FPGA-PCIe开发
/*Ver. 1.0*/
说在前面:在接触PCIe之前学习了点DDR3的理论知识,在Xilinx的V709上跑了一遍例程,自己也例化了MIG核通过控制逻辑实现了简单的DDR3读写数据,这部分内容分享在新浪博客里边,这里就不累赘重述了,此博客单单是总结、记录在接触PCIe后从一只小白到一只菜鸟的进阶过程(难免有些没记录到,希望可以CSDN的博客能支持续编辑)。感谢CC师姐,LH师兄,DM师兄还有实验室小伙伴,特别感谢EETOP的XD前辈,感谢你们的指点。
环境说明:PCIe总线版本gen2_x1lane(前期是gen2_x4lane);PCIe开发平台Vivado2017.02(前期是2016.02);仿真平台Modelsim10.5(前期是10.4);芯片型号及封装形式Xilinx-xc7a100t-fgg484(前期是Xilinx-xc7z045-fgg900);PCIe驱动开发环境X86(前期是用WinDriver作一些BAR空间寄存器1dw数据的简单读写)
博客纲要:
- 1.入门——1.1.理论入门——1.2.实践入门
- 2.进阶——进阶中遇到的问题
- 3.提高——3.1.性能提高——3.2.提高中遇到的问题
- 4.简单描述DMA读写流程
一.入门
1.1.理论入门
网上有很多关于PCIe入门的理论知识,比如各种包的定义,PIO和DMA等相关知识,我也就跳过了,只在这里说点重要的。
首先,必须必备的当然是PCIe总线规范“PCI Express Base Specification Revision 3.0”(860Pages)了,毕竟这是PCIe的根本规范嘛,类似的一本书是“PCI Express System Architecture”(1109Pages),,,我猜你们也是只有遇到问题时才会看的,其实我也还没看完。
其次,推荐一本书“PCI Express体系结构导读 王齐著”这就是PCIe规范大致翻译成中文版了,也是我看的正经书籍之一,对我的PCIe开发帮助很大。
最后,推荐一些关于理论入门博客及相关内容。链接1:http://lib.csdn.net/article/deeplearning/53873(此博主总结了理论入门还有我接下来要提及的实践入门);链接2:https://wenku.baidu.com/view/d890041b59eef8c75fbfb3ff.html(此文档PCIe入门必读,优质内容);链接3:http://www.ssdfans.com/?p=3683(此博主相较于链接一的博主更加侧重讲述了各种TLP包);当然一些PCIe的速率性能就链接4:https://en.wikipedia.org/wiki/PCI_Expres(Wiki)自行科普吧。
1.2.实践入门
既然是入门,那就从简单的搞起,PIO(Programmed Input-Output)模式就是PCIe的简单入门,PIO模式下可以实现在PCIe总线上读写32bit(1DW=4Byte=32bit)数据。要说明的是PIO模式所用的总线标准是AXIS总线。
怎么实现呢?用Vivado2017.02建一个PCIe IP(7 Series Integrated Block for PCI Express ver.3.3)核,然后右键IP核选择“generate example design”,这样Vivado基于这个IP核新建了一个工程,此工程含有PIO功能的仿真和测试文件,详细的模块描述和仿真分析在1.1章中的链接1中,其PIO读写操作大致流程是RX模块接收到RC侧(直接理解成PC也无大错)发来的带32bit数据写请求包MWR,然后EP侧将其存储在MEM模块,然后RX模块又接收到RC侧发来的不带数据的读请求包MRD,EP侧将MEM模块存储的数据封装成读完成包CplD响应收到读请求包,将数据返还RC侧。仿真的话,如果是用Vivado2016.02的话联调Modelsim10.4,用Vivado2017.02的话联调Modelsim10.5,只要编译的库没有问题,那么设置Modelsim仿真时长为150us(user_link_up拉高)就能看到完整的PIO流程。
