hive经典例题(持续更新)
hive经典例题
- hive的项目实战
- https://blog.csdn.net/Kevin__Durant/article/details/101115361
每个用户的连续登陆的最大天数
uid,date
1,2019-08-01
1,2019-08-02
1,2019-08-03
2,2019-08-01
2,2019-08-02
3,2019-08-01
3,2019-08-03
4,2019-07-28
4,2019-07-29
4,2019-08-01
4,2019-08-02
4,2019-08-03
select //4.取每个用户的最大的连续访问次数
rank_groupsame.uid,
max(rank_groupsame.cou)
from
(
select //3.按照新的date列和id列进行分组然后取count,就得到了有连续的所有值
rank_same.uid,
rank_same.datee,
count(*) cou
from
(
select //2.实现将日期列减去排名的rank值,就能得到相同的日期列,相同证明连续
rank_sub.uid,
date_sub(rank_sub.datee,rank_sub.rank) datee
from
(
select //1.实现将不同用户的访问日期排序
uid,
datee,
row_number() over(partition by uid order by datee) rank
from sub25
)rank_sub
)rank_same
group by rank_same.uid,rank_same.datee
)rank_groupsame
group by rank_groupsame.uid;
求每个用户的最大连续登录天数
求每个用户的最大连续的登录天数
unix_timestamp 获取当前时间戳 select unix_timestamp();
from_unixtime 时间戳转日期
log_time uid
2018-10-01 12:34:11 123
2018-10-02 12:34:11 123
2018-10-02 12:34:11 456
2018-10-04 12:34:11 123
2018-10-04 12:34:11 456
2018-10-05 12:34:11 123
2018-10-06 12:34:11 123
select //5.取每个用户的最大的连续访问次数
sub_result.uid,
max(sub_result.cou)
from
(
select //4.按照新的date列和id列进行分组然后取count,就得到了有连续的所有值
sub_same.uid,
count(sub_same.same_date) cou
from
(
select //3.实现将日期列减去排名的rank值,就能得到相同的日期列,相同证明连续
sub_rank.uid,
date_sub(sub_rank.datee , sub_rank.rank) same_date
from
(
select //2.实现将不同用户的访问日期排序
sub_date.uid,
sub_date.datee,
row_number() over(partition by sub_date.uid order by sub_date.datee) rank
from
(
select //1.将全格式日期格式化为日期
s.uid,
from_unixtime(unix_timestamp(s.log_time),'yyyy-MM-dd') datee
from sub20 s
) sub_date
) sub_rank
) sub_same
group by sub_same.uid,sub_same.same_date
) sub_result
group by sub_result.uid
连续7天登录的总人数
数据:
t1表
Uid dt login_status(1登录成功,0异常)
1 2019-07-11 1
1 2019-07-12 1
1 2019-07-13 1
1 2019-07-14 1
1 2019-07-15 1
1 2019-07-16 1
1 2019-07-17 1
1 2019-07-18 1
2 2019-07-11 1
2 2019-07-12 1
2 2019-07-13 0
2 2019-07-14 1
2 2019-07-15 1
2 2019-07-16 0
2 2019-07-17 1
2 2019-07-18 0
3 2019-07-11 1
3 2019-07-12 1
3 2019-07-13 1
3 2019-07-14 1
3 2019-07-15 1
3 2019-07-16 1
3 2019-07-17 1
3 2019-07-18 1
select
count(*)
from
(
select
sub_same.uid,
count(*)
from
(
select
sub_rank.uid,
date_sub(sub_rank.dt,sub_rank.rank) date_same
from
(
select
sub_login.uid,
sub_login.dt,
row_number() over(partition by sub_login.uid order by sub_login.dt) rank
from
(
select
s.uid,
s.dt
from sub4 s
where s.login=1
) sub_login
) sub_rank
) sub_same
group by sub_same.uid,sub_same.date_same
having count(*)>=7
) sub_result;
经典表格变形
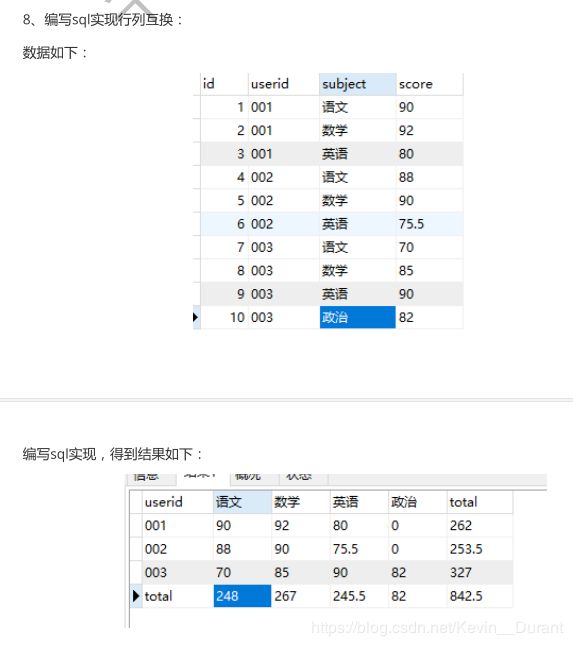
id uid subject score
1 001 语文 90
2 001 数学 91
3 001 英语 80
4 002 语文 88
5 002 数学 90
6 002 英语 75.5
7 003 语文 70
8 003 数学 85
9 003 英语 90
10 003 政治 82
----先得到中间那块行转列的表(methon1)
select uid
,max(case when subject = '语文' then score else 0 end) as Chinese
,max(case when subject = '数学' then score else 0 end) as Math
,max(case when subject = '英语' then score else 0 end) as English
