域适配论文杂读(门外汉级)
要看的基于深度学习的adaptation和image translation方面的论文,希望能对这个领域最新的工作有个概念,主要给自己看。其实个人觉得解决这个问题真的不是重点,而是研究它的成因,以便在训练的过程中解决CNN泛化的问题才是本质
Table of Contents
未看或未总结
分类或分割
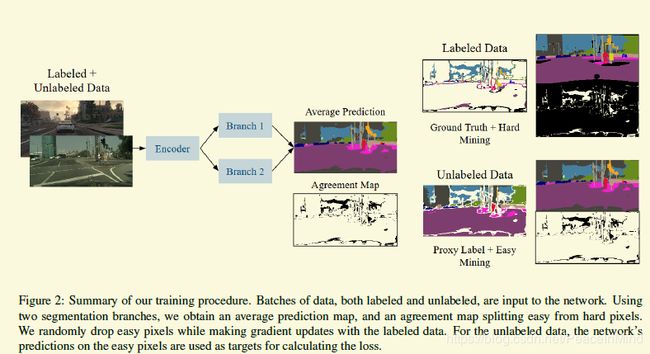
[2018-arxiv] Adaptive Semantic Segmentation with a Strategic Curriculum of Proxy Labels [paper]
[2018-ICML] Learning Semantic Representations for Unsupervised Domain Adaptation[paper]
[2018-ICLR] Self-ensembling for visual domain adaptation [paper]
[2018-ICML]CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION [paper]
[2018-PR] Adaptive Batch Normalization for practical domain adaptation [paper]
[2018-CVPR-oral] Maximum Classifier Discrepancy for Unsupervised Domain Adaption[paper]
[2017-NIPS] Learning multiple visual domains with residual adapters[paper]
[2017-CVPR] Unsupervised Pixel-Level Domain adaption with Generative Adversarial Networks[paper]
[2018-CVPR]Deep Cocktail Network:Multi-source Unsupervised Domain Adaptation with Category Shift [paper]
检测器
[2018-CVPR] Domain Adaptive Faster R-CNN for Object Detection in the Wild [paper]
[2018-CVPR]Cross-domain weakly supervised object detection through progressive domain adaptation [paper][code]
Image Translation
[2018-NIPS] Image-to-image translation for cross-domain disentanglement [paper][code]
[2018-ECCV-oral]Diverse Image-to-Image Translation via Disentangled Representations [paper][code]
未看或未总结
Learning from Web Data: the Benefit of Unsupervised Object Localization
Unsupervised Domain Adaptation using Generative Models and Self-ensembling
SPLAT: Semantic Pixel-Level Adaptation Transforms for Detection
Domain Alignment with Triplets
Adversarial Feature Augmentation for Unsupervised Domain Adaptation
Moment Matching for Multi-Source Domain Adaptation
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Conditional Adversarial Domain Adaptation
Adversarial Multiple Source Domain Adaptation
A Unified Feature Disentangler for Multi-Domain Image Translation and Manipulation
Revisiting (ϵ,γ,τ)(ϵ,γ,τ)-similarity learning for domain adaptation
