Google面试官抖出自己的面试题,分步解析,超多干货和建议
 本文翻译自Google工程师/面试官Alex Golec的文章:Google Interview Questions Deconstructed: The Knight’s Dialer;翻译:实验楼扫地阿姨;原文链接:https://medium.com/@alexgolec/google-interview-questions-deconstructed-the-knights-dialer-f780d516f029
本文翻译自Google工程师/面试官Alex Golec的文章:Google Interview Questions Deconstructed: The Knight’s Dialer;翻译:实验楼扫地阿姨;原文链接:https://medium.com/@alexgolec/google-interview-questions-deconstructed-the-knights-dialer-f780d516f029
作为一名Google的工程师和面试官,今天是我第二次发文分享科技公司面试建议了。这里先声明:本文仅代表我个人的观察、意见和建议。请勿当作来自Google或Alphabet的官方建议或声明。
下面这个问题,是我面试生涯中第一个问题;也是第一个被泄漏出来,以及第一个被禁掉的问题。我喜欢这个问题,因为它有以下优点:
问题很容易表述清楚,也容易理解。
这个问题有多个解。每个解都需要不同程度的算法和数据结构知识。而且,还需要一点点远见。
每个解都可以简单几行代码实现,非常适合有时间限制的面试。
如果你是学生,或者求职者,我希望你通过本文能够了解到,面试问题一般会是怎么样的。如果你也是面试官,我很乐意分享自己在面试中的风格和想法,如何更好地传达信息、征求意见。

注意,我将使用Python写代码;我喜欢Python因为它易学,简洁,而且有海量的标准库。我遇到的很多面试者也很喜欢,尽管我们推行“不限定语言”的政策,我面试90%的人都用Python。而且,我用的Python 3因为,拜托,这都2018年了。
问题
把你的手机拨号页想象成一个棋盘。棋子走只能走“L”形状,横着两步,竖着一步;或者竖着两步,横着一步。

现在,假设你拨号只能像棋子一样走“L”形状。每走完一个“L”形拨一次号,起始位置也算拨号一次。问题:从某点开始,在N步内,你可以拨到多少不同的数字?
讨论
每次面试,我基本都会分成两个部分:首先我们找出算法方案,然后让面试者在代码中实现。我说“我们找出算法方案”,因为这个过程我不是沉默的独裁者。在这样高压下,设计并实现一种算法,45分钟时间并不算充足。

我通常会让面试者主导讨论,让他们去产生想法,我嘛,就在旁边,时不时地泄漏一点点“天机”。面试者们能力越强,我需要泄漏的“天机”就越少;但是目前为止,我还没遇到一点都不需要我提示的面试者。
有一点我想强调一下,重要的很:作为面试官,我的职责可不是坐那看着大家失败搞砸。我想要给大家正面的反馈,给大家机会去展现大家最擅长的点。给他们提示,就像是在说:呐,这一步路我给你铺上,但这只是为了让你展示给我,你在后面的路上能走的更远。

当听完面试官的问题,你应该做什么?切记不要立刻就去写代码,而是在黑板上试着一步一步去分解问题。分解问题能够帮助你寻找到规律,特例等等,逐渐在大脑中形成解决方案。比如,你现在从数字6开始走,能走2步,会有如下组合:
6–1–8
6–1–6
6–7–2
6–7–6
6–0–4
6–0–6
一共有6种组合。你可以试着用铅笔在纸上画,相信我,有时候动手去解决问题会发生意想不到的事,比你盯着在脑袋里想更神奇。
怎么样?你脑海里有方案了吗?
第0阶:到达下一步
使用这个问题面试,最让我惊讶的是,太多人都卡在了计算从某个特定点跳出时,一共有多少种可能,即邻Neighbors。我的建议是:当你不确定时,先写个占位符,然后请求面试官能否晚点实现这一部分。
这个问题的复杂性并不在Neighbors的计算;我在意的是你如何计算出总数。所有花费在计算Neighbors上的时间其实都是浪费。
我会接受“让我们假设有一个函数能给出我Neighbors”。当然,我也可能会让你后面有时间再去实现这一步,你只需要这样写,然后继续。

而且,如果一个问题的复杂性不在这里,你也可以问我能不能先略过,一般我都是允许的。我倒是不介意面试者不知道问题的复杂性在哪里,尤其刚开始他们还没有全面了解问题的时候。
至于Neighbors函数,因为数字永远不变,你可以直接写一个Map然后返回符合的值。

第1阶:递归
聪明的你可能注意到了,这个问题可以通过枚举出所有符合条件的数字,然后计算。这里可以使用递归产生这些值:

这个方法可以,而且是在面试中最普遍的方法。但是请注意,我们产生了这么多数字却并没有使用他们,我们计算完他们的个数后,就再也不去碰了。所以我建议大家遇到这种情况,尽量去想一下看有没有更好的方案。
第2阶:数不数数
怎么在不产生这些数字的情况下计算出个数?可以做到,但需要一点点机智。注意从特定点跳出N次能够拨到的数字个数,等于从它所有临近的点跳出N-1次能够拨到的数字个数的总和。我们可以表达为这样的递归关系:
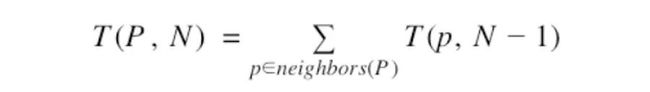
如果你这样想,就会很直观了,跳一次时:6有3个neighbors(1,7和0),当跳0次时每个数字本身算一次,因此每次你只能拨到3个数字。
怎么会产生这样机智的想法?其实,如果你学了递归,并且在黑板上好好研究,这一点就会变得显而易见。这样你就能继续去解决这个问题,实际上就这一点就有多种实现方法,下面这个便是面试中最常见的:

