

作者:
机器翻译引擎的基本原理
谷歌机器翻译
Zero-shot:零次
Training:训练
Google Neural Machine Translation:谷歌神经机器翻译
我们每天都在使用不同的技术,但却不知道它们的工作原理。事实上,了解机器学习引擎并不容易。Statsbot团队希望通过本博客中的数据故事使机器学习更加清晰易懂。今天,我们来探讨一下机器翻译并解释谷歌翻译算法如何工作。
几年前,翻译未知语言文本是非常耗时的。使用简单的词汇逐词逐字翻译之所以困难,是由于以下两个原因:1)读者必须知道语法规则,2)在翻译整个句子时,需要记住所有语言版本。
现在,我们不需要太多的努力就可以将短语、句子、甚至是大段文本放在谷歌翻译中来翻译。但大多数人并不在意机器学习翻译的引擎如何工作。这篇文章专为那些在意的人而写。
深度学习翻译的问题
如果谷歌翻译引擎将短句的译文保留,则它将会由于可能出现的各种变数而无法工作。最好的方法是教会计算机语法规则,并让它根据这些规则来翻译句子。这听起来很简单。
如果你曾经学过外语,你就知道规则总是有很多例外的。当尝试捕获程序中的所有这些规则、例外和例外中的例外时,翻译的质量就会下降。
现代机器翻译系统采用了不同的方法:它们通过分析大量的文档来分配文本中的规则。
创建一个属于你自己的简单的机器翻译器可以作为任何数据科学家应聘简历中的一个重大项目。
让我们来研究一下被称之为“黑盒”的机器翻译器中隐藏的东西。深层神经网络可以在非常复杂的任务(语音或视觉对象识别)中取得优异的效果,但尽管十分灵活,它们只能用于输入维数和目标维数固定的任务。
循环神经网络
而这正是长短期记忆网络(LSTM)派上用场的地方,LSTM能帮助我们处理不能被先验知道的序列。
LSTM是一种特殊的循环神经网络(RNN),它能够学习长期性的依赖关系。所有RNN看起来都像一连串的重复模块。
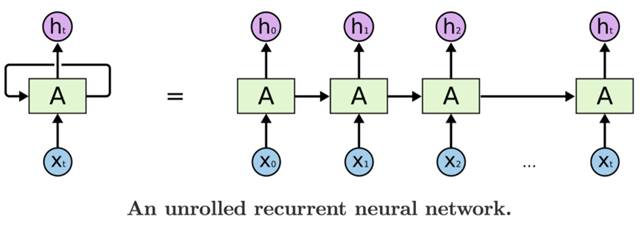
一个展开的循环神经网络
因此,LSTM将数据从一个模块传输到另一个模块,另外,为了生成Ht,我们不仅使用Xt,还使用所有之前的输入值X。要了解有关LSTM的结构和数学模型的更多信息,请阅读这篇非常棒的文章“了解LSTM网络”。
双向RNN
我们的下一步是双向RNN(BRNN)。BRNN将常规RNN的神经元分成两个方向。一个方向是正向的时间或向前的状态。另一个方向是负向的时间或向后的状态。但这两个状态的输出并不与相反方向状态的输入进行连接。
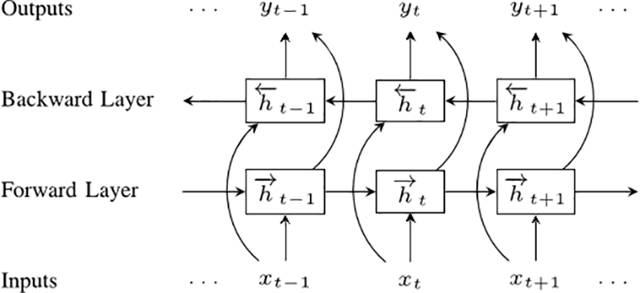
双向循环神经网络
为什么BRNN比相对简单的RNN更好?请想象有一个9个字的句子,而我们要预测第五个字。我们可以知道前4个字,或前4个字和最后4个字。当然,第二种情况预测的质量会更好。
序列到序列
现在我们可以认识序列到序列模型(也称为seq2seq)了。一个基本的seq2seq模型由两个RNN组成即:处理输入的编码器网络和产生输出的解码器网络。
序列到序列模型
最后,我们便可以制作出自己的第一个机器翻译器了!
但是,让我们先思考这一点。谷歌翻译目前支持103种语言,所以我们应该为每种语言提供103×102个不同的模型。当然,这些模型质量的好坏会因为语言的普及程度和训练这个网络所需的文件数量而有所不同。我们可以达到的最佳情况是使一个NN(神经网络)能将任何语言作为输入并将其翻译成任何其他语言。
谷歌翻译
该想法谷歌工程师在2016年底就实现了。NN的架构基于谷歌已研究的seq2seq模型之上。
但唯一的不同是编码器和解码器之间有8层LSTM-RNN,且层与层之间仍有残留的连接,并有一些精度和速度上的调整。如果你想更深入地了解它们,请参考谷歌的神经机器翻译系统。
该方法的主要特点在于,现在谷歌翻译算法对于每对语言只使用一个系统,而不是一个庞大的集合。
该系统在输入句子的开头需要一个“令牌”以指定你要将短语翻译成的语言。
这一改变提高了翻译质量,甚至可以在系统从未见过的两种语言之间进行翻译,这种方法被称为“零次(Zero-Shot)翻译”。
什么是更好的翻译?
当谈到谷歌翻译算法的改进和更好的结果时,如何才能正确地评估第一个翻译备选比第二个更好?
这不是一个无关紧要的问题,因为对于一些常用的句子,虽然我们有专业翻译器的参考翻译,但这些翻译仍然有一些差异。
很多方法能部分解决这一问题,但最流行和最有效的指标是BLEU(双语评估替补)。想象一下,有两个来自机器翻译器的备选:
备选1:Statsbot makes it easy for companies to closely monitor data from various analytical platforms via natural language. (Statsbot通过自然语言使企业能轻松地密切监控来自各种分析平台的数据。)
备选2:Statsbot uses natural language to accurately analyze businesses’ metrics from different analytical platforms.(Statsbot使用自然语言准确地分析企业来自不同分析平台的指标。)
虽然它们有相同的含义,但质量和结构都不同。
我们再看看来自两个人的翻译:
参考1:Statsbot helps companies closely monitor their data from different analytical platforms via natural language. (Statsbot通过自然语言帮助公司密切监测来自不同分析平台的数据。)
参考2:Statsbot allows companies to carefully monitor data from various analytics platforms by using natural language. (Statsbot通过使用自然语言使企业能够密切监控来自各种分析平台的数据。)
显然,备选1更好,与备选2相比,备选1包括更多共同的单词和短语。这就是BLEU方法的一个关键思想。我们可以将备选的n-gram(N元语法)与参考翻译的n-gram进行比较,并计算它们的匹配数(匹配数与它们的位置无关)。我们只使用n-gram精度,因为在多个参考时计算查全率很难,而且结果是n-gram分数的几何平均值。
现在你可以开始评估复杂的机器学习翻译引擎了。下次当你使用谷歌翻译翻译某些内容时,可以想像一下:在给你最好的翻译版本之前,其实谷歌翻译已经分析了数百万份文档。
End.