[2018-arxiv]Progressive Feature Alignment for Unsupervised Domain Adaptation [paper]
[2018-NIPS]Generalizing to Unseen Domains via Adversarial Data Augmentation
[2018-ECCV] Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
[2018-ECCV-oral] A Style-Aware Content Loss for Real-time HD Style Transfer
[2018-CVPR] Joint Pixel and Feature-level Domain Adaptation in the Wild
[2018-CVPR] Iterative Learning with Open-set Noisy Labels
[2018-CVPR-weakly] Zigzag learning for weakly Supervised Object detection
[2018-arxiv-weakly] Exploring the Limits of Weakly Supervised Pretraining[paper]
[2019-AAAI] Depthwise Convolution is All You Need for Learning Multiple Visual Domains [paper]主要去共享ponitwise的卷积
分类或分割
[2018-arxiv] Adaptive Semantic Segmentation with a Strategic Curriculum of Proxy Labels [paper]
自从看了MCD后,对类似的论文要求就高了。这篇论文的主体思想在我看了MCD后就想到了,但是个人觉得逃不出MCD的魔爪,也就没有尝试。当然这篇论文有两个东西不在我的意料之中
1 在souce domain用难例挖掘,在target domain用简例挖掘
2 在损失函数里面加个一个loss,使得两个分类网络的权值不同
其实个人觉得一开始就用proxy-label(一些论文里称之为pseudo-label)是有一定风险的,这个跟任务有关,没有一种很好的机制保证在很多任务都work,因为一不小心就跑飞了。
另外这篇论文竟然不引用MCD不是很能理解
[2018-ICML] Learning Semantic Representations for Unsupervised Domain Adaptation[paper]
我个人觉得这篇文章一定程度上受到了adaptive bn的影响。出发点也较为合理,因为直接用proxy-label或者pseudo-lable个人是觉得不太鲁棒的。作者用的是align每一个label的均值,明显更合理些。当然还是那个问题,用proxy-label需要仔细设计,不一定在很多任务都适用。
[2018-ICLR] Self-ensembling for visual domain adaptation [paper]
没有仔细看,感觉跟下面的MCD有点异曲同工
[2018-ICML]CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION [paper]
个人觉得比较无趣的工作,用cyclegan做image translation,估计是架不住性能好
[2018-PR] Adaptive Batch Normalization for practical domain adaptation [paper]
这篇也是我非常喜欢的论文,前期没调研清楚,我跟这篇想到一块去了,等好多实验做完了才发现思路已经被发了。所以进入一个领域要早,行动也要快。个人已经验证过这种zero-shot方法在作者没有实验的很多任务上都能有较大的提高。 当然理论上还是有一定缺陷的,所以性能上比用了target damain数据的方法要差点,但是方案确实很简洁,我个人觉得很优美,发PR有点小亏。
[2018-CVPR-oral] Maximum Classifier Discrepancy for Unsupervised Domain Adaption[paper]
外行的角度看,非常漂亮的工作,非常创新且有意思的文章,解决方案也非常简洁。分类分割都适合,而且还有源码.
基本上传统的adapation的工作都是一个分支是对抗地区分源域和目标域,另外一个分支去对源域的样本做分类,两个分支共享网络(特征生成器)的一个重要任务是将源域和目标域的样本都投影到同一个特征空间,那么有可能会造成下图左边的情形,虽然源域和目标域区分不出来了,但是不同类别的样本特征空间有可能也会纠缠在一起,不利于最终的分类目标。虽然个人觉得图中有些夸张,因为毕竟还在另外一个分支在起作用,但是确实之前的方案没有刻意地考虑这个问题。