关于example design中PIO模式更详细的官方说明可以Xilinx官网下载pg054(英文版),或链接5:http://www.docin.com/p-1964324614.html(中文版),下图1是2016.2平台PCIe核example design工作在PIO模式下的仿真结果:

图1:PIO模式下PCIe IP核example design仿真结果
二.进阶
单次PIO操作只能搬运32bit,效率低,而且还会占用CPU总线权,所以我们要使用DMA模式,最开始接触到的是Xilinx官网给的一份PCIe工作在DMA模式下的例程:xapp1052,例程虽然只是用于测试PCIe性能(该不足见链接6:http://xilinx.eetrend.com/blog/9829),但是好在它的模块划分很清晰,相关理论文章博客也不少,重点推荐两三个,链接7:https://blog.csdn.net/lutianfeiml/article/details/51035756(此博主对比了PIO和DMA,并介绍了DMA读写流程);链接8:https://www.cnblogs.com/yuzeren48/p/3896138.html(按照此博主的步骤可以实现1052例程的板级验证)
关于进阶部分我提一下注意事项:
2.1.例程适用性评估
xapp1052开发环境是win XP和win 32,而项目要求是在win32上实现,故参考此例程并无问题。
2.2.xapp1052安装自带的上位机报错
该上位机仅仅是用于测试性能,同一个32bit数据Pattern进行在TX模块封装成写请求包DMA写至PC,接着TX模块读请求,读取PC缓存的数据,最后RX模块接收来自PC的读完成包,拆包对比每个数据是否为Pattern,若是则error为“0”。刚开始安装上位机时会报错,打开“oemsetupXP.inf”文件,里边有句这样的描述“[AVNET.Board] %Driver%=AVNET.Install, PCI\VEN_10EE&DEV_0007”,我就怀疑是这驱动的设备ID和我例化PCIe核填写的设备ID不吻合导致安装报错,将“DEV_0007”改为“DEV_7024”(此设备ID为例化IP核配置的参数之一)后安装成功了,窃喜0.0,运气好。
2.3.PC检测不到板卡
这个问题调试过PCIe的基本都遇到过,比较头疼,检测不到板卡就无法抓信号,连错在哪都难以定位,这是项目初期PCIe接口部分用的是ZC706平台,考虑到此开发板娇(较)贵,将工程移植到A7平台上,可是PC检测不到板卡了,后来仔细对比Z706工程下的xdc和A7工程下的xdc,两者基本毫无差别,只是为适应新板子把有些电平改了些,引脚也参考了新板子所带的例程来弄,再后来就研究A7板子的结构图和原理图,对比后发现A7板子PCIe采用的是gtp高速通道,而Z706板子PCIe采用的是gtx高速通道。得亏师姐仔细,找到了IP核的xdc(PCIe核可以理解为硬核,出错的引脚在例化时已经布完,我们在顶层xdc写PCIe的管脚/通道约束都无用)有个bug,下面我们对比一下A7工程例化IP核后的核xdc。
 图2.异常IP核xdc通道约束
图2.异常IP核xdc通道约束
 图3.正常IP核xdc通道约束
图3.正常IP核xdc通道约束
对比可以看出,lane0/1约束出错导致PC检测不到板卡。这个bug可能是因为新板子不是Xilinx官方的a7开发板,导致其约束与IP核默认的约束存在出入。总之,以后每次新例化IP核都得修改IP核的xdc,而且在项目后期为了降速,只使用了lane0,曾试过只用lane3(通道约束X0Y7),奈何未通。
2.4.INT-x中断
