CNN网络模型整理笔记
AlexNet网络结构:
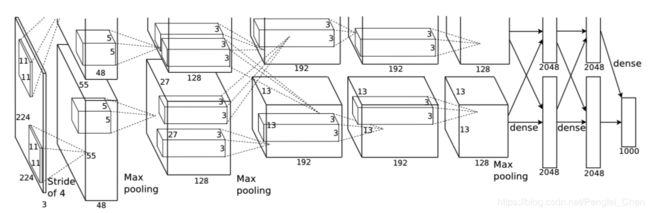
5层卷积,3层全连接。使用了多GPU策略,局部反应归一化,重叠池化方法。
ZFNet网络结构:
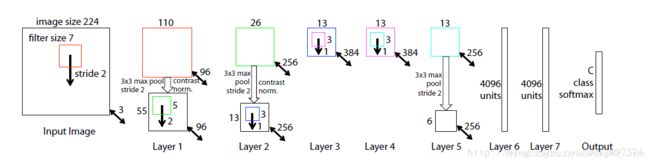
可视化过程:
卷积层输出的特征作为输入,输入到反卷积网络,反卷积网络包括unpooling、relu、deconv三个过程。
VGGNet网络结构:

一个卷积层由多个小卷积核构成,降低了训练的数据量。
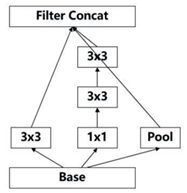
GoogleNet网络结构:
GoogleNet提出了一种加深网络的结构——inception结构,通过使用1x1,3x3,5x5的小卷积核并列构成一个inception结构,最后在特征图的厚度上进行简单的堆叠,不但加深了网络深度,同时增加了网络对尺寸的适应性,在一个特征图中融合多尺寸卷积核所得到的结果。inception_v1如下图所示。

Inception_v2网络结构:
Inception_v2网络最大的贡献是提出了BN的操作。在每一个神经元进行激活前,使用BN操作,将数据拉回到以0为均值,1为方差的分布当中。以sigmod函数为例,当输入数据过大或者过小,可以看出其梯度都很小,经过多次迭代之后,远离输出层的参数更新很慢,出现梯度消失现象,从而导致Loss收敛速度慢。加入BN操作,可以加快网络收敛速度,提高网络的稳定性。
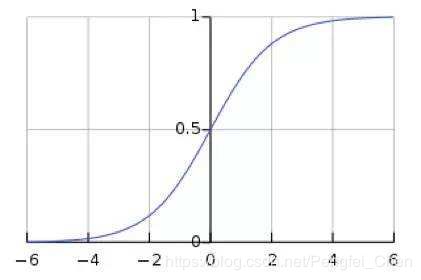 sigmod函数
sigmod函数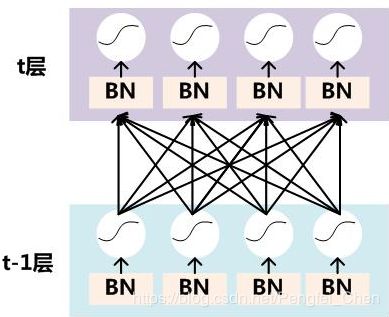 激活函数之前加入BN
激活函数之前加入BN
 m为mini-batch的大小。
m为mini-batch的大小。
inception_v3网络结构:
inception_v3相比于inception_v2加入了更多网络优化。
1、对于n * n的卷积核,提出使用1 * n和n * 1的卷积替代,在网络中部,当n=7时,网络有一个很好的效果;
2、在35 * 35 —>17 * 17以及17 * 17 —> 8 * 8的维度上提出了一种更有效的降维策略(Efficient Grid Size Reduction ),提出一种并行降维方法,具体方式见下图:

35 —> 17 17 —> 8
采用这种网络模型可以将top-5降低。并且v3还提出了RLS(Model Regularization via Label Smoothing ),提出不要使用一种“hard”的标签分布,取而代之的是使用以下公式:
![]() ,文中u(k) = 1 / K。使用这种策略可以将top-5降低0.2个百分点。
,文中u(k) = 1 / K。使用这种策略可以将top-5降低0.2个百分点。
ResNet网络结构:
RestNet提出了残差网络的概念,在之前的网络结构中都是采用stack layer进行堆叠使得网络层数加深,从而获得更好的网络结构。但是发现一个问题:随着网络的越来越深,网络的性能却在下降(识别率逐渐下降)。残差网络的提出一方面保证了网络的深度可以更深,另一方面保证了网络的新能没有下降。①
我们要知道,使用identity mapping(恒等映射,即y = x,y为该层网络的输出,x为该层网络的输入)可以保证网络的性能不会下降,但是直接通过stack layer堆叠的方式构造出y = H(x) = x,这样的H(x)难以进行优化,但是如果不多次使用identity mapping则会导致网络层数不够。RestNet构造了一种残差网络,如下图所示。
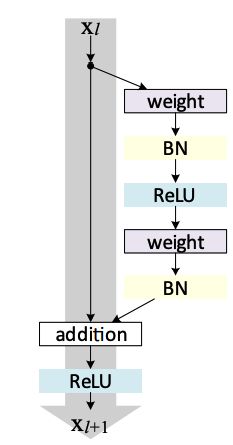 ,输入为Xl,输出为Xl+1,我们要尽量保证Xl+1 = relu(Xl)。我们构造了残差网络F(x),则relu之前的数据为H(X) = Xl + F(Xl),为了保证H(X)尽量为identity mapping,我们要使F(Xl)趋近于0。实验证明,优化F(Xl)趋近于0比优化H(Xl)趋近于Xl容易得多。RestNet很好的解决了①中的需求,构造了F(x)使得网络层数得到加深,又避免了直接优化H(x)的难度,同时还实现了identity mapping。
,输入为Xl,输出为Xl+1,我们要尽量保证Xl+1 = relu(Xl)。我们构造了残差网络F(x),则relu之前的数据为H(X) = Xl + F(Xl),为了保证H(X)尽量为identity mapping,我们要使F(Xl)趋近于0。实验证明,优化F(Xl)趋近于0比优化H(Xl)趋近于Xl容易得多。RestNet很好的解决了①中的需求,构造了F(x)使得网络层数得到加深,又避免了直接优化H(x)的难度,同时还实现了identity mapping。
ResNeXt网络结构:
作者提出 ResNeXt 的主要原因在于:传统的要提高模型的准确率,都是加深或加宽网络,但是随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。因此本文提出的 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量(得益于子模块的拓扑结构一样,后面会讲)。
论文的关键是提出了一种网络结构叫做Aggregated Transformations,网络结构如下图所示。
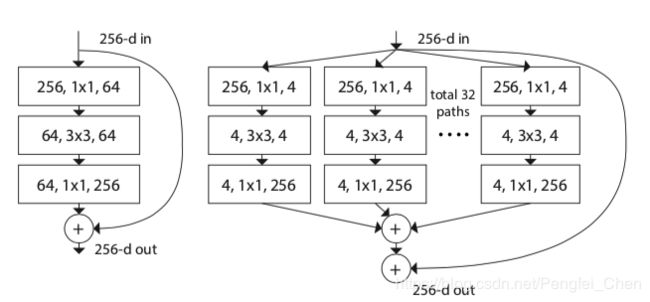
左图为ResNet结构,右图为Aggregated Transformations,可以看出相当于将三个较大的卷积分成32个小部分,最后进行相加,论文验证额这样的结构不会降低准确度,并且参数数量会得到降低。
DensNet网络结构:
为了提高神经网络的性能,无非是加深网络(ResNet加深网络同时解决了梯度消失的问题)或者拓宽网络(Inception)。如DenseNet则是从feature的角度出发,充分利用feature的特征,使得参数更少。DenseNet有以下几个优点:
1.减轻了梯度消失;
2.加强了feature传递;
3.一定程度上减少了参数。
下面是DenseNet block的结构。

上图中可以看出,DenseNet将每一层feature map的输出都与后面所有层进行直接连接,并且在层与层之间加入1*1的卷积核进而降低feature map的厚度,进而减少参数。DenseNet网络可以做到很深,并且不会拓宽深度。
整个深度DenseNet网络结构如下图所示。(由多个block组成)

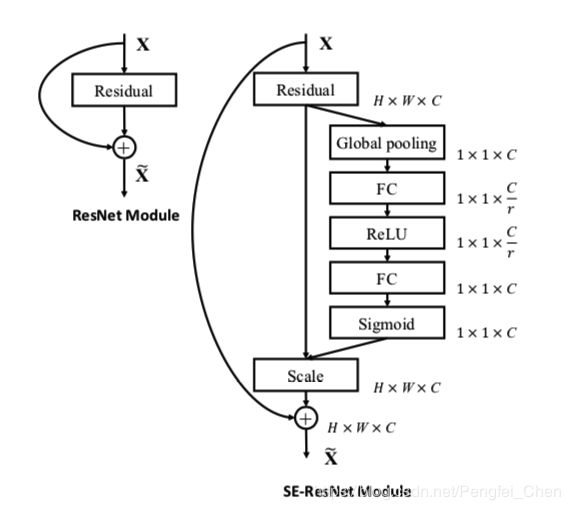
SEBlock网络结构(2017):
Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中,作者采用SENet block和ResNeXt结合在ILSVRC 2017的分类项目中拿到第一,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。SEblock结构如下图所示。