所以为了达到考虑类别分界面的目的,该工作的框架和训练目标有了明显的变化。同样一个生成器,两个分支,一个分支还是做分类,另外一个分支从对抗训练变成了还是做分类任务.然后每次迭代训练都分成三步。第一步,按照普通的分类损失让生成器和两个分类器能够处理源域的样本,第二步,固定生成器,训练两个分类器,同样,两个分类器需要处理源域分类损失,另外一个目标需尽量对目标域的样本做出不同的预测。这样训练过后的一个好处就是,如下图中的“maximize discrepancy”部分,如果两个分类器都对一个目标样本分类一致的话,那么这个样本肯定是比较好迁移的,两个分类器的分界面会先向这些好处理样本收缩。第三步,如下图中的“Minimize discrepancy”,固定分类器,训练生成器,使得样本的特征向F1,F2漂移.经过多次这样的迭代,最终就能得到想要的结果。
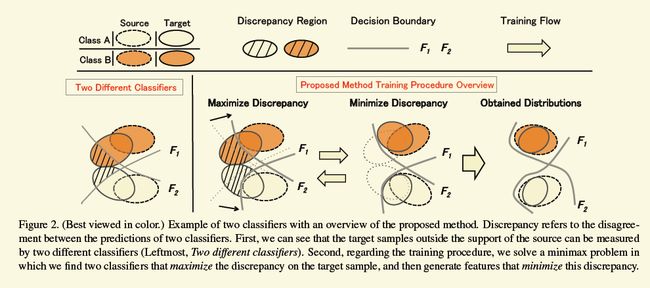
用作者的源码简单地跑了一下GTA5到cityscape的实验,发现两个loss有量级上的差距,后面需要再仔细看看。
一个可能的小缺陷是F1和F2都太靠近分界面,另外一个就是不知道target domain数据的分布,不一定能像作者画的那样,F1,F2能以合适的速度抢占target domain的区域。
[2017-NIPS] Learning multiple visual domains with residual adapters[paper]
一些量化方法里把大部分的权重量比特而保留少部分作为浮点型以提高精度。这篇文章的出发点其实有一点异曲同工之妙。它希望用同一个网络架构去解决不同domain的问题,但是希望共享大部分的权值,而重新训练少部分值。跟传统的finetuneing共享底层特征不同,该工作利用resnet的buildblock,并将其里面的大部分参数设置成了domain-agnostic的参数,而剩下了小部分的设置成domain-specific参数。domian-agnostic的参数可以通过在一个大型的数据库训练后固定下来。而domain-specific的参数就针对不同的数据或任务去调整。如下图,domain-specific的参数包括所有的BN层和作者新加的一些卷积层。这篇还有个改进版本。

[2017-CVPR] Unsupervised Pixel-Level Domain adaption with Generative Adversarial Networks[paper]
作者给出了一个非常直观也非常有意思的思路,应该是我看到的第一篇利用style transfer做adaption的工作。source domain的数据有label, target domain没有label,那作者就利用source domain的数据去生成类似于target domain的数据,然后用这些生成的数据去训练,一方面数据类似,另一方面又有label.

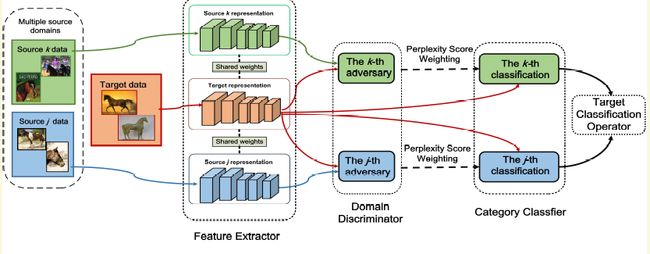
[2018-CVPR]Deep Cocktail Network:Multi-source Unsupervised Domain Adaptation with Category Shift [paper]
这一篇没有看的太懂,囫囵吞枣。该工作主要解决两个现实中可能出现的问题。第一个是可能有多个不同的source,因此该论文叫multi-source...,第二个target domain的类别不一定每个source都有,称之为catogoryshift。作者的做法个人理解有点像ensemble,不过加了weight。
首先作者为每个source都训练一个分类器Cs,并且还有一个domainclassifier以区别它和target domain. 那么想要得到一幅最终图片的类别,那么可以ensemble多个单独分类器Cs的结果。如果测试图片跟那个domain最接近,那么那个分类器的权重更高。domain的接近性可以用domain classifier的损失来判断。没看懂的主要地方在公式6,也就是domain classifier的损失选择原因。
[2018-CVPR] Joint Optimization Framework for Learning with Noisy Labels
该论文处理的的有错误标注的情况,相比于下篇论文,应该是个close-set的案例,也就是说虽然有些样本被标错了,但是样本的真实类别还包含在这个数据库中。比如imagenet有1000类,里面有猫有狗,然后一幅狗的图片被标成了猫,猫这个类别还是在这1000类里面,就称之为close-set.如果狗的图片被标成了狗粮,不在这1000类里面,就定义成open-set.
