Pytorch:利用迁移学习做图像分类
**Pytorch:利用迁移学习做图像分类**
- 数据准备
- 数据扩充
- 数据加载
- 迁移学习
- 训练
- 验证
- 推理/分类
在这一篇文章中,我们描述了如何在 pytorch中进行图像分类。我们将使用Caltech256数据集的一个子集对10种不同动物的图像进行分类。借此来介绍数据集的准备、数据扩充,以及构建分类器的完整步骤。使用转移学习来使用低层次的图像特征,如边缘、纹理等。通过借助一个预训练的模型 resnet50,训练自己的分类器来学习数据集图像中更高级的细节,比如眼睛、腿等。 ResNet50 已经在 ImageNet 上接受了数百万张图片的训练。
数据准备
Caltech256 数据集有30607张图像,分为256个不同的标记类和另一个“杂乱”类。训练整个数据集需要几个小时,因此我们只使用数据集的一个子集,其中包含10种动物: 熊、黑猩猩、长颈鹿、大猩猩、美洲驼、鸵鸟、豪猪、臭鼬、三角龙和斑马。这样我们就可以更快地进行实验。当然,代码也可以用来训练整个数据集。
这些文件夹中的图像数量从81张(臭鼬)到212张(大猩猩)不等。我们使用这些类别中的前60个图像进行训练,接下来的10个图像进行验证,其余的图像在下面的实验中进行测试。
最后我们共有10类动物的600个训练图像,100个验证图像和 409个测试图像。
复现实验过程,需要线按照以下步骤进行文件整理:
- 下载CalTech256 数据集;
- 创建三个文件夹:train、valid 和 test;
- 在文件夹 train 和 vaild 下创建10个子文件夹,分别命名为:bear, chimp, giraffe, gorilla, llama, ostrich, porcupine, skunk, triceratops and zebra;
- 将caltech256 数据集中熊的前60个图像移动到目录 train/bear,并对每只动物重复此操作;
- 将Caltech256数据集中接下来的10张熊图片移到目录 valid/bear,并对每只动物重复此操作;
- 将bear 的剩余图像(即未包含在train 或valid 文件夹中的图像)复制到目录 test/bear, 对每只动物重复此操作。
数据扩充
用在训练集中的图像可以通过多种方式进行变化,以便在训练过程中增加多样性,使训练模型更具通用性,使其可以在不同类型的测试数据上获得更好的表现。此外,输入数据分批次进行,在批量数据一起用于训练之前,需要将它们规范化为固定的尺寸和格式。
每个输入图像都首先进行一组变换,并且引入一些随机变换来增加多样性。在每个训练阶段,每个图像都应用一组变换。在训练过程中,每个阶段的变换过程都引入新的随机变化。这会使数据得到扩充,模型可以进行更好的归纳。
下面我们通过三角龙的图像来讨论一下图片变换过程:
变换 randomresizedcrop 以随机大小(在原始大小的0.8到1.0的比例范围内,以及默认范围0.75到1.33的随机纵横比)裁剪输入图像。然后将裁剪调整为256×256;
RandomRotation 以-15到15度之间随机选择的角度旋转图像;
RandomHorizontalflip 随机水平翻转图像,默认概率为50%;
CenterCrop 从图像中心裁剪出 224×224 像素的图像;
Totensor 将值在0-255范围内的PIL 图像转换为浮点张量,并通过除以255将其规范化为0-1范围;
normalize 接受一个3通道张量,并通过通道的输入平均值和标准偏差对每个通道进行规范化。平均和标准偏差向量作为3个元素向量输入。张量中的每个通道都被标准化为 T=(T-平均值)/(标准偏差);
使用Compose 将所有转换链接在一起:
# Applying Transforms to the Data
image_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
值得一提的是,对于valid 数据和 test数据,我们不进行RandomResizedCrop , RandomRotation 和RandomHorizontalFlip变换,为了使它们可以应用预训练模型,我们仅仅将数据尺寸更改为256×256像素,并以图像中心为基准裁剪224×224 的像素区域。然后将图像变换成张量,通过imageNet 中所有图像的均值和标准差进行归一化。
数据加载
这一部分介绍如何使用定义的转换并加载用于训练的数据:
# Load the Data
# Set train and valid directory paths
train_directory = 'train'
valid_directory = 'test'
# Batch size
bs = 32
# Number of classes
num_classes = 10
# Load Data from folders
data = {
'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid']),
'test': datasets.ImageFolder(root=test_directory, transform=image_transforms['test'])
}
# Size of Data, to be used for calculating Average Loss and Accuracy
train_data_size = len(data['train'])
valid_data_size = len(data['valid'])
test_data_size = len(data['test'])
# Create iterators for the Data loaded using DataLoader module
train_data = DataLoader(data['train'], batch_size=bs, shuffle=True)
valid_data = DataLoader(data['valid'], batch_size=bs, shuffle=True)
test_data = DataLoader(data['test'], batch_size=bs, shuffle=True)
# Print the train, validation and test set data sizes
train_data_size, valid_data_size, test_data_size
