【11月12日】NumPy基础:数组和矢量计算
Numpy是高性能科学计算和数据分析的基础包,一直活跃在各种以python为基础的数据分析策略中。根据《Python for dataanalysis》一书的介绍,其部分功能如下:
ndarrary,具有矢量算术运算和复杂广播能力(本书将boardcasting定义为不同形状的数组之间算术运算的执行方式)的快速且节省空间的多维数组。
用于读写磁盘数据数据的工具以及用于操作内存映射文件的工具。
线性代数,随机数以及傅里叶变换功能。
用于集成C,C++, Fortran等语言编写代码的工具。
多维数组对象:ndarrary
ndarrary是一个通用的同构数据多维容器,即是说,其中所有的元素必须是相同类型的。每个数组都具有shape和dtype两个属性。shape是一个表示数组维度大小的元组,也可以形象化地理解shape刻画了数组的“形状”。dtype说明了数组中元素的数据类型。
ndarray的创建
创建数组最简单的办法就是使用arrary方法,它接受一切序列型的对象(,可以是列表,也可以是数组),然后创建一个新的含有传入数组的numpy数组。以下是numpy的api中关于arrary的说明。
numpy.array(object,dtype=None, copy=True, order='K', subok=False, ndmin=0)
对该方法的各项参数的说明:
object : array_like
An array, anyobject exposing the array interface, an object whose __array__ method returns anarray, or any (nested) sequence.
type : data-type, optional
The desireddata-type for the array. If not given, then the type will be determined as theminimum type required to hold the objects in the sequence. This argument canonly be used to ‘upcast’ the array. For downcasting, use the .astype(t) method.
当该项参数不指定的情况下,程序会推断出一个合适的类型(the minimum type)。
copy : bool, optional
If true(default), then the object is copied. Otherwise, a copy will only be made if__array__ returns a copy, if obj is a nested sequence, or if a copy is neededto satisfy any of the other requirements (dtype, order, etc.).
order : {‘K’, ‘A’, ‘C’, ‘F’}, optional
Specify thememory layout of the array. If object is not an array, the newly created arraywill be in C order (row major) unless ‘F’ is specified, in which case it willbe in Fortran order (column major). If object is an array the following holds.
指定数组的内存布局。
| order |
no copy |
copy=True |
| ‘K’ |
unchanged |
F & C order preserved, otherwise most similar order |
| ‘A’ |
unchanged |
F order if input is F and not C, otherwise C order |
| ‘C’ |
C order |
C order |
| ‘F’ |
F order |
F order |
When copy=Falseand a copy is made for other reasons, the result is the same as if copy=True,with some exceptions for A, see the Notes section. The default order is‘K’.
subok : bool, optional
If True, thensub-classes will be passed-through, otherwise the returned array will be forcedto be a base-class array (default).
ndmin : int, optional
Specifies theminimum number of dimensions that the resulting array should have. Ones will bepre-pended to the shape as needed to meet this requirement.
指定结果数组应具有的最小维数。为了满足这个要求,我们将根据需要预先设定形状。即轴的个数,有的文章将其解释为矩阵的“秩”。
此外,关于数组的创建,还有以下方法:
arange :类似于内置的range,但是返回的是一个ndarray而不是列表。
ones, ones_like:根据指定的shape和dtype创建一个全1的数组。ones_like以另一个数组为参数,并根据其shape和dtype创建一个全1的数组。
zero,zeros_like:同上。
empty,empty_like:创建新数组,只分配内存空间但不填充任何值。
eye, identity:创建一个正方的N*N的单位矩阵(对角线为1,其余均为0)。
ndarray的数据类型
dtype是numpy如此强大和灵活的原因之一。
以数值型而言,dtype的组成形式都是一个类型名(如int、 float等)后面跟一个用于表示位长的数字。例如int16,就是表示内存占16位(即2个字节)的整数类型。具体如下:
| 类型 |
类型代码 |
说明 |
| int8、uint8 |
i1、u1 |
有(无)符号的8位(1个字节)整型 |
| int16、uint16 |
i2、u2 |
有(无)符号的16位(2个字节)整型 |
| int32、uint32 |
i4、u4 |
有(无)符号的32位(4个字节)整型 |
| int64、uint64 |
i8、u8 |
有(无)符号的64位(8个字节)整型 |
| float16 |
f2 |
半精度浮点型 |
| float32 |
f4或者f |
标准的单精度浮点型,与C的float兼容 |
| float64 |
f8或者d |
标准的双精度,兼容C的double和Python的float |
| float128 |
f16或g |
扩展的浮点数 |
| complex64、 complex128、 complex256 |
c8 、 c16、 c32 |
分别用两个32位、64位和128位的浮点型表示的复数 |
其他还有布尔型等。
| 类型 |
类型代码 |
说明 |
| bool |
? |
布尔型 |
| object |
O |
python对象类型 |
| string_ |
S |
固定长度的字符串类型(每个字符1个字节)。 例如,S10表示创建一个长度为10的字符串 |
| unicode_ |
U |
固定长度的unicode字符串类型(字节数由平台决定)。 |
数组和标量之间的运算
大小相等的数组之间的运算都将运用到元素级。具体的计算中,会将对应位置上的元素进行相应的运算。
同样的,数组和数字(标量)之间的运算也会将运用到数组的每个元素上。可以理解为,自动根据数组的shape扩展标量,将其也扩展为相同shape的数组,再进行计算。
在《Python for data analysis》的中文版中,将不同shape数组之间的运算的broadcasting译为“广播”。国内很多译文都是如此,国内的大牛(http://blog.csdn.net/sunny2038/article/details/9002531)提到了其在与numpy的开发者的交流中,开发者之一回复到“broadcast is acompound -- native English speakers can see that it's " broad" +"cast" = "cast (scatter, distribute) broadly, I guess "cast(scatter, distribute) broadly" probably is closer to the meaning(NumPy中的含义)"。
基本的索引和切片
numpy的切片和列表的最重要的区别在于,所谓的数组的切片实际上原数组的一个“视图”。也就是说,数据不会被复制,对切片(视图)上的任何修改都会直接反应到原数组之中。结合到numpy面向是大量的数据处理工作,这一点就不难理解了。加入numpy坚持要将数据复制来复制去会产生性能和内存的问题。
当然,如果你想要得到是ndarrary的一个副本也不是视图,就需要显示地进行复制操作,例如arr[1:9].copy()。
在多维数组中,如果省略了后面的索引,则返回对象会是维数低一点的ndarray。
例如,对于一个2x2x3的三维数组arr3d中,arr3d[0]就是一个2x3的二维数组。而arr3d[1,0]和arr3d[1][0]的结果相同。
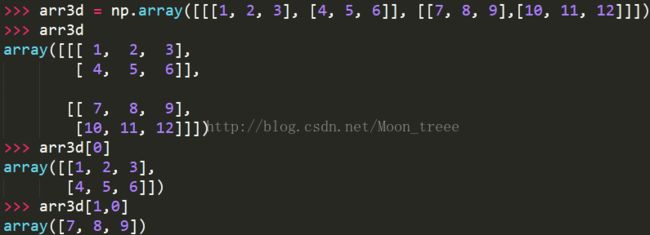
注意,在上述例子中,返回的数组都是视图。
切片索引
同样,对于一维数组,其切片和python的列表类似,无需多述。
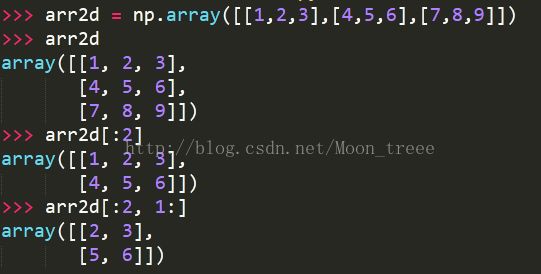
对于多维数组,总是沿着第0轴进行切片的。也就是说,切片是沿着一个轴向选取元素的。可以一次传入多个切片,就像传入多个索引一样。
如arr2d[:2, 1:]是在arr2d[:2]的基础上进一步进行切片。
以上的切片得到的视图的维数和原数组的维数是相等的。可以看到arr2d[:2, 1:],arr2d[:2]和arr2d都是2x2维的数组。
配合整数索引,可以得到低维的切片。
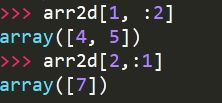
同样,上述的切片也都是“视图”。对切片的操作会影响到原数组。
布尔型索引
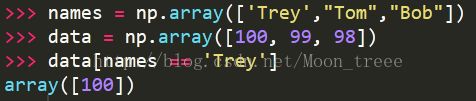
布尔型数组可以用于数组索引,用以选择特定条件的切片。例如数组names是姓名组成的数组,data是各个人员的信息。则data[names == “Trey”]就可以切出Trey的信息了。
此外,还有!=, &, |等符合复合使用可以构建更为复杂的条件。
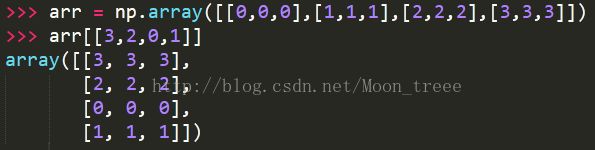
花式索引(Fancyindexing)
好吧,这个翻译绝了。它是numpy的一个术语,指的是利用整数数组进行索引。
以传入的整数数组作为指定顺序选取子集。另,用负数索引将会从末尾进行索引。