这个工作首先能给人insight的一个贡献从实验中发现了一个很有趣的现象,当用一个高学习率去训练网络时,网络对这种噪声比较鲁棒。
另外整个大框架的思路是很普通的,我刚进入这个领域就能想到,如下图,不过难点就在于怎么distill好的样本,如果没有好的方式,训练出来的结果很有可能不是想要的,就和把已经有部分认知能力的中学生扔进山里自我学习差不多,有可能出来一个杰出人才,有可能变成坏蛋,所有得想办法做一些间接的监督。
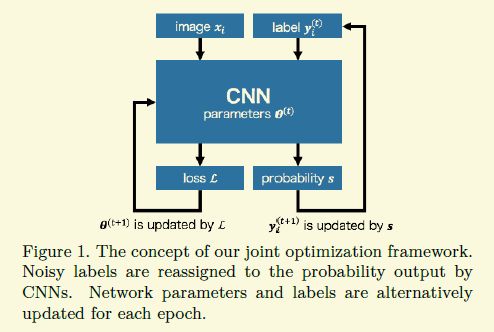
作者给出的方案是加两个约束在损失上。第一个是预测类别分布要与先验知识(比如训练集的类别分布)尽量一致。这里约束存在明显的缺陷,因为训练时候一般batch不是很大,对于一个batch的均值这个类别分布有个比较大的bias,特别是类别比较多的情况下。第二个约束是希望每个预测的label尽量confident,比如预测的概率不要停留在0.5,尽量要么0要么1,这是合理的,不过没有理解作者给出的可以防止陷入局部最优解的理由,需要再看看。
[2018-CVPR] fully convolutional adaptation networks for semantic segmentation[paper]
个人认为这篇工作每个子模块思想上都没特别大的创新,不过由于总体上讲在像素域做adaptation的确实不多,并且本人的一些粗浅实验显示直接在像素域做对抗训练效果不好,所以这篇论文还是能给人一些启发的。作者主要将像素域的adaptation分成两个子模块,并claim成两个很高大上的词汇叫appearance-level和representation-level domain adaptation,个人觉得其实就是style transfer和对抗训练,即先把源域的图片transfer到target domain,然后利用普通的像素域进行对抗训练。不过作者用的是老式的stype transfer的方法,一幅源域图片感觉应该都得调好久。
[2018-CVPR] ROAD: Reality Oriented Adaptation for Semantic Segmentation of Urban Scenes[paper]
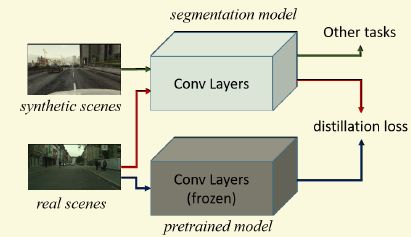
主要是想利用合成的数据迁移到实际的数据。主要创新是在损失的设计上,adaption核心的东西还是里用分类的那一套。
作者在损失设计上考虑了两个方面,
第一个是Target Guided Distillation,个人看完之后还是觉得比较诡异,不过按照论文里的ablaiton study效果不错。作者用了两个同样架构的网络,只是一个权值用的是ImageNet训练的结果并且不会再改变,一个是权值需要微调以用于分割。固定不动的网络输入是真实图片,在某个层得到一个激活图f1,分割网络输入的是合成图片,还是在同样的层上得到另外一个激活图f2.那么这个损失的定义就是这两个图f1和f2的相异性,用的是逐点的欧式距离。所以很容易发现诡异的地方有两点,第一个是合成图片和实际图片不是配对的,不过在低层或者高层去匹配感觉都不是合理。第二个是一个网络是为分割,一个网络是为分类,这样的匹配合理性真是不是很能理解。
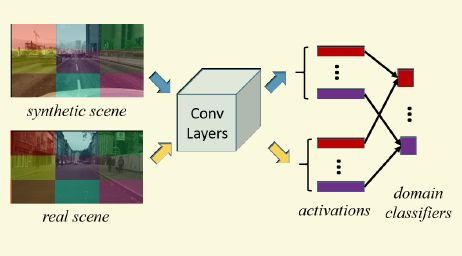
第二个在于像素级别的domain classifier,这个很好理解,就是让基础网络不能区分某个像素点是来自源域还是目标域,不过好像navie的方式不太好使,也就是直接把来自不同域的所有的像素当成两个类别,作者认为像素的方差太大(个人理解是不管是源域还是目标域像素特征分布纠缠在一块了),那么网络本来就分不出来,对抗训练也就没效果,
作者的方法是根据这类图片的特殊性,把图片分成了9块,比如图片上中区域对应的可能都是天空,中间都对应的都是马路什么的。经过这样的切分后,某个区域的像素点的特征比较集中,网络更能抓住它的特征,好区别,那么对抗训练才有效果。
检测器
[2018-CVPR] Domain Adaptive Faster R-CNN for Object Detection in the Wild [paper]