就是这样,结合这个函数计算出neighbors 就可以了。这时候,你就可以捏捏肩膀休息下了,因为到这里,你已经刷掉很多人了。
接下来这个问题我经常问:这个方案的算法理论速度如何?在这个实现中,每次调用count_sequences()都会递归地调用count_sequences()至少2次,因为每个数字至少有2个neighbors。这样会导致runtime成指数增长。
对于跳1次到20次这样的次数还可以,但是到更大的数字,我们就要碰壁。500次可能就需要整个宇宙的热量来完成运算。
第3阶:记忆
那么,我们能做的更好么?使用上面的方法,并不能。我喜欢这个问题,也是因为他能一层一层带出大家的智慧,找到更高效的方法。为了找到更好的方法,让我们看下这个函数是怎么调用的,以count_sequences(6, 4)为例。注意这里用C作为函数名简化。
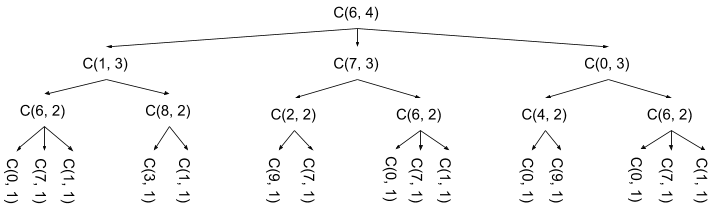
你可能注意到了,C(6, 2)运行了3次,每次都是同样的运算并返回同样的值。这里最关键的点在于这些重复的运算,每次你使用过他们的值之后,就没有必要再次计算。
怎么解决这个问题?记忆。我们那些相同的函数调用和结果,而不是让他们重复。这样,在后面我们就可以直接给出之前的结果。实现方法如下:

第4阶:动态设计
如果你再看看前面的递归关系,就会发现递归记忆的方案也有一点局限性:
注意跳N次的结果仅仅取决于跳N-1次后调用的结果。同时,缓存中包含着每个次数的所有结果。我之所以说这是个小局限,因为确实不会造成真的问题,当跳的次数增长时,缓存也只是线性增长。但是,毕竟,这还是不够高效。
怎么办?让我们再来看一看方案和代码。注意,代码中是从最大的次数开始,然后直接递归到最小的次数:
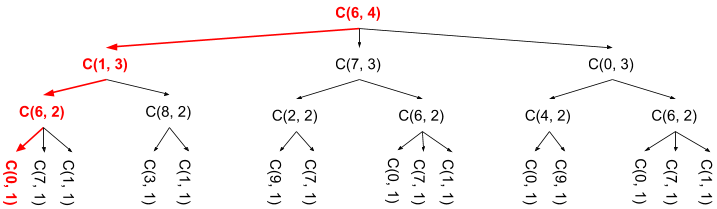
如果你把整个的函数调用图想象成某种虚拟的树,你就会发现我们在执行深度优先策略。这并没有什么问题,但是它没有利用到浅依赖这个属性。
如何实现广度优先策略?这里就是一种实现方法:

这个版本比前面递归版好在哪里?其实并没有好很多,但是这个不是递归的,因此即使处理超大数据也很难崩溃。其次,它使用的是常量内存;最后,它仍旧是线性增长,即便处理200000次跳也只用不到20秒。
评估
到这里,基本就算完了。设计并实现一个线性时的、产量内存的方案,在面试中是非常好的结果。在我的面试中,如果有面试者写出动态编程设计,我通常会给他一个极高的评价:excellent!

当评估算法和数据结构的时候,我经常会说:面试者对问题认识清晰,并且考虑到各方面的可能,当指出不足时他也能迅速改进并提高;最终,实现了一个不错的解决方案。
当评估代码的时候,我最理想的说法是:面试者迅速并精确地把想法转化为了代码;代码结构严谨,容易阅读。所有特殊情况都有概括,并且认真检查测试了代码,确保了没有Bug。
总结
我知道,这个面试问题看上去似乎有点吓人,尤其整个解释下来非常繁琐。但本文的目的和面试中完全不一样。最后,一点面试相关的技巧,以及一些好的习惯,分享给大家:
一定要手动来,从最小的问题开始解决。
当你的程序在做无用的运算时,一定要注意去优化。减少不必要的运算能够让你的解决方案更加简洁,说不定能因此发现更高效的方案。
了解你的递归函数。在实际生产中,递归常常很容易出问题,但它仍旧是非常强大的算法设计和策略。递归方案也总是有优化和提高的余地。
要常常去寻找记忆的机会。如果你的函数是目的性的,并且会多次调用相同的值,那么就试着去存储起来。
![]()
今日推荐:


楼+课程
《Python实战第九期》
《Linux运维与DevOps实战第5期》
《数据分析与挖掘实战第1期》
都开放报名啦!
2018,最后一波努力!
欢迎添加助教小姐姐微信sylmm002
咨询/报名