xapp1052使用的是INT-x中断,MEM模块偏移48h设置了中断状态寄存器,可是驱动并没有在DMA读写结束后对中断状态寄存器的legancy_clr位写“1”进行中断清理,所以第一次DMA结束后一直收到中断。下面我们对比一下两者的时序。
 图4.异常INT-x中断时序
图4.异常INT-x中断时序
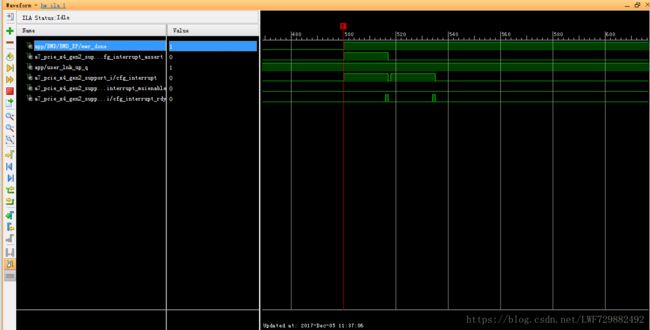 图5.正常INT-x中断时序
图5.正常INT-x中断时序
对比可以看出,异常INT-x中断时序缺少“清理中断”部分,发现这一点着实不易,最后是在看链接2"PCIe Solution on Xilinx FPGAs初学者指南v1.0"中关于中断部分描述了Legacy和MSI两种时序中才发现了自己原来错误的想法,原先错以为图4是正确时序,错误理解EP只负责发中断,一个脉冲就产生一次中断。后续修改中把xapp1052驱动中添加了对中断状态寄存器的使用,并且硬件侧在板卡复位是对各种中断信号复位清零,工程就能正常了。
/*补充說明:2018-6-5 17:00:13 关于这个置中断和清中断时序,硬件在产生置中断时序后,用户模块输出的cfg_interrupt和PCIe IP核输出的cfg_interrupt_rdy握手成功则把INTA电平拉高,但是图5的时序中,清中断紧接着置中断,所以驱动往往“捕捉”不到这次清中断时序,驱动DebugView打印清中断未操作成功,一直跳入读中断状态寄存器,但是中断状态寄存器的值为全0。为此,驱动收到中断后,硬件检测到驱动在读中断状态寄存器时自行拉高legacyclr信号产生清中断时序,该信号的复位是跟着三种中断源标志位一起*/
2.5.xapp1052单次DMA读操作只能传输1DW Payload
这个问题是初期遇到的,超过1DW时会报cpld_data_error错误,所抓信号时序见下图。
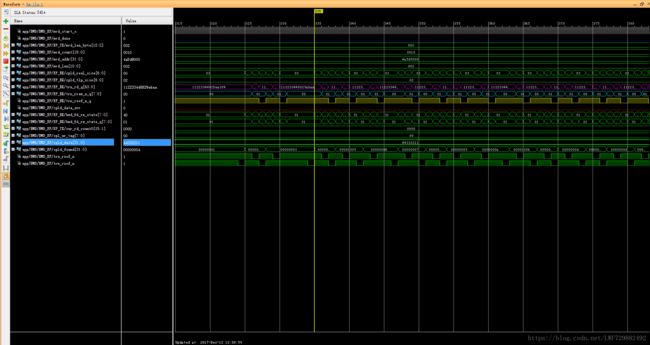 图6.DMA读操作单个读完成TLP包只能承载1DW的数据
图6.DMA读操作单个读完成TLP包只能承载1DW的数据
顺着此信号我发现AXIS总线和locallink总线在进行总线转换时信号trn_rrem_n位宽不匹配,进入到用户模块的是8'h01,而接口模块断言条件是8'h0f。在该模块进行如下修改:
assign trn_trem_n = (trn_trem == 8'h0F) ? 1'b1 : 1'b0;
assign trn_rrem = (trn_rrem_n == 1'b1) ? 8'h00 : 8'h0F; 问题解决。
三.提高
3.1.性能提高
性能的提高是基于xapp1052例程已经添加了存储模块和中断模块。PCIe接口最后要达到的要求是板卡侧作为主动方通过中断发起读写操作且告知PC下发多少数据(DMA读操作)以及上传多少数据(DMA写操作),为达到这个效果,我们需要开辟中断状态寄存器中的某几位用于标识读开始中断或者是写开始中断,,,当驱动收到中断后就会PIO读中断状态寄存器,断言不同的中断类型跳入不同的中断服务程序。
3.2.提高中遇到的一些问题
3.2.1.能收到写完成中断,缓存区却无数据
传输64DW、256DW、512DW能收到写完成中断,Size取64DW时,PC缓存区无数据,抓取信号trn_td[63:0]有封装写请求包说明板卡侧发送了数据。部分测试情景信号时序图见下。
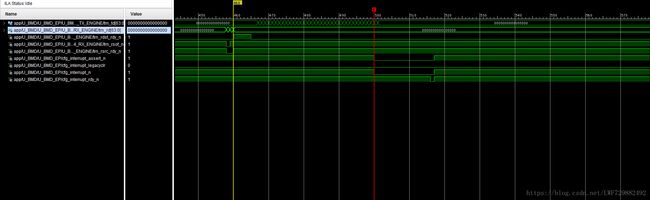 图7.64DW(Size64DW)时序图
图7.64DW(Size64DW)时序图
 图8.512DW(Size64DW)时序图
图8.512DW(Size64DW)时序图
通过读取40h(Reg#16)得知,cfg_max_rd_req_size=010,即512B,说明读请求包最大可请求512B;cfg_prg_max_payload_size=000,即128B,这说明带数据的读完成包和带数据的写请求包最大有效负载为128B。而PCIe驱动处在DMA写操作时直接令最大读请求大小等于最大有效负载大小,虽然板卡侧有封装256B数据,但是由于RC的MPS为128B导致DMA写操作异常,数据并未存下PC缓存中。