1.Ftr操作:正常的卷积操作,将H’ * W’ * C’的feature map变成H * W * C,理论上不属于SE操作;
2.Fsq操作:squeeze操作,对C个H * W的map求average pooling,生成1 * 1 * C的数据z;
3.Fex操作:exception操作,对于z,进行s = σ(W2 * δ(W1 * z)),其中W1为C/r * C大小的矩阵,将z变换成1 * 1 * C/r,r是缩放系数,W为C * C/r大小的矩阵,重新将z扩大成1 * 1 * C,δ为relu函数,σ为sigmoid函数,最终得到s。
4.Fscale操作:s中存储的就是feature map中各个通道的权重,进行相乘得到最后的输出。
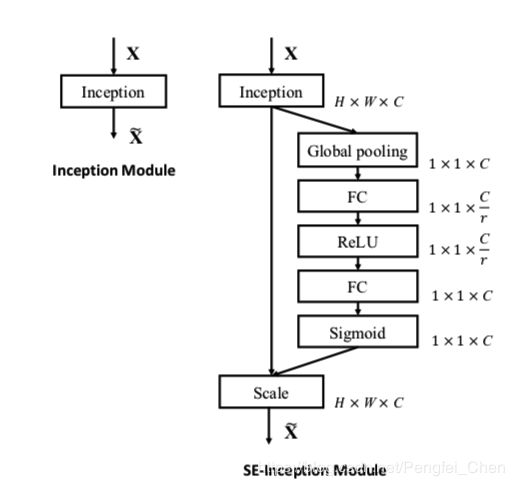
下面两张图展示了在inception和ResNet上SEBlock的应用。
NasNet网络结构(2017):
NasNet网络结构基于NAS论文的思路,使用RNN搜索器,搜索出对数据集分类效果最好的网络结构。论文的核心点有三个:
1.延续NAS论文的核心机制使得能够自动产生网络结构;
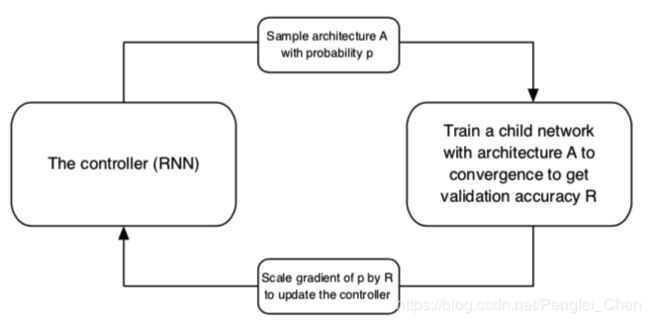
搜索器结构如上所示,首先预测一个网络模型,训练使其收敛,然后在validation数据上得到一个准确率R,将R回传给搜索器更新参数,从而产生更好的网络结构。
2.采用resnet和Inception重复使用block结构思想;
借鉴主流网络结构使用Cell累加的思想,整个网络由两种Cell(Normal Cell和Reduction Cell)组成,前者不改变feature map的大小,后者将feature map的尺寸减半。
在CIFAR-10和ImageNet数据集上的网络结构如下所示。

3.利用迁移学习将生成的网络迁移到大数据集上提出一个new search space。
每一个Cell都由B个block组成,对于每一个block来说,RNN控制器有5个预测步骤并且有5个输出,如下图所示。
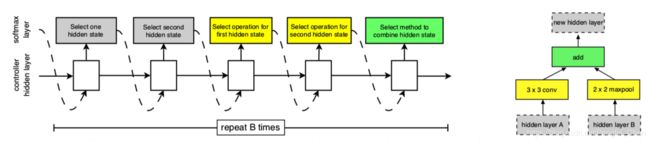
Step 1:从hi,hi-1或者上一个block产生的hidden states中选择一个hidden state;
Step 2:用Step 1的方法在选择一个hidden state;
Step 3:选择一个操作用于Step 1中产生的hidden state;
Step 4:选择一个操作用于Step 2中产生的hidden state;
Step 5:选择一个结合方式组合Step 3和Step 4中的输出用来生成一个新的hidden states。
Step 3和4中操作的选择范围如下图上所示,Step 5中的结合方式如下图下所示。


