[AAAI2019]Exploiting Local Feature Patterns for Unsupervised Domain Adaptation 利用局部特征进行无监督域适应
论文地址:https://arxiv.org/abs/1811.05042
背景
像条件对抗域适应(CADA )一文中所说,当前的对抗网络中只对齐数据整体特征,而只对齐数据的整体特征将会导致网络无法捕捉数据的多模态结构,这会使得网络尽管生成器和判别器都训练的比较好,但是最终的域适应效果依然不理想。在这篇文章中也考虑到了这种缺陷,提出利用局部特征的优势来解决这个问题,通过对整体特征和局部特征同时对齐来完成更好的增益效果。
![[AAAI2019]Exploiting Local Feature Patterns for Unsupervised Domain Adaptation 利用局部特征进行无监督域适应_第1张图片](http://img.e-com-net.com/image/info8/135ff037b19148bda84847e861549228.jpg)
上图中(a)表示数据整体特征对齐效果,(b)则是通过局部特征对齐的效果,从中可以看出在(a)中,Chair和Computer这两种模态的数据被混合在一起,数据模态结构并没有被捕捉到,在(b)中,经过学习的Chair可以在域间被分享并且其数据模态结构比较清晰,可以反应出类别Chair和类别Computer也进行了结合(人坐在椅子上看电脑)。
该方法引进了NetVLAD (建议先看),提出联合优化整体特征和局部特征,首先,局部特征空间被分为一些容易分离的聚群,然后强制保持特征的整体与经过聚合的局部特征保持一致以及局部特征的对齐。
原理
![[AAAI2019]Exploiting Local Feature Patterns for Unsupervised Domain Adaptation 利用局部特征进行无监督域适应_第2张图片](http://img.e-com-net.com/image/info8/5ccb0daefa3940ab881d7f9bae0afc77.jpg)
上图是网络的流程图,图(1)是网络的特征提取器G,(2)是局部特征模型学习部分,(3)是特征对齐部分。网络通过多个卷积层对源域和目标域进行特征提取,实验中使用的是VGG16框架的前5层卷积层,另外源域和目标域的特征提取是参数共享的。
局部特征模型学习
这部分和NetVLAD类似,只是NetVLAD中只使用了VLAD向量(对应到每个聚点的特征点之和),在这里不仅使用了VLAD向量,还是使用了其每个特征点及对应的聚点[ F i j l − c k , k F_{ij}^l - c_k, k Fijl−ck,k]。在学习局部特征期间,通过以下目标函数用于得到分离性较好的局部特征,以及使得到的局部特征具有足够的信息代表量:
L s = − 1 / ( N l ∗ M l ) ∑ M l ∑ N l m a x ( ∑ K S i j l [ k ] l o g ( S i j l [ k ] ) , m ) \mathcal{L}_s = -1/(N_l*M_l) \sum^{M^l} \sum^{N^l} max(\sum^K S_{ij}^l[k]log (S_{ij}^l[k]),m) Ls=−1/(Nl∗Ml)∑Ml∑Nlmax(∑KSijl[k]log(Sijl[k]),m)
这部分看了NetVLAD就很容易理解了, S i j l [ k ] S_{ij}^l[k] Sijl[k]与目标函数在NetVLAD中也有解释,m为边界阈值,不再赘述。NetVLAD:https://blog.csdn.net/LiGuang923/article/details/85470289。
特征对齐
网络中基于经过学习得到的局部特征来对齐源域和目标域特征,分为两步:1.通过对抗学习特征整体对齐 2.局部特征对齐。
对抗学习整体对齐
该部分对应于上图(3)中的下半部分 L G h \mathcal{L}_{G_h} LGh,将图(2)中学习到的局部特征聚合VLAD向量作为判别器输入,然后通过普通的对抗学习Loss优化:
![[AAAI2019]Exploiting Local Feature Patterns for Unsupervised Domain Adaptation 利用局部特征进行无监督域适应_第3张图片](http://img.e-com-net.com/image/info8/f8ee24d3ebd84196a3a7de8f4cce21a9.jpg)
其中 D h D_h Dh为判别器, G ( x s ) G(x_s) G(xs)也就是源域中形成的VLAD向量, x t , n t , n s x_t,n_t,n_s xt,nt,ns分别是目标域数据,数据量,源域数据量。
局部特征对齐
对应的上图(3)中的上半部分 L G l L_{G_l} LGl,作者发现对齐特征点与聚点之间的残差( F i j l − c l [ a i j ] F_{ij}^l - c^l[a_{ij}] Fijl−cl[aij]),比对齐原始卷积特征能够更容易进行优化以及获得更高的对齐增益。该部分的判别器损失和特征提取器损失函数如下:
![[AAAI2019]Exploiting Local Feature Patterns for Unsupervised Domain Adaptation 利用局部特征进行无监督域适应_第4张图片](http://img.e-com-net.com/image/info8/f57659d22fb3496aaef922af8eb8af98.jpg)
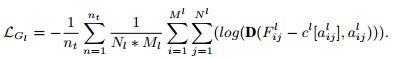
其中 M l 、 N l M_l、N_l Ml、Nl表示特征提取器出来的特征矩阵大小, a i j l = a r g m a x ( S i j l [ k ] ) a_{ij}^l = argmax(S_{ij}^l[k]) aijl=argmax(Sijl[k])也就是特征点 F i j l F_{ij}^l Fijl所对应的最近的聚点k。公式也是常规的对抗Loss。
另外,还使用了一个分类器c,其优化函数与一般分类损失一样:
L c = − 1 / n s ∑ n s y i ⋅ l o g ( y i ^ ) \mathcal{L}_c = -1/n_s \sum^{n_s} y_i \cdot log(\hat{y_i}) Lc=−1/ns∑nsyi⋅log(yi^)
其中 y i y_i yi为源域数据的真实标签, y i ^ \hat{y_i} yi^为预测标签, n s n_s ns为源域样本数。
最后,汇合这些目标函数,得到总的目标函数:
L = L c + λ h L G h + λ l L G l + λ s L s \mathcal{L} = \mathcal{L}_c + \lambda_h \mathcal{L}_{G_h} + \lambda_l\mathcal{L}_{G_l} + \lambda_s\mathcal{L}_{s} L=Lc+λhLGh+λlLGl+λsLs
λ \lambda λ为超参数。通过优化上述损失函数用以学习到分离性较好的局部特征以及同时迁移与类别相关的整体特征、具有泛化性的局部特征。
网络训练
损失函数这么多,如何训练网络呢,这里通过三个步骤进行训练:
1.分类器训练,使用k-means聚类初始化局部特征模型,并固定这些聚群,然后通过最小化源分类损失 L c \mathcal{L}_c Lc只训练一层结构的分类器。
2.源域微调,联合微调分类器、局部特征模型、以及特征提取中的最后两层卷积层,通过最小化分类损失 L c 、 L s \mathcal{L}_c、\mathcal{L}_s Lc、Ls完成。
3.域适应,同时训练分类器、局部特征模型以及最后两层卷积层,最小化上面提到的总目标函数。
参考
Relja A,Petr G,Akihiko T,et al. NetVLAD: CNN architecture for weakly supervised place recognition, 2016.
Jun W, Risheng L, Nenggan Z, Qian Z, et al. Exploiting Local Feature Patterns for Unsupervised Domain Adaptation, AAAI, 2019.