图9.协商后的Programmed MPS值
下表对比说明了最大有效负载与最大读请求两个参数:
| 参数 |
最大有效负载大小(Maximum Payload Size, MPS) |
最大读请求大小(Maximum Read Request Size, MRRS) |
| 描述 |
控制单个TLP包可以传输的最大数据长度(B)。作为接收方,必须能处理跟MPS设定大小相同的数据包;作为传输方,不允许封装超过MPS设定的TLP数据包。 |
Read Request Size可以大于MPS,比如测试中MPS=128B,而发的MRRS=256B,此时主机通过返回2个128B的Cpld来响应读请求 |
| 流向 |
PCIe IP核输出的设备控制寄存器cfg_dcommand[7:5],引入MEM模块供主机PIO读,其值为3'b000(128B) |
PCIe IP核输出的设备控制寄存器cfg_dcommand[14:12],引入MEM模块供主机PIO读,其值为3'b010(512B) |
| 备注 |
128B指的是主机与板卡协商后的Programmed MPS值,PCIe IP核配置的MPS是512B |
无 |
因为Programmed MPS限制,DMA写操作Size最大设置为32DW可解决问题。为了佐证此现象,“ PCI Express体系结构导读”一书中P305提及:“在LogiCORE中,Max_Payload_Size Supported参数的最大值为512B。但是链路两端经过协商后,实际确认的Max_Payload_Size参数可能小于512B,在多数x86处理器系统中,该参数为128B(即32DW)”
3.2.2.读完成包乱序返回问题
这个问题是不可避免的,PCIe总线规范中允许这种情况发生,xapp1052例程中未处理此问题,不同的主机乱序程度不一,下图为乱序情况截图。

图10.读完成包接收数据乱序
为解决乱序/拆包问题,采用“ PCI Express体系结构导读”一书中P308提及的单向循环链表思想,因为是小规模乱序,我们如果检测到后边的包提前到来时我们将此tag的包先作存储,每个tag开辟了512B(最大载荷)的空间,等收齐该tag的所有数据释放tag资源。因为我只负责tag乱序检查模块,其余主要是师姐处理,所以描述的不够详细,后续有时间再作补充。
3.2.3.DMA写因发送缓存不够触发IP核流控机制
在数据量一定的情况下,当设置的size过小时,count自然就多,然而IP核内部的发送缓存空间为30个最大Payload写请求包,虽然发送期间发送缓存会有一段动态平衡时期,但是写请求包数量巨大时,IP核发包速率低于TX模块封包速率就轻易地触发了IP核发送缓存的流控机制,详细时序见下图。
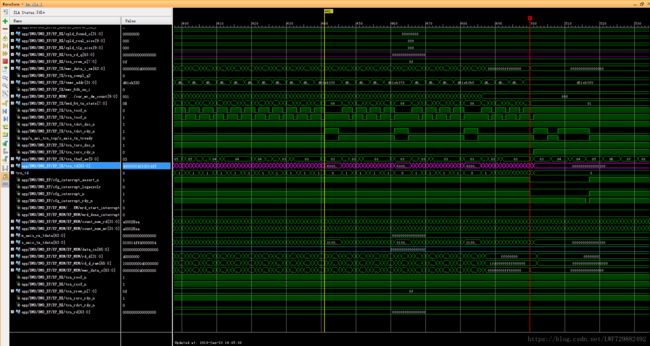 图11.IP核发送缓存不足触发流控,trn_tdst_rdy_n信号拉高标题
图11.IP核发送缓存不足触发流控,trn_tdst_rdy_n信号拉高标题
为解决此问题,我们需要通过trn_tdst_rdy_n信号进行一系列的时序逻辑和组合逻辑,“凑”出从上行接收FIFO中取数据的rd_en信号,否则写回去的数据在流控期间丢失,发送的数据量不足而不能产生写完成中断。
3.2.4.数据存储
要将xapp1052实际应用起来最大的难点还是数据存储,因为数据总是以1DW+2DW+..+2/1DW的形式传过来,那么在存储是就必要考虑到是该存储其低32位还是64位,使能信号是必须的。同样的,在写回去时封装写请求TLP包要从FIFO中取出32位数据拼接成64位数据,封装写请求包。牵扯到跨时钟域,FIFO数据的拼/拆。
四.总结PCIe DMA读写流程(假定4DW*4TLP)
4.1.DMA读流程
