timezone.id=Asia/Shanghai
#Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=/home/hadoop/apps/azkaban/azkaban-web-2.5.0/conf/azkaban-users.xml
#Loader for projects
executor.global.properties=/home/hadoop/apps/azkaban/azkaban-executor-2.5.0/conf/global.properties
azkaban.project.dir=projects
database.type=mysql
mysql.port=3306
mysql.host=hadoop01
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100
# Velocity dev mode
velocity.dev.mode=false
# Azkaban Jetty server properties.
jetty.maxThreads=25
jetty.ssl.port=8443
jetty.port=8081
jetty.keystore=/home/hadoop/apps/azkaban/azkaban-web-2.5.0/keystore
jetty.password=hadoop
jetty.keypassword=hadoop
jetty.truststore=/home/hadoop/apps/azkaban/azkaban-web-2.5.0/keystore
jetty.trustpassword=hadoop
# Azkaban Executor settings
executor.port=12321
# mail settings
mail.sender=
mail.host=
job.failure.email=
job.success.email=
lockdown.create.projects=false
cache.directory=cache
2)azkaban-users.xml 配置用户
启动
启动web服务器
1. 前台启动
azkaban-web-start.sh
2. 运行为后台服务
nohup zakaban-web-start.sh 1>/home/hadoop/azwebstd.out 2>/home/hadoop/azweberr.out &
启动执行服务器
1. 前台启动
azkaban-executor-start.sh
2. nohup zakaban-executor-start.sh 1>/home/hadoop/azexstd.out 2>/home/hadoop/azexerr.out &
登录html验证结果
登录地址为:https://hadoop03:8843,有出现以下页面则为登录成功:

Azkaban实战演示
command类型的单一job示例
- 创建 job 文件
vi command.job
#command.job
type=command
command=echo 'hello'
- 将 job 文件打包