首先设置训练和验证数据目录,以及批处理的尺寸。然后利用 DataLoader 加载数据创建迭代器。数据加载的顺序是随机(shuffle)的,Torchvision.transforms 包和DataLoader 是非常重要的pytorch特性,使数据扩充和加载过程非常容易。
迁移学习
从特定领域收集图像并从头开始训练分类器是非常困难和耗时的。因此,我们使用一个预先训练好的模型作为基础,并改变最后几层,以便我们可以根据想要的类对图像进行分类。这可以使我们在使用小数据集时获得更好的效果。因为在预训练模型中,已经从更大的数据集(如ImageNet)学习了基本的图像特征。

正如上图所示,内部层预训练模型保持一致,只修改最终层以适应我们的分类需求。我们将选择 ResNet50 作为我们的预训练模型。
# Load pretrained ResNet50 Model
resnet50 = models.resnet50(pretrained=True)
resnet50是在准确性和推算时间之间能进行良好平衡的一种方法模型。当一个模型在 Pytorch 中被加载进去的时候,所有参数的 “requires_grad” 字段是默认被开启的, 这意味着参数的每次改变都会被存储起来,以便用在反向传播过程中。这回增加大量的内存消耗。因为在预训练模型中大多数的参数已经被训练好了,所以我们需要关闭
“requires_grad”。
# Freeze model parameters
for param in resnet50.parameters():
param.requires_grad = False
然后,我们将resnet50 模型的最后一层替换为一小组连续层。最后一个完全连接的resnet50层的输入被送入一个具有256个输出的线性层,然后送入relu和dropout层。接下来是一个256×10线性层,它有10个输出,对应于我们Caltech子集中的10个类别。
# Change the final layer of ResNet50 Model for Transfer Learning
fc_inputs = resnet50.fc.in_features
resnet50.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 10),
nn.LogSoftmax(dim=1) # For using NLLLoss()
)
因为我们将在GPU上进行训练,所以我们准备好GPU版模型:
# Convert model to be used on GPU
resnet50 = resnet50.to('cuda:0')
接下来,定义消耗函数和用于训练的优化器。pytorch提供多种消耗函数。我们使用 Negative Loss Likelihood函数,因为它可以用于多分类。pytorch还支持多个优化器。我们使用Adam优化器。Adam是最流行的优化器之一,因为它可以单独调整每个参数的学习速率。
# Define Optimizer and Loss Function
loss_func = nn.NLLLoss()
optimizer = optim.Adam(resnet50.parameters())
训练
训练一定的次数,在每一次训练内对每个图像进行一次处理。训练数据加载器批量加载数据。在我们的例子中,我们给出了的批次大小为32,这意味着每批最多有32个图像。
对于每个批次,输入图像通过模型(也就是正向传递)获得输出。然后,利用所提供的损耗函数,在真实值和计算出的输出之间计算损耗。训练参数的损耗梯度利用 Backward函数计算得来。对于迁移学习,我们只需要计算一小部分参数的梯度,这些参数使属于在模型末尾添加的几个新层。对模型的Summary 函数调用可以显示参数的实际数量和可训练参数的数量。正如我们在下面看到的,我们现在只需要训练模型参数总数的十分之一左右;

梯度计算是利用autograd 和 backpagation,在图中用链规则进行微分。pytorch在后向传播过程中积累所有梯度。所以在训练循环开始时,必须将它们归零。使用优化器的zero_grad 函数可实现归零操作。最后,在向后传播中计算梯度之后,优化器的step 函数将会对参数做出更新。
计算整个批次的总损耗和准确度,然后对所有批次进行平均,以获得整个阶段的损耗和准确度值。
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
# Set to training mode
model.train()
# Loss and Accuracy within the epoch
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(train_data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# Clean existing gradients
optimizer.zero_grad()
# Forward pass - compute outputs on input data using the model
outputs = model(inputs)
# Compute loss
loss = loss_criterion(outputs, labels)
# Backpropagate the gradients
loss.backward()
# Update the parameters
optimizer.step()
# Compute the total loss for the batch and add it to train_loss
train_loss += loss.item() * inputs.size(0)
# Compute the accuracy
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
# Convert correct_counts to float and then compute the mean
acc = torch.mean(correct_counts.type(torch.FloatTensor))
# Compute total accuracy in the whole batch and add to train_acc
train_acc += acc.item() * inputs.size(0)
print("Batch number: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}".format(i, loss.item(), acc.item()))
验证