PIO写操作往00h寄存器写入0x03进行板卡复位和计数复位;
PIO写操作往00h寄存器写入0x00清理板卡复位和计数复位;
PIO读操作读取00h寄存器的值,trn_td[63:0]封装两次00h寄存器值反馈读完成包;
……
PIO读操作读取24h寄存器的值,trn_td[63:0]封装两次24h寄存器值反馈读完成包;
PIO写操作往1ch寄存器写入0x0000e2d5,DMA读起始地址;
PIO写操作往20h寄存器写入0x04,DMA读Size;
PIO写操作往24h寄存器写入0x04,DMA读Count;
PIO写操作往18h寄存器写入0x78563412,此操作可省略,数据Pattern;
PIO读操作读取04h寄存器的值,trn_td[63:0]封装两次04h寄存器值反馈读完成包;
PIO写操作往04h寄存器写入0x04,DMA读开始标志位置1;
//trn_td[63:0]根据Size/Count封装DMA读请求TLP包
收到PC返回的读完成包(TLP#1)4DW;
收到PC返回的读完成包(TLP#2)4DW;
收到PC返回的读完成包(TLP#3)4DW;
收到PC返回的读完成包(TLP#4)4DW;
//cfg_interrupt_*_n相关信号,读完成中断时序
PIO写操作往48h寄存器写入0x100,清理读完成中断
PIO写操作往00h寄存器写入0x03进行板卡复位和计数复位;
PIO写操作往00h寄存器写入0x00清理板卡复位和计数复位;
4.2.DMA写流程
PIO写操作往00h寄存器写入0x03进行板卡复位和计数复位;
PIO写操作往00h寄存器写入0x00清理板卡复位和计数复位;
PIO读操作读取0ch寄存器的值,trn_td[63:0]封装两次0ch寄存器值反馈读完成包;
PIO读操作读取10h寄存器的值,trn_td[63:0]封装两次10h寄存器值反馈读完成包;
PIO写操作往08h寄存器写入0x0000e2d5,DMA写起始地址;
PIO写操作往0ch寄存器写入0x04,DMA写Size;
PIO写操作往10h寄存器写入0x04,DMA写Count;
PIO写操作往14h寄存器写入0x78563412,此操作可省略,数据Pattern;
PIO写操作往04h寄存器写入0x40,DMA写开始标志位置1;
//trn_td[63:0]根据Size/Count封装DMA写请求TLP包:
//发送给PC写请求包(TLP#1)4DW;
//发送给PC写请求包(TLP#2)4DW;
//发送给PC写请求包(TLP#3)4DW;
//发送给PC写请求包(TLP#4)4DW;
//cfg_interrupt_*_n相关信号,写完成中断时序
PIO写操作往48h寄存器写入0x100,清理写完成中断
PIO写操作往00h寄存器写入0x03进行板卡复位和计数复位;
PIO写操作往00h寄存器写入0x00清理板卡复位和计数复位;
(ps:整理了一下午,难免遗漏,后续补充,第一次CSDN,排版待改进)
/*End for Ver. 1.0 2018-3-30 19:43:27*/
---------------------------------------------------分----割----线------------------------------------------------------------
/*Ver. 2.0 补充了后边调试中断部分遇到的问题*/
首先説明,目前使用的中断类型还是INT-x中断,准确的来说是INTA中断,这是一种共享式中断,在后边调试过程中遇到了中断重叠的问题。文字描述如下:DMA读操作的启动是驱动决定的,所以DMA读完成中断信号mrd_done_interrupt什么时候拉高不是由硬件决定的,而DMA写开始中断信号mwr_start_interrupt是硬件在检测到上一次DMA写操作结束(PCIe控制器将总线权交还給主机)且写中断FIFO非空时产生。开始时未规避中断重叠的问题,在写开始中断发出后拉高INTA电平,驱动还未将写开始中断复位又来了读完成中断,又有一次置中断时序,但是此时INTA已经拉高了,驱动未能感知到第二次的读完成中断,所以驱动对后续的DMA读写都不能进行。时序见下图12:
 图12.写开始中断和读完成中断重叠导致驱动未能识别到读完成中断标题
图12.写开始中断和读完成中断重叠导致驱动未能识别到读完成中断标题
触发时刻在窗口的前半段,mwr_start_interrupt_ff4就是写开始中断标志位,用来触发中断时序,主机识别了该中断,也进行了写开始中断的复位(下边的intr_wr_start_rst有个高电平复位操作),可是在这之间,mrd_done_o也拉高了,也会产生中断时序,驱动前边收到写开始中断时读取中断寄存器的值时,DMA读操作还没结束,读完成中断标志位还未拉高,所以驱动认为这是个写开始中断,硬件这边mrd_done_o拉高也有中断时序給主机,但是和那个写开始的重叠在一起了,主机默认只收到了一次中断,因为写开始中断标志位先置1了,所以以为这里只有写开始,驱动稍微晚一点读中断寄存器的话就会发现其读完成中断标志位也是1。在这样驱动就没收到读完成中断,导致驱动那边后续的DMA读写操作都不能执行了。
要解决此问题,我想到的是可以在清理中断后再看看中断状态寄存器中有没有其他中断源标志位还是为置1状态,有的话说明有中断重叠了。比如在写开始和读完成重叠的时序图中,驱动处理完写开始中断后,及时通过mwr_start_rst对mwr_start_interrupt进行复位,然后硬件再检测是否还有其他标志位(如读完成标志位)有效,如果有,则再次产生置中断时序,拉高INTA电平,此时驱动会再次收到中断,读中断状态寄存器的值时可以识别出读完成标志位为“1”。
/*End for Ver. 2.0 2018-6-5 16:56:06*/
---------------------------------------------------分----割----线------------------------------------------------------------
/*Ver. 3.0 补充了后边调试DMA写部分遇到的问题*/
首先大致介绍一下关于DMA写的完整流程,见下图13
 图13.DMA写完整流程图
图13.DMA写完整流程图
流程图文字描述:数据接收FIFO缓存从网口接收到32bit的数据,当收到一定量时将此刻收到的数据量(B)写入到写中断FIFO中,PCIe部分检测到写中断FIFO非空拉高一个读使能脉冲,并根据读使能脉冲产生DMA写开始中断,写中断FIFO中取出来此次DMA写要上传的数据量wr_intr_length[15:0]递交给ASYNC_FIFO_TO_TX_ENGINE模块,该模块根据字节数控制数据接收FIFO的读使能sync_fifo_rd_en拉高多少个钟,确保不多读数据也不少读数据,从数据接收FIFO中取到的数据sync_fifo_data[31:0]在ASYNC_FIFO_TO_TX_ENGINE模块完成数据拼接,两个32位数据拼接成一个64bit数据tx_data_r[63:0],写入FETCH_FIFO中,检测到此刻是在DMA写过程中就拉高FETCH_FIFO的读使能,将读出来的数据tx_data[63:0]封装成写请求包。需要注意的是在SIZE取32DW时,写请求包的第一个钟的trn_td和最后一个钟的trn_td是只有32bit有效的。
问题描述:驱动端接收到来自板卡的写请求包后将Payload数据存储在DMA缓冲区,进行拆帧处理,检测每一个帧的帧头字段和其实际帧长是否相对应,比如此次收到10000B,确认了帧头标识后,帧长信息指示帧长是1500B,驱动取后边1500B后再看紧接着第二个帧的帧头标识,第二个帧的帧长信息,驱动取后边相应数据量。。。驱动检测到第一个帧取完后未检测到第二个帧的帧头标识,说明驱动收到的数据有误,驱动将丢弃此次DMA写操作后边的所有数据,报错“The Recv Frame Headwrong”。