检测器的adaption问题研究的还是很少的,虽然本篇采用的还是分类器adaption的思路。如下图,该工作在faster rcnn的基础上加了三个模块。
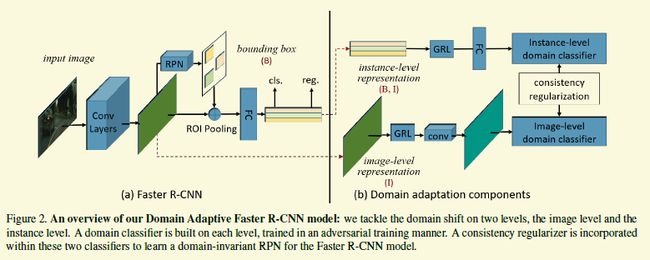
其中两个模块是image-level adaption和 instance-leveladaption,很好理解。就是利用gradient reverse layer让基础的卷积层分不清图片和其中的物体是来自源域还是目标域。第三部分的consistency regularization也很好理解,就是作者希望两个模块的判断有一致性,最好不要出现image-level分类成源域而instance-level把该图的物体分类成目标域这种显然矛盾的结果,所以作者加了一个欧式loss,只需要计算每个instance类别激活值跟imagelevel head上特征图上图个激活值平均值的欧式距离。
(一点小疑问,由于RPN初期给出的box一般不太好,在instance的loss权重的设置上是不是能先低后高而不是一直保持在一个固定值上,实验为准)
[2018-CVPR]Cross-domain weakly supervised object detection through progressive domain adaptation [paper][code]
不知道怎么评价这篇文章。这篇文章想做的是跟其他的有些区别,首先他想做的是物体检测,不过在target domain里不像之前的完全没有标注,而是说有一些image level的标注,比如说这幅图里有猫和狗,但是不知道在什么地方。
作者用了两个技巧,第一个他称之为damain transfer,个人认为就是上面提到的 Unsupervised Pixel-Level Domain adaption with GenerativeAdversarial Networks 那一套,只是现在GAN上用了非常火的CycleGAN.第二个就是Pseudo-Labeling,target domain不是有图像级别的标签么,比如说狗和人,那么我先用在source domain训练的检测器去检测,狗和人置信度第一的框暂时认为是真值,然后去迭代训练。其实这种思想感觉是MIL的一个子集,早在image caption上就做的比较好了,比如 From Captions toVisual Concepts and Back 这篇论文
Image Translation
[2018-NIPS] Image-to-image translation for cross-domain disentanglement [paper][code]
这篇论文还没有理解透彻,因为感觉每个模块都似曾相识。这个工作对数据更严格,是要有paired data,这种数据估计也就是分类才有。在这样的数据下,作者把数据的特征表示成两个部分,一个部分是自己独有的(Exclusive representation.),另外一个部分是共享的(Shared representation.),如下图。

然后采用encoder-decoder架构结合一堆的loss迫使去学习上面的表达。
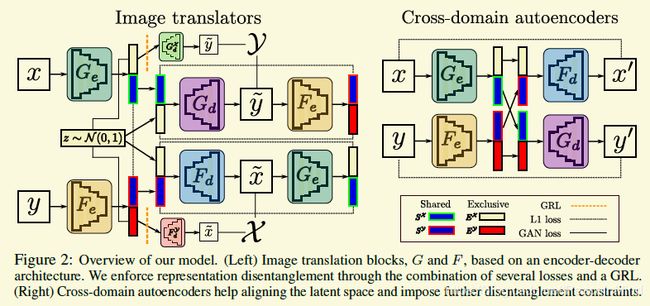
Exclusive representation:就是上面图2左边最顶和最底的两条线路。以x那条线路为例,x经过encoder得到特征表征,然后会被分成两部分,独有的部分会经过一个gradient reverse layer(前馈无影响,反馈把梯度变符号),再经过一个decoder去生成一幅图像y'.Decoder是希望这幅图跟y越像越好,但是由于有gradient reverse layer, 前面的encoder是希望不能恢复,因此这个encoder出来的独有部分是不能恢复出y的。
Shared representation: 由于作者采用的是paired data, 所有共有的部分,就可以用L1的loss来训练。
