Hadoop学习之二《Hadoop环境伪分布式环境搭建》
问题?Hadoop学习之二《Hadoop环境伪分布式环境搭建》
一、Hadoop定义
二、环境搭建
(1)资源下载
JDK1.7-Linux-64:点击下载链接
Hadoop2.2版本:点击下载链接
(2)配置过程
首先是,虚拟机要先安装好,而且网路要配置好。详情请看环境配置
1.设置网络,并且网络service networkrestart
2.创建组,并且创建hadoop用户设置密码(放到这个组中)
3.下载jdk1.7及hadoop2.2压缩包,并且使用WinSCP软件移动这两个文件到/usr/local下
解压jdk:tar –zxvf …… 并且重命名为jdk1.7
解压hadoop,并且移动到用户主目录下(这个时候这个文件只有root有权限,hadoop还没有,后面会给予权限)

在hadoop程序目录下创建文件夹:都是以后放一些数据文件的

给hadoopGroup组分配对此hadopp2.2文件的操作权限

给组分配读写执行权限
![]()
配置jdk的环境变量
![]()

查看是否配置成功

修改hadoop环境变量

查看是否生效

修改hadoop2.2里面etc下的配置文件,这个非常重要。配置不成功,后面的文件系统就会出错。
修改环境变量:export JAVA_HOME=/usr/local/jdk1.7/ (就只改这个,有些有#号的别去掉了。)

修改slaves文件

修改core-site.xml
fs.defaultFS
hdfs://node:9000
configerate hostnameand port
hadoop.tmp.dir
/home/hadoop/hadoop2.2/tmp/hadoop-${user.name}
storethe temp dir
hadoop.proxyuser.hadoop.hosts
*
hadoop.proxyuser.hadoop.groups
*
修改mapred-site.xml.temp
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node:10020
mapreduce.jobhistory.wabapp.address
node:19888
修改yarn-site.xml
yarn.resourcemanager.hostname
node
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
node:8032
yarn.resourcemanager.scheduler.address
node:8030
yarn.resourcemanager.resource-tracker.address
node:8031
yarn.resourcemanager.admin.address
node:8033
yarn.resourcemanager.webapp.address
node:8088
修改hdfs-site.xml
dfs.namenode.http-address
node:50070
namenodeaddress and port
dfs.namenode.secondary.http-address
node1:50090
seconde addressand port
dfs.replication
3
configeratehdfs store dir number,default :3
dfs.namenode.name.dir
file:///home/hadoop/hadoop2.2/hdfs/name
namnode is usedto keep storing namespace and exchange the path of local log file
dfs.datanode.data.dir
file:///home/hadoop/hadoop2.2/hdfs/data
datanode isstore local dir
dfs.namenode.checkpiont.dir
file:///home/hadoop/hadoop2.2/hdfs/namesecondary
secondarynamenode
dfs.webhdfs.enabled
true
is it alowedto view web hdfsfile
dfs.stream-buffer-size
131072
buffer:4kb
修改主机名:这个只要在hdfs开启前改就行了,可以一开始就把主机名改了
![]()

绑定hostname与IP 增加四个节点(另外三个后面会加虚拟机) 检验是否成功。
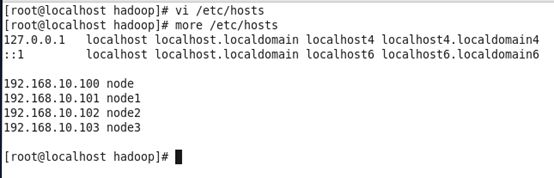