最终生成的Normal Cell和Reduction Cell如下图所示。
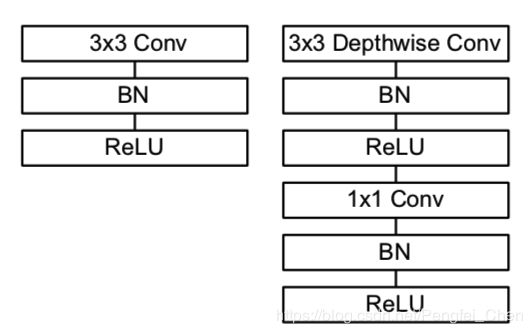
MobileNet网络结构(2017):
MobileNet网络结构提出的目的是为了减轻网络的计算量和参数,从而实现深度学习框架能够在一些嵌入式平台、移动端、车载应用等方面得以应用。为了减轻网络计算和参数,论文中提出了Deep-wise卷积的方法,具体操作如下图所示。
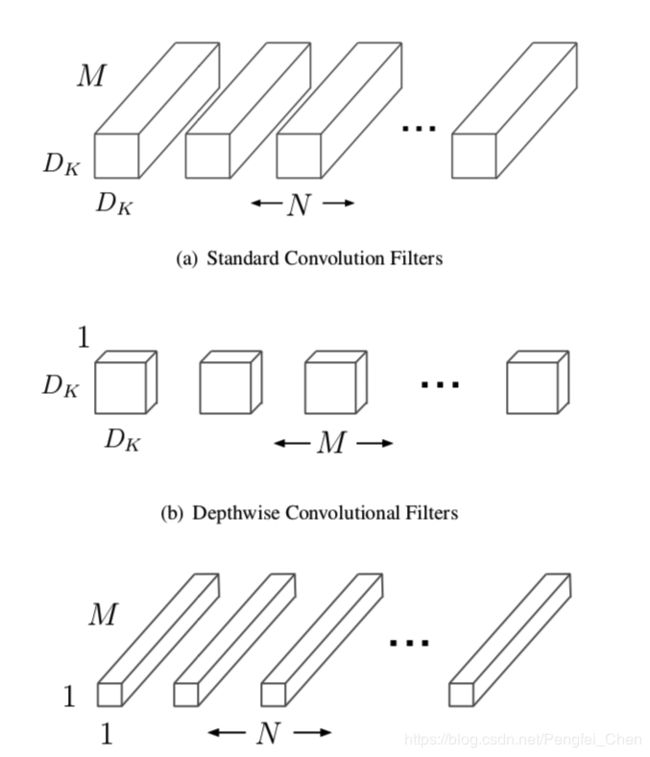
上图中(a)表示的就是一般的卷积运算,它的计算量为DK * DK * N * M * DF * DF,其中DK为卷积核大小,N为卷积核个数,M为卷积核通道数,DF为输入feature map大小。
在MobileNet中,对以上操作进行了分步:
1.首先构造M个DK * DK * 1大小的卷积核对输入进行卷积得到一个DF * DF * M大小的输出,此处计算量为DK * DK * M * DF * DF。
2.构造N个1 * 1 * M大小的卷积核对1中输出进行卷积可以得到DF * DF * N大小的输出,此处计算量为N * DF * DF。
所以总的计算量为DK * DK * M * DF * DF + N * DF * DF,比原来大大减少。Deep-wise网络结构如下所示。
MobileNet为了适应不同场合网络的要求,提出了宽度因子(α)和分辨率因子(ρ)。宽度因子作用于输入和输出的通道尺度上,分辨率因子作用于输出feature map宽和高尺度上,公式如下图所示。
![]()
MobileNet_v2网络结构(2018):
本论文是对MobileNet进行的改进。网络结构如下所示。
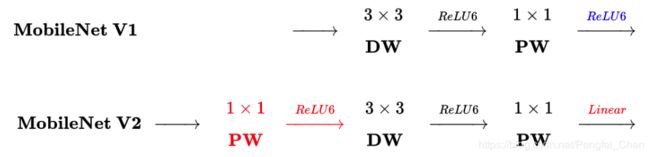
