Post Hoc Test
最初从图书馆的一本生物统计书里大概明白了post hoc,后来时间久了又不大记得了,今天在google上搜到一篇关于post hoc的文章,看完感觉挺有收获的。以防此链接日后失效,先把它截屏拷贝过来:
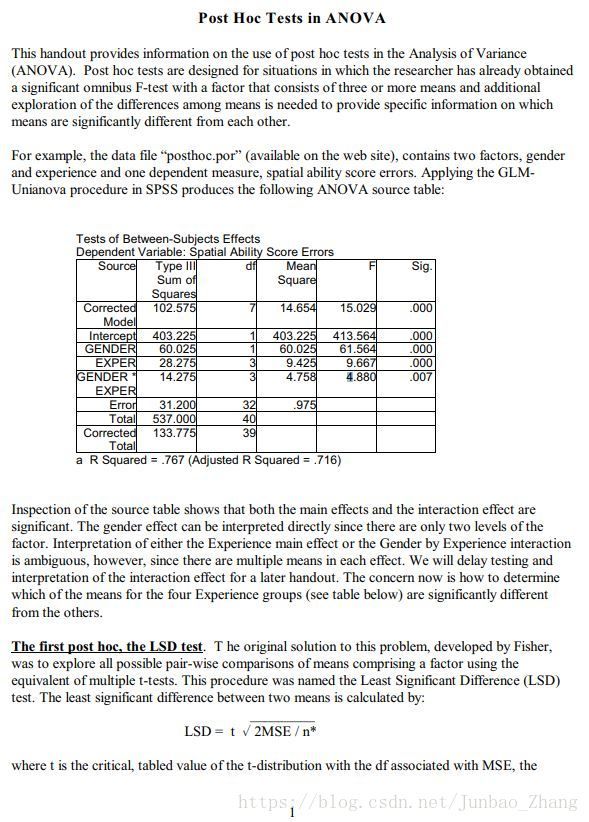



用R做事后比较的时候,我用了一个glht函数(最初是参考这篇博文知道glht这个函数):
#方差分析
fit=aov(total[,j]~age+edu+gender+group,data=total)
Fangcha=summary(fit)
P$P.Fangcha[i,j]= Fangcha[[1]]$`Pr(>F)`[4]
#Post Hoc
multicomp=summary(glht(fit,linfct=mcp(group="Tukey")),test = adjusted("fdr"))
#multicomp=summary(glht(fit,linfct=mcp(group="Tukey")),test = adjusted("none"))
P$P.iaeiu[i,j]=multicomp$test$pvalues[1]
P$P.coneiu[i,j]=multicomp$test$pvalues[2]
P$P.conia[i,j]=multicomp$test$pvalues[3]
#对glht函数的结果summary之后,得到如下结果:
> summary(glht(fit,linfct=mcp(group="Tukey")),test = adjusted("fdr"))
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: aov(formula = total[, j] ~ age + edu + gender + group, data = total)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
ia - eiu == 0 0.9706 1.6135 0.602 0.550
con - eiu == 0 2.4879 1.4685 1.694 0.217
con - ia == 0 1.5173 1.0248 1.481 0.217
(Adjusted p values reported -- fdr method)输出结果的标题显示它使用了一个Simultaneous(同步的) Tests,所以我又查了一下Simultaneous Tests是什么:
一篇文章告诉我:
“An approach to such methods, apparently originally due to Tukey [27], is to test each component hypothesis by comparing its statistic with the αα level critical value of the statistic for the overall hypothesis. This is called a Simultaneous Test Procedure (STP for short) as all hypotheses may be tested simultaneously and without reference to one another. An STP involves no stepwise testing of the kind employed by some other methods of multiple comparisons for means, in which subsets are tested for equality only if they are contained in sets which have already been found significant. (See [3], [4], [10], [18]). ”
后来又查到一些,我现在觉得Simultaneous Tests就是指同步检验(同时进行多个检验),而进行同步检验的时候会遇到多重比较的问题,再用glht函数的时候,通过设定test=adjusted(“”)来指定多重比较校正的方法,glht函数默认的是one-step方法,我这里用的是fdr的方法。在前文中提到post hoc常用的一个方法是Tukey HSD,那么用glht的one-step与Tukey HSD有什么联系呢?有个人是这么说的:
library(lsmeans)
lsmeans(m1, pairwise~Name.Origin, adjust="tukey")
library(multcomp)
summary(glht(m1, lsm(pairwise~Name.Origin)))
simple.glht(mod, effect, corr = c("Tukey","Bonferroni","Fisher"),
level = 0.95, ...)
“If you specify
adjust = "mvt"in thelsmeanscall, you'll get exactly the same results as the glht call (except for minor differences due to the fact that the computations are simulation-based). The difference would come if you summarize the tests in theglhtobject with some option other than the one-step method (which is the default). The one-step method protects the error rate for simultaneous confidence intervals, which is stronger (and hence more conservative) than the step-down methods. The mvt method is the exact one-step method when the distributional assumptions hold.Also, in a nicely balanced experiment with homogeneous errors, there is no difference between the Tukey method and the mvt method. That is, the Tukey method is the mvt method for the particular covariance structure encountered in such a balanced design.”
此外,我意外发现可以直接用 TukeyHSD(model) 进行posthoc.
从The Handbook for Biological Statistics中更全面的了解到用R做post hoc的一些方法(最初看这些方法不是太懂,配合前文截屏拷贝的那篇文章看会更明白一些)
Tukey and Least Significant Difference mean separation tests (pairwise comparisons)
Tukey and other multiple comparison tests can be performed with a handful of functions. The functions TukeyHSD, HSD.test, and LSD.test are probably not appropriate for cases where there are unbalanced data or unequal variances among levels of the factor, though TukeyHSD does make an adjustment for mildly unbalanced data. It is my understanding that the multcomp and lsmeans packages are more appropriate for unbalanced data. Another alternative is the DTK package that performs mean separation tests on data with unequal sample sizes and no assumption of equal variances.