关闭防火墙

克隆虚拟机,克隆三个,分别是Node1、Node2、Node3
开启四个节点,分别设置网络192.168.10.101、192.168.10.102、192.168.10.103
分别改主机名:vi /etc/sysconfig/network 查看more /etc/hosts是否四个都是一样的
最后全部重启网络:service network restart
查看防火墙是否全部关闭:chkconfig –list | grepiptables
ssh免登陆设置(产生秘钥这个,最好用自己新建的用户进行产生,hadoop2.2最终权限是谁就用那个设置)
.ssh下产生公钥: 详情:31页
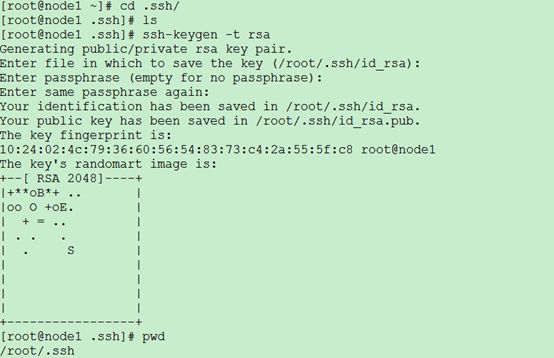
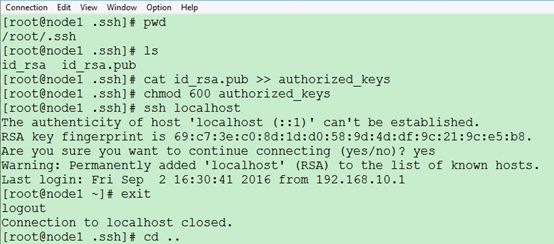

实现远程无密码登录
最后只要将每一个的公钥都加到其中一个authorized_keys中,再使用复制命令就可以达到每一个节点当中都有各自节点的公钥,即可实现远程无密码登录。是不是很方便

全部节点的authorized_keys文件内容:


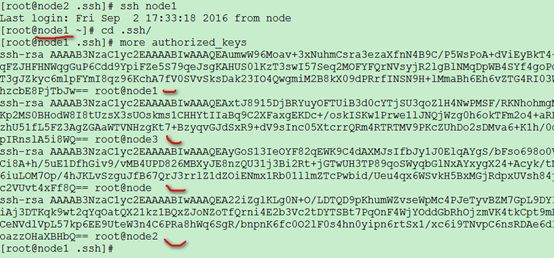

完成,这样无论在那个节点,都可以实现远程无密码登录了
接下来实现Hadoop的测试了
格式化文件系统:(要把四个节点的虚拟机开着):hdfs namenode –format

启动hadoop: start-dfs.sh 如下图,全部都起来了。

jps查看进程,看看namenode出现没。

去其他节点测试,如果只有master节点的namenode才开启的话,而datanote没开启的话
问题就是前面配置错误了。可能性在hadoop配置上面。

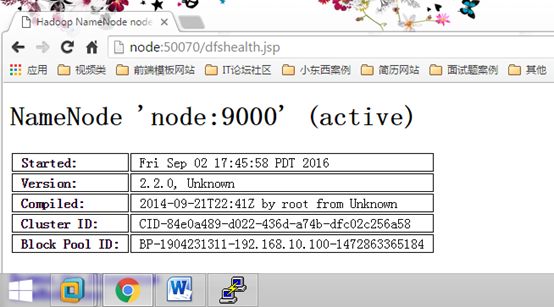
测试:在虚拟机中输入网址http://node:50070

出现这个网页,说明成功了。当然你也可以使用其他节点试一下。(换到其它节点去)
同样的,其他节点的hadoop也得启动才能成功
用windows也可以访问,前提是需要配置hosts文件:
C:\Windows\System32\drivers\etc\hosts

最后windows浏览器访问:同样成功的
可以关掉服务:stop-dfs.sh,这里就不关闭了,还要继续做实验。

启动Yarn:start-yarn.sh

发现比启动文件系统HDFS的时候多了几个进程(ResourceManager and NodeManager)
其它节点也是一样的。是这样的,node节点成为了ResourceManager,而其他三个节点都成为了NodeManager。
访问网址:

查看集群计算的任务信息

种植查看看集群计算任务信息,这个只是平时拿来查看看任务的。
![]()
集群验证:(详情请看36页)
使用hadoop自带的WordCount例子进行集群验证

可以查看到节点的运行情况了。这是一个案例,hadoop自带的有一个例子,拿来测试集群是否成功。hadoop的集群环境已经搭建成功,显而易见,成功了。