,max(case when subject = '政治' then score else 0 end) as politics
from sub8
group by uid
----先得到中间那块行转列的表(methon2)
----得到科目和成绩的list
create view sub8_v1 as
select uid,
collect_list(subject) sub,
collect_list(score) score
from sub8
group by uid;
uid sub score
1 ["语文","数学","英语"] [90.0,91.0,80.0]
2 ["语文","数学","英语"] [88.0,90.0,75.5]
3 ["语文","数学","英语","政治"] [70.0,85.0,90.0,82.0]
----匹配得到转换的表
create view sub8_v2 as
select
uid,
case when array_contains(sub,"语文") then score[0] else 0 end as chinese,
case when array_contains(sub,"数学") then score[1] else 0 end as math,
case when array_contains(sub,"英语") then score[2] else 0 end as english,
case when array_contains(sub,"政治") then score[3] else 0 end as politics
from sub8_v1
1 90.0 91.0 80.0 0.0
2 88.0 90.0 75.5 0.0
3 70.0 85.0 90.0 82.0
----算出每行的sum
create view sub8_v3 as
select s.*,(chinese+math+english+politics) total
from sub8_v2 s;
1 90.0 91.0 80.0 0.0 261.0
2 88.0 90.0 75.5 0.0 253.5
3 70.0 85.0 90.0 82.0 327.0
----算出每列的sum,有一个细节total用concat充当就行
create view sub8_v4 as
select concat('total',"") uid,
sum(chinese) chinese,
sum(math) math,
sum(english) english,
sum(politics) politics,
sum(total) total
from sub8_v3;
total 248.0 266.0 245.5 82.0 841.5
----union
select * from sub8_v3
union
select * from sub8_v4;
↑↑↑↑↑↑↑↑↑//上面的每一步分开创建了视图做的
↓↓↓↓↓↓↓↓↓//下面是将上三行放一块以最后面的union
create view sub8_v1 as
select s3.*,(s3.chinese+s3.math+s3.english+s3.politics) total
from
(
select
s2.uid,
case when array_contains(s2.sub,"语文") then score[0] else 0 end as chinese,
case when array_contains(s2.sub,"数学") then score[1] else 0 end as math,
case when array_contains(s2.sub,"英语") then score[2] else 0 end as english,
case when array_contains(s2.sub,"政治") then score[3] else 0 end as politics
from
(
select s.uid,
collect_list(s.subject) sub,
collect_list(s.score) score
from sub8 s
group by s.uid
)s2
)s3
select * from sub8_v1
union
select concat('total',"") uid,
sum(chinese) chinese,
sum(math) math,
sum(english) english,
sum(politics) politics,
sum(total) total
from sub8_v1;
匹配填鸭
数据:
t1表
id course
1,a
1,b
1,c
1,e
2,a
2,c
2,d
2,f
3,a
3,b
3,c
3,e
根据编写sql,得到结果如下(表中的1表示选修,表中的0表示未选修):
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 0
1 ["a","b","c","e"]
2 ["a","c","d","f"]
3 ["a","b","c","e"]
create table course(
id,int
course string
)
row format delimited
fields terminated by ','
;
create view sub14_v1 as
select id,collect_list(course) own
from sub14
group by id;
select id,
case when array_contains(own,'a') then 1 else 0 end as a,
case when array_contains(own,'b') then 1 else 0 end as b,
case when array_contains(own,'c') then 1 else 0 end as c,
case when array_contains(own,'d') then 1 else 0 end as d,
case when array_contains(own,'e') then 1 else 0 end as e,
case when array_contains(own,'f') then 1 else 0 end as f
from sub14_v1;
多列转为行形式:
| date | uv | newuv | video | newvideo | vv | vip_num | new_vip_num |
