pandas基础
Pandas借鉴了Numpy绝大部分设计思想,但与Numpy不同的是它更适合于处理表格类、异质性数据,而Numpy则是处理同质的数值数组。Pandas还能无缝与Numpy, SciPy, statsmodels, scikit-learn, matplotlib等包联用,构建了Python数据分析生态系统。
Pandas最主要的两类数据结构:Series, DataFrame,可以对应R语言的vector和data.frame,脑图如下

学习笔记如下:
- pandas的索引对象用于存放轴标签和其他元数据信息,索引对象不可修改,目的是安全的将该索对象传递给其他数据结构。、
- reindex并不是修改原来的索引,而会在原来的基础上增加新的索引。
- 对DataFrame或Series修改形状,删除数据的操作默认返回新的数据结构。可以用
inplace=True避免返回新的数据,不过这也通常会摧毁原来的数据。 - 明确
loc和iloc的区别。如果你创建Series或DataFrame的index存在整数,那么细细体会下obj[:1],obj.loc[:1],obj.iloc[:1] - 排序和排名(sort and rank)看起来差不多,毕竟排名先要排序,排序之后分配位置,注意重复值的处理方法。
最重要的部分是描述性统计分析部分,这部分依赖于现有的函数
| 方法 | 说明 |
|---|---|
| desribe | 列计算汇总,列出四分位数等信息 |
| max,min | 最大值和最小值 |
| idxmin, idxmax | 最大值和最小值的索引位置 |
| quantile | 分位数 |
| sum | 求和 |
| mean | 平均数 |
| median | 中位数 |
| mad | 根据平均值计算平均离差 |
| var | 方差 |
| std | 标准差 |
| skew | 样本值的偏度(三阶矩) |
| kurt | 样本值的丰度(四阶矩) |
| cumsum | 样本的累积和 |
| cummin,cummax | 累计最大值和最小值 |
| cumprod | 累积积 |
| diff | 计算一阶差分 |
| pct_change | 计算百分比变化 |
官方文档的教程
此处翻译官方文档的10 Minutes to pandas,有任何问题欢迎留言交流。
本文主要简单的介绍了pandas,让新手能够了解pandas的一些功能,你可以在Cookbook中看到更详尽的内容。
在执行以下的操作前,请先导入相应的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
创建对象
- 通过传入一个包含多个值的列表创建一个Series对象,pands会默认为其创建一个整数索引。
s = pd.Series([1,3,5,np.nan,6,8])
- 通过传入一个含有日期索引和标签列的numpy矩阵创建一个DataFrame对象
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
- 通过传递一个字典创建一个DataFrame
df2 = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
DataFrame和Series具有许多属性,可以利用IPyton的自动补全功能查看:
df2.
df2.A df2.boxplot
df2.abs df2.C
df2.add df2.clip
df2.add_prefix df2.clip_lower
df2.add_suffix df2.clip_upper
df2.align df2.columns
df2.all df2.combine
df2.any df2.combineAdd
df2.append df2.combine_first
df2.apply df2.combineMult
df2.applymap df2.compound
df2.as_blocks df2.consolidate
df2.asfreq df2.convert_objects
df2.as_matrix df2.copy
df2.astype df2.corr
df2.at df2.corrwith
df2.at_time df2.count
df2.axes df2.cov
df2.B df2.cummax
df2.between_time df2.cummin
df2.bfill df2.cumprod
df2.blocks df2.cumsum
df2.bool df2.D
查看数据
- 假设你有上w条数据,全部显示屏幕要爆炸,那么最好的方法就是只看前面几条或后面几条,验证创建的数据模型是否正确。
df.head()
df.tail(3)
- 显示索引,列,和底层numpy的数据
df.index
df.columns
df.values
- 对数据进行快速的统计汇总,这里汇总的数据的数据类型是Int,float这类
df.describe()

-
数据转置
df.T -
按轴排序(ascending:升序)
df.sort_index(axis=1,ascending=False) -
按值排序,类似于excel的排序
df.sort_value(by='B')
筛选
起步
-
选择单列,这会产生一个Series,等同于df.A
df['A'] -
使用[]对行切片
df[0:3]
使用标签筛选
-
使用标签获取切片数据
df.loc[date[0]] -
使用标签获取多轴数据
df.loc[:,['A','B']] -
显示标签切片,包括两个端点
df.loc['20130102':'20130104',['A','B']] -
获取标量值
df.loc[dates[0],'A'] -
快速获取标量值(与上一个作用相同)
df.at[dates[0],'A']
通过位置筛选
-
通过所传递整数的位置选择
df.iloc[3] -
通过整数切片
df.iloc[3:5,2:3] -
通过整数位地址的列表
df.iloc[[1,2,4],[0,2]] -
对行/列切片
df.iloc[1:3,:] df.ilo[:,1,3] -
获得特定值
df.iloc[1,1] -
快速获取标量(与上一个结果相同)
df.iat[1,2]
布尔索引