zip command.zip command.job
- 通过Azkaban Web平台创建 project 并上传压缩包
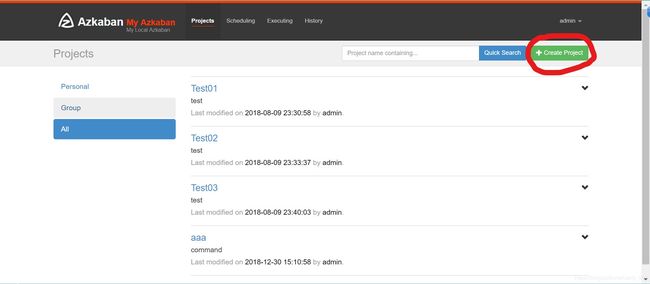
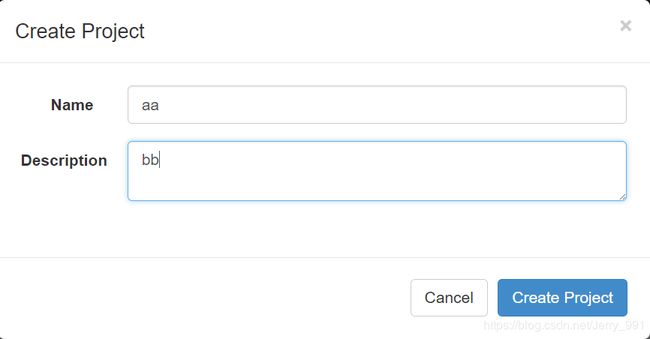
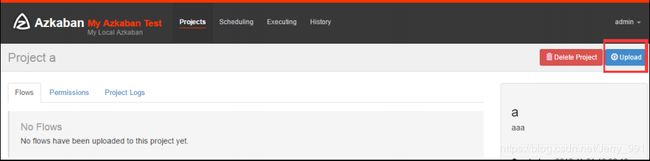
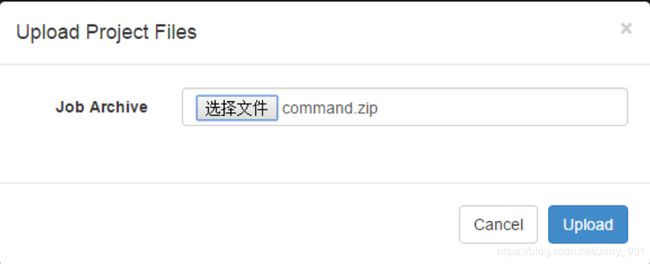
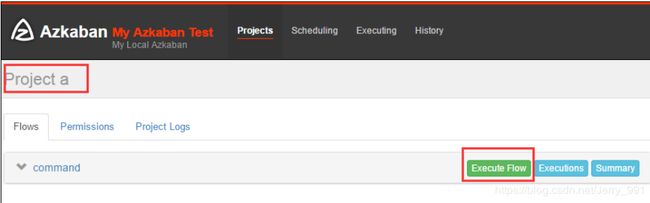
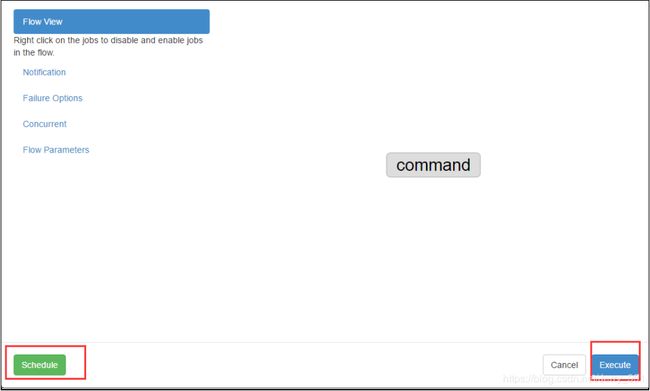
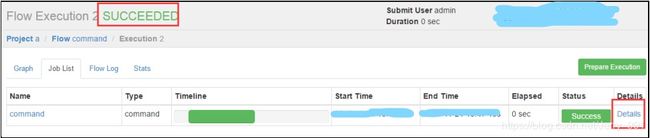
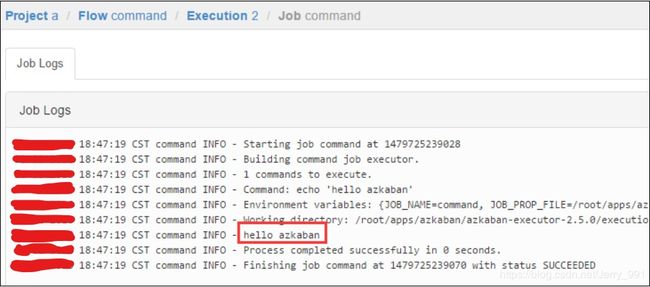
command类型多 job 工作流 flow
- 创建关系依赖的多个job
第一个job:one.job
# one.job
type=command
command=echo one
第二个job:two.job 依赖 one.job
# two.job
type=command
dependencies=one
command=echo two
-
将所有资源打成一个 zip 包
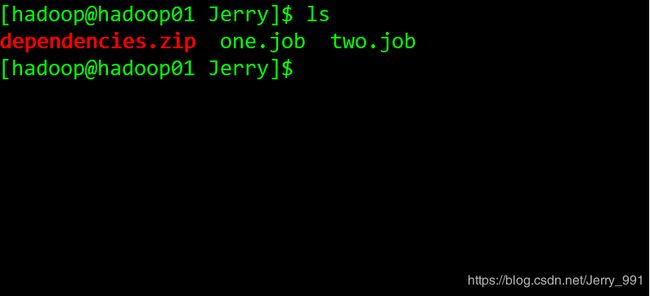
-
启动执行
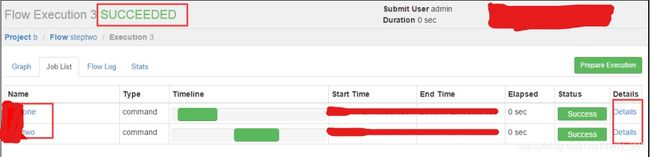
操作 MapReduce 任务
- 创建job描述文件
# mapreduce.job
type=command
command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout
-
将 job 资源问价打成 zip 包
-
创建project,并上传zip包
-
启动执行
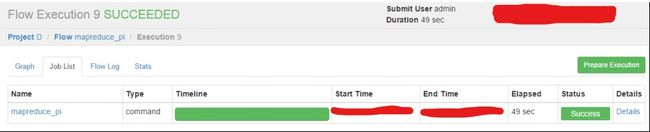
Hive脚本任务
- 创建hive描述文件和hive脚本
hive脚本如下:
1)hivetest.sql
use mysql;
drop table test;
create table test(id int,name string,sex string,age int,deparment string) row format delimited fields terminated by ',';
load data inpath '/student.txt' into table test;
create table aaa as select * from test;
insert overwrite directory '/test/hiveoutput' select count(1) from test;
2)job描述文件
# hivef.job
type=command
command=/root/apps/apache-hive-1.2.1-bin/bin/hive -f 'testhive.sql'
-
将所有文件打成 zip 包
-
通过 Azkaban 的 web 界面上传 zip 包,后启动 job