Adding noise in the representation: 但是为了防止减数和被减数都趋向于非常小的数来减少loss,作者采用了先前工作的一个trick,在encoder的输出加一个N(0,0.1)的高斯噪声(怎么直观理解?)。
Reconstructing the latent space:相对于独有部分,通过共享的部分作者是希望能恢复出另外一个域的数据,也就是上面左图的中间部分。另外作者跟cyclegan类似,x恢复出的数据y'再经过相应的encoder应该得到跟前面decoder输入一致的表达
Architectural bottleneck: 这一段不是特别理解 Therefore, instead of using skip connections, we reduce the architectural bottleneck by increasing the size of the latent representation
WGAN-GP loss. 只是肤浅地看过一点,忘了,后面需要再看
Cross-domain autoencoders:交换共享部分还是可以恢复出来
[2018-ECCV-oral]Diverse Image-to-Image Translation via Disentangled Representations [paper][code]
作者把特征表达拆成了两部分,一个是不同域共有的content,一个是域特有的attribute,为了能生成diverse的结果,作者把attribute的分布约束在高斯分布,这样在测试的时候可以利用同一个content结合不同的attribute分别作为相应encoder的输入就能生成不同的结果。
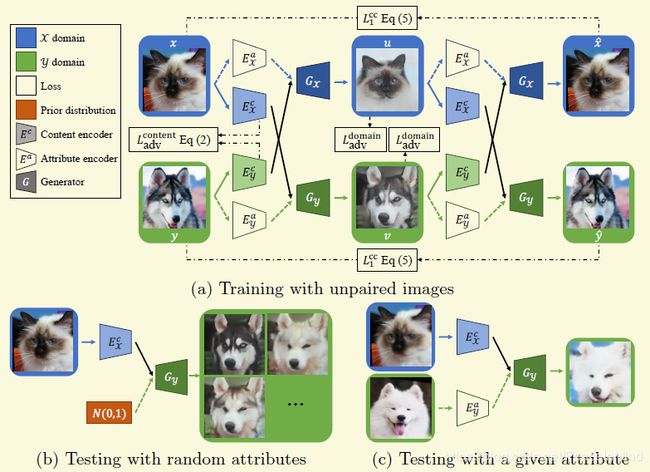
网络设计部分:不同域的Content encoder的最后一层和Generator的第一层是共享的,去保证不同域的相同content投影到同样的空间。
Loss设计:作者采用了很多loss的组合来保证解耦特征的学习
content对抗loss:很常用的对抗loss,用一个discriminator去尽量区分content是来自哪个域,而encoder尽量去迷惑discirmiantor

self construction loss: 这个也很常见,当把一幅图片encoder成一个内部表达后,还是可以通过generator把原图恢复出来,如果原图是x,那么x' = Gx(Ecx(x),Eax(x))
construction loss = L1(x, x')
attribute loss: 上面提到了attribute要约束在高斯分布,作者采用的KL距离,另外作者为了鼓励attribute的可逆性,作者加了一个regression loss,意思就是,在一个content上结合一个随机的attribute z,生成一张图片,那么对这张图片再次通过encoder得到的attribute z'应该跟z类似
L1( Eax(Gx(Ecx(x),z))) , z)
Cross-cycle Consistency Loss:这个就是作者独特的东西。虽然cross cycle loss在很多其他论文里采用了,但是很多其他的都只能产生一个结果,作者为了适应生成不同的结果,作者改变了一些行为。从X,Y域各取样本x,y,那么可以用过各自的encoder生成Ecx(x),Eax(x)和Ecy(y),Eay(x)
作者首先交换了各自的attribute,并调用各自的生成器生成新的图像u,v,也就是
u = Gx(Ecx(x),Eay(x))
v = Gy(Eay(x),Eax(x))
按照作者的定义和设想,u的内容应该跟x一样,但是attribute(在style trnasfer中也可以成style)是跟y一样。
作者在这里加个一个domain classifier,希望去区分图片来自哪个域。那么对于u而言,domain classfier希望将它分类成X域,但是前面的Ecoder和Generator希望这个classifier不能区分。 y类似
接着进入cross-cycle阶段,作者再次交互对应的attribute,那么生成的应该就是图片应该类似于原图