-
使用单个列的值来选择数据。
df[df.A > 0] -
使用isin()方法进行过滤,下面实现的是筛选E中'tw'和'four'两列
df2 = df.copy() df2['E'] = ['one', 'one','two','three','four','three'] df2[df2['E'].isin(['two','four'])]
赋值
-
为新列赋值,该列能够通过标签自动匹配原先的数据
s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20130102', periods=6)) df['F']=s1 -
通过标签赋值
df.at[dates[0],'A'] = 0 -
通过位置赋值
df.iat[0,1] = 0 -
通过传入一个numy矩阵赋值
df.iat[0,1] = 0
缺失值
pandas优先使用np.nan表示缺失值。缺失值默认在计算中排除。
-
重建索引允许您更改/添加/删除索引上的指定轴。这将返回数据的副本。
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E']) df1.loc[dates[0]:dates[1],'E'] = 1 -
删除任何包含缺失值的行
df1.dropna(how='any') -
填充缺失值
df1.fillna(value=5) -
判断是否为缺失值并返回布尔值
pd.isnull(df1)
操作
统计
- 描述统计
df.mean() 、 df.mean(1)
apply
-
将函数应用到数据上
df.apply(np.cumsum) df.apply(lambda x: x.max() - x.min())
直方图
s = pd.Series(np.random.randint(0, 7, size=10))
s.value_counts()
合并
pandas提供了多种方法方便的合并Series, DataFrame,和Panel对象
Concat
-
使用concat()串联不同pandas对象
df = pd.DataFrame(np.random.randn(10, 4)) pieces = [df[:3], df[3:7], df[7:]] pd.concat(pieces)
JOIN
-
SQL风格的合并
left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]}) right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]}) pd.merge(left, right, on='key')
Append
-
在dataframe中添加行
df = pd.DataFrame(np.random.randn(8, 4), columns=['A','B','C','D']) s = df.iloc[3] df.append(s, ignore_index=True)
分组:Groupin
我们所说'group by'是指以下步骤中的一个或多个处理:
- 将数据基于一些标准分成多个组
- 分别应用函数到每个组
- ** 组合**结果成数据结构
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
-
分组并对所分的组使用
sum函数df.groupby('A').sum() -
通过多列组合形成了一个层次指数,我们再应用函数
df.groupby(['A','B']).sum()
重塑:Reshaping
堆:stack
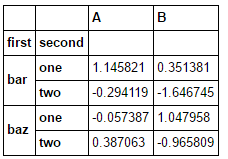
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
....: 'foo', 'foo', 'qux', 'qux'],
....: ['one', 'two', 'one', 'two',
....: 'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
df2 = df[:4]
df2
-
stack()方法“压缩”了DataFrame的层次。
stacked = df2.stack()
数据透视表: Pivot Tables
df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3,
.....: 'B' : ['A', 'B', 'C'] * 4,
.....: 'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
.....: 'D' : np.random.randn(12),
.....: 'E' : np.random.randn(12)})
.....:
我们可以很方便的从这些数据构造数据透视表:
pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
时间序列Time Series
pandas拥有许多简单,功能强大,高效的功能可以在波动期间执行采样操作(例如,数据转换成二5每分钟的数据)。常见于,但不限于,财务应用 等。
rng = pd.date_range('1/1/2012', periods=100, freq='S')
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
ts.resample('5Min').sum()
作图: Plotting
画图建议在网页版的jupyter notebook进行操作,减少不必要的烦恼。
-
Series画图方法
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000)) ts = ts.cumsum() ts.plot() -
DataFrame的画图方法
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, .....: columns=['A', 'B', 'C', 'D']) df = df.cumsum() plt.figure(); df.plot(); plt.legend(loc='best')