|---|---|---|---|---|---|---|---|
| 2019-05-10 | 5000000 | 200000 | 3000000 | 10000 | 20000000 | 500000 | 80000 |
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
| date | label | value |
|---|---|---|
| 2019-05-10 | UV | 5000000 |
| 2019-05-10 | 新增UV | 200000 |
| 2019-05-10 | 视频存量 | 3000000 |
| 2019-05-10 | 新增视频 | 10000 |
| 2019-05-10 | 播放量 | 20000000 |
| 2019-05-10 | 会员数 | 500000 |
| 2019-05-10 | 新增会员数 | 80000 |
使用lateral view explode内部嵌套map
select
res.datee,
res.label,
res.value
from
(
select *
from dai
LATERAL VIEW explode (map(
'UV', uv
,'新增UV', newuv
,'视频存量', video
,'新增视频', newvideo
,'播放量', vv
,'会员数', vip_num
,'新增会员数', new_vip_num
)) b as label, value
) res
级联求和
编写sql答案
数据:
userid,month,visits
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,1
每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数,结果数据格式如下:
----先算出每个用户每个月的访问量为一张表
create view wen_1
as
select w.uid ,w.month,sum(w.visits) sum_vis
from wen w
group by w.uid ,w.month
;
----窗口函数求出后两个字段(最大单月访问次数和累计总访问次数)
select w.uid,
w.month,
w.sum_vis,
max(w.sum_vis) over(partition by w.uid order by w.month asc) ,
sum(w.sum_vis) over(partition by w.uid order by w.month asc rows between unbounded preceding and current row)
from wen_1 w;
下面为合并书写↓↓↓↓↓↓↓↓↓↓↓↓↓
select w.uid,
w.month,
w.sum_vis,
max(w.sum_vis) over(partition by w.uid order by w.month asc) ,
sum(w.sum_vis) over(partition by w.uid order by w.month asc rows between unbounded preceding and current row)
from
(
select w.uid ,w.month,sum(w.visits) sum_vis
from wen w
group by w.uid ,w.month
) w;
A 2015-01 33 33 33
A 2015-02 10 33 43
A 2015-03 38 38 81
B 2015-01 30 30 30
B 2015-02 15 30 45
B 2015-03 34 34 79
统计两个人的通话总时长(用户之间互相通话的时长)
Zhangsan Wangwu 01:01:01
Zhangsan Zhaoliu 00:11:21
Zhangsan Yuqi 00:19:01
Zhangsan Jingba 00:21:01
Zhangsan Wuxi 01:31:17
Wangwu Zhaoliu 00:51:01
Wangwu Zhaoliu 01:11:19
Wangwu Yuqi 00:00:21
Wangwu Yuqi 00:23:01
Yuqi Zhaoliu 01:18:01
Yuqi Wuxi 00:18:00
Jingba Wangwu 00:02:04
Jingba Wangwu 00:02:54
Wangwu Yuqi 01:00:13
Wangwu Yuqi 00:01:01
Wangwu Zhangsan 00:01:01
----将两列名字有相同的翻转为顺序相同
create view tonghua_v1 as
select
case when t.name>t.name2 then concat(t.name,' ',t.name2) else concat(t.name2,' ',t.name) end name,
timee
from tonghua t
----将时间累加
----获取需要统计的时间的时间戳,然后需要减去默认时间戳的时间,做聚合,最后再减掉多出的时间戳
select
t2.name,
from_unixtime(sum(unix_timestamp(t2.timee,'HH:mm:hh')-unix_timestamp("00:00:00",'HH:mm:hh'))+unix_timestamp("00:00:00",'HH:mm:hh'),"HH:mm:hh") timee
from tonghua_v1 t2
group by t2.name
----合并操作
select
t2.name,
from_unixtime(sum(unix_timestamp(t2.timee,'HH:mm:hh')-unix_timestamp("00:00:00",'HH:mm:hh'))+unix_timestamp("00:00:00",'HH:mm:hh'),"HH:mm:hh") timee
from
(
select
case when t.name>t.name2 then concat(t.name,' ',t.name2) else concat(t.name2,' ',t.name) end name,
timee
from tonghua t
) t2
group by t2.name
引:给大家引两个博客供新学习hive函数的同学使用:
https://www.iteblog.com/archives/2258.html
https://www.cnblogs.com/wakerwang/p/9503056.html