最新版Spark2.2读取多种文件格式数据
Spark2.0+的文件读取
Spark可以读取多种格式文件,csv,json,parque。因此对应就有很多函数与之对应。在Spark2.0以后一般使用SparkSession来操作DataFrame、Dataset来完成数据分析。这些读取不同格式文件的函数就是SparkSession的成员DataFrameReader的方法。该类就是将文件系统(HDFS,LocalFileSystem(一定要在每台机器上都有的文件,不然会找不到文件,因为不确定executor会在哪台机器上运行,如果是本地文件,运行executor机器上一定要有该文件))中的文件读取到Spark中,生成DataFrame的类。下面来看看具体的文件读取。
1.CSV
其实该方法叫CSV不是很好,因为它不止可以读CSV文件,他可以读取一类由分隔符分割数据的文件,由于这类文件中CSV是代表,所以该函数才叫CSV吧。
1.1标准CSV
csv数据
特征:有空值?表示,有表头,类型明确
"id_1","id_2","cmp_fname_c1","cmp_fname_c2","cmp_lname_c1","cmp_lname_c2","cmp_sex","cmp_bd","cmp_bm","cmp_by","cmp_plz","is_match"
41264,44629,1,?,1,?,1,1,1,1,1,TRUE
28871,41775,1,?,1,?,1,1,1,1,1,TRUE
99344,99345,1,?,1,?,1,1,1,1,1,TRUE
31193,66985,1,?,1,?,1,1,1,1,0,TRUE
24429,25831,1,?,1,?,1,1,1,1,1,TRUE
23571,49029,1,?,1,?,1,1,1,1,1,TRUE
6884,6885,1,?,1,?,1,1,1,1,1,TRUE
7144,9338,1,?,1,?,1,1,1,1,1,TRUEspark代码:
val spark = SparkSession.builder().appName("fileRead").getOrCreate()
import spark.implicits._
val data1 = spark.read
// 推断数据类型
.option("inferSchema", true)
// 设置空值
.option("nullValue", "?")
// 表示有表头,若没有则为false
.option("header", true)
// 文件路径
.csv("ds/block_10.csv")
// 缓存
.cache()
// 打印数据格式
data1.printSchema()
// 显示数据,false参数为不要把数据截断
data1.show(false)效果:

1.2TSV
TSV数据
特征:无头,有数据类型,\t分割
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
298 474 4 884182806
115 265 2 881171488
253 465 5 891628467
305 451 3 886324817
6 86 3 883603013spark代码:
val cols = Seq("user_id", "item_id", "rating", "timestamp")
val data2 = spark.read
// 推断数据类型
.option("inferSchema", true)
// 没有表头false
.option("header", false)
// 指定分隔符
.option("delimiter", "\t")
.csv("movie/u.data")
// 设置头
.toDF(cols: _*)
.cache()
data2.printSchema()
data2.show()
// 计数
data2.count()结果:
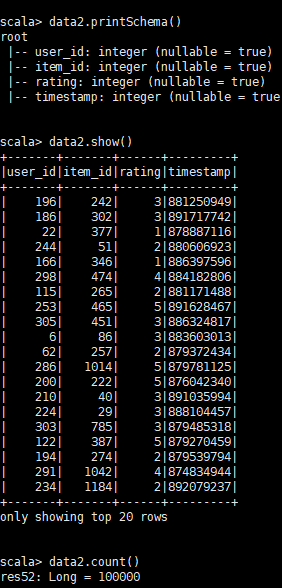
2.JSON文件
JSON不像CSV那样,他是半结构化的数据,因此他可以表示更加复杂的数据类型,但是缺点也同样明显,存储同样的数据,JSON文件更大。
数据:有点复杂,介绍一下
轨迹ID long,用户ID long,time timestamp,td string,trail [id int ,ts long,alt double,lon double ,alt double,d string]
主要就是大对象里面有一个数组,数组里面有很多小对象(数量不固定),csv是难以表示这种数据的。

但是。。。处理起来很简单
val jsonpath = "/home/wmx/hive/warehouse/trail/sample40.json"
val data3 = spark.read.json(jsonpath).cache()
data3.printSchema()
// 因为有点多只显示1条,不截断
data3.show(1,false)
结果
这里大家可以看到,时间戳数据被解析成string了,但是spark内置的数据类型是支持Date的

因此要处理数据类型:
改为
// 按顺序把类型全写下来
val schema: StructType = StructType(Seq(
StructField("tid", IntegerType, true),
StructField("uid", IntegerType, true),
StructField("st", TimestampType, true),
StructField("td", StringType, true),
StructField("trail", ArrayType(StructType(Seq(
StructField("id", IntegerType, true),
StructField("ts", LongType, true),
StructField("lat", DoubleType, true),
StructField("alt", DoubleType, true),
StructField("lon", DoubleType, true),
StructField("d", StringType, true)))), true)));
val data4 = spark.read
.schema(schema)
.json(jsonpath)
.cache()
data4.printSchema()
data4.show(1, true)结果:
类型完全匹配:

最后准备写一下parquet,但是parquet本人不是很熟,只知道parquet使用的函数是load(path:String),希望对大家有所帮助。
列式存储
列式存储和行式存储相比有哪些优势呢?
可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
只读取需要的列,支持向量运算,能够获取更好的扫描性能。