原因猜测:PCIe体系中强调DMA写请求包是严格按序到达的,所以我们暂定TX_ENGINE发送的写请求trn_td到达主机是不会乱序的。那么原因往前推,做出以下猜测:
1)读完成包乱序到达,恰好某一帧的帧头标识字段和后边的payload数据出现交换。此原因后边排除了,因为如果DMA读下来的数据出现这种错误,就不可能从发送模块出来递交給接收模块,既然接收模块能收到这一帧数据,说明数据在DMA读阶段的顺序并未出现错乱,或者出现错乱,但是经过乱序检查+重排序模块后能正确输出到接收模块。
2)从数据接收FIFO读出来的数据有问题,某一个帧的帧头标识后的帧长字段和实际帧长payload字节数不匹配。为了验证这个原因,我们将写入数据接收FIFO的数据(以及从数据FIFO中读出来的数据sync_fifo_data[31:0])镜像一份输入到up_frame_check模块过一遍,该模块严格识别帧长字段,根据帧长字段取相应的数据量,紧接着识别下一帧的帧头标识,帧长字段和取相应的帧字节数... ...如果识别下一个帧没有帧头标识就拉高alarm_flag一个钟,后边上板时发现驱动依旧报错,但是硬件这边并未触发到alarm_flag的上升沿,说明从网口写入数据接收FIFO的数据(以及从数据FIFO读出递交给PCIe ASYNC_FIFO_TO_TX_ENGINE模块的数据)是正确的。
3)既然从数据接收FIFO读出来的数据没问题,那就猜测是ASYNC_FIFO_TO_TX_ENGINE模块对32bit数据进行封装时少封装了部分数据。为了验证这个原因,我们将TX_ENGINE模块62.5MHz下封装的写请求包trn_td[63:0]镜像一份到125MHz的WR_TLP模块下把写请求包中的Payload数据write_data[31:0]提取出来,写入到COPY_FIFO,再读出給up_frame_check模块过一遍。后边上板测试时发现确实抓到一次DMA写操作出问题,alarm_flag信号拉高。
具体分析:既然问题已经定位在从数据接收FIFO到封装成64bit的tx_data_r出问题,在抓到的DMA写操作出错的时序图中,我们对比一下每个TLP请求包(含32DW的payload):数据接收FIFO读出来的数据sync_fifo_data[31:0]、封装在写请求包的数据write_data[31:0]以及帧检测模块输入的数据copy_fifo_data[31:0]。1024个采样点,alarm_flag拉高前的一个帧是1500个字节,按照上述方式对比数据,发现从数据接收FIFO读出来的数据封装成写请求包出现问题,少封装了6个DW,至于为什么丢失了6个DW的数据,是因为在封装DMA写期间来了一个PIO读请求,而封装PIO读完成包的优先级高于封装DMA写请求包,花了3个clk来封装读完成包,。此时ASYNC_FIFO_TO_TX_ENGINE模块还是从FETCH_FIFO里取数据,但是这3个clk的数据读出来并没有封装到DMA写请求包中。
 图14.PIO读期间拉低FETCH_FIFO读使能,暂停取数据
图14.PIO读期间拉低FETCH_FIFO读使能,暂停取数据
解决问题:如上图14所示,我们需要对FETCH_FIFO的读使能作进一步的约束(注:在问题“3.2.3.DMA写因发送缓存不够触发IP核流控机制”中我们已经对该FIFO的读使能进行了一次约束),具体来说,在DMA写期间检测到需要封装PIO读完成包时拉低FETCH_FIFO的读使能pio_rd_en,暂停取数据,直到PIO读完成包封装完毕,TX_ENGINE又回到封装写请求包的状态,此时要拉高pio_rd_en,读最新的数据出来封装。
问题实质:封装PIO读完成包的优先级高于封装DMA写请求包,而数据FIFO的读使能一直为高,导致在封装PIO读完成包期间读出的那部分数据丢失。
/*End for Ver. 3.0 2018-7-9 10:17:36*/