随着训练次数的增加,模型往往会过度拟合数据,导致其在新的测试数据上的性能较差。随时进行单独验证是很重要的,这样我们就可以在合适的点停止训练并防止过度拟合。 可以在每个训练循环结束的阶段立刻进行验证,验证过程中不需要任何梯度计算,可以利用torch.no_grad() 来实现这一操作。
在每次的验证批次中,输入和得到的标签被发送给GPU(没有GPU就用CPU), 输入首先经过前向传播,然后使损耗计算和精确度计算。
# Validation - No gradient tracking needed
with torch.no_grad():
# Set to evaluation mode
model.eval()
# Validation loop
for j, (inputs, labels) in enumerate(valid_data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# Forward pass - compute outputs on input data using the model
outputs = model(inputs)
# Compute loss
loss = loss_criterion(outputs, labels)
# Compute the total loss for the batch and add it to valid_loss
valid_loss += loss.item() * inputs.size(0)
# Calculate validation accuracy
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
# Convert correct_counts to float and then compute the mean
acc = torch.mean(correct_counts.type(torch.FloatTensor))
# Compute total accuracy in the whole batch and add to valid_acc
valid_acc += acc.item() * inputs.size(0)
print("Validation Batch number: {:03d}, Validation: Loss: {:.4f}, Accuracy: {:.4f}".format(j, loss.item(), acc.item()))
# Find average training loss and training accuracy
avg_train_loss = train_loss/train_data_size
avg_train_acc = train_acc/float(train_data_size)
# Find average training loss and training accuracy
avg_valid_loss = valid_loss/valid_data_size
avg_valid_acc = valid_acc/float(valid_data_size)
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
epoch_end = time.time()
print("Epoch : {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation : Loss : {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(epoch, avg_train_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start))
以下是训练和验证的损耗曲线和精确度曲线:
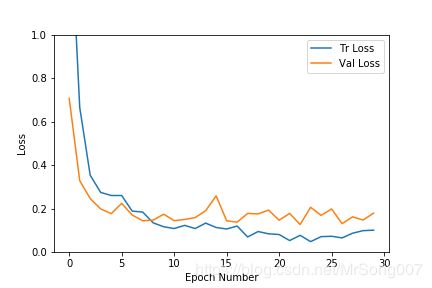

正如我们在上面的两幅图中所看到的,这个数据集的验证和损耗损失都很趋于平稳,随着循环次数增加,训练损耗进一步下降,最终会出现过度拟合,但验证结果没有得到持续的改善。因此,我们从精度高、损耗小的循环处选择得到的模型,为了防止训练数据过度拟合,可以尽早停止训练的循环。
训练终止也可以自动化。一旦损耗低于给定的阈值,并且在给定的时间段内验证精度没有提高,我们就可以停止训练。
推理/分类
一旦我们得到了最终模型,我们就可以对单个测试图片进行分类推理,或者在所有的测试数据集上得到一个测试精确度。测试集精度度计算类似于验证方式,但它是在测试数据集上进行的。下面看看如何到了一个测试图片的输出类别。
输入图像首先通过用于验证/测试数据的一系列转换。然后将得到的张量转换为四维张量,四维张量通过模型会输出该输入图像对不同类别的对数预测概率。模型输出的指数为我们提供了类概率,然后我们选择概率最高的类作为输出类。
def predict(model, test_image_name):
transform = image_transforms['test']
test_image = Image.open(test_image_name)
plt.imshow(test_image)
test_image_tensor = transform(test_image)
if torch.cuda.is_available():
test_image_tensor = test_image_tensor.view(1, 3, 224, 224).cuda()
else:
test_image_tensor = test_image_tensor.view(1, 3, 224, 224)
with torch.no_grad():
model.eval()
# Model outputs log probabilities
out = model(test_image_tensor)
ps = torch.exp(out)
topk, topclass = ps.topk(1, dim=1)
print("Output class : ", idx_to_class[topclass.cpu().numpy()[0][0]])
在409张图像的测试装置上,获得了92.4%的精确度。
以下是一些新测试数据的分类结果,这些数据未用于训练或验证。图像的最高分预测类别及其概率分数显示在右上角。概率最高的类别通常是正确的类别。概率第二高的类别通常是其余9个类别中在外观上与其最接近的。


基于在ImageNet 1000个类别上的预训练模型,可以有效地对我们个人指定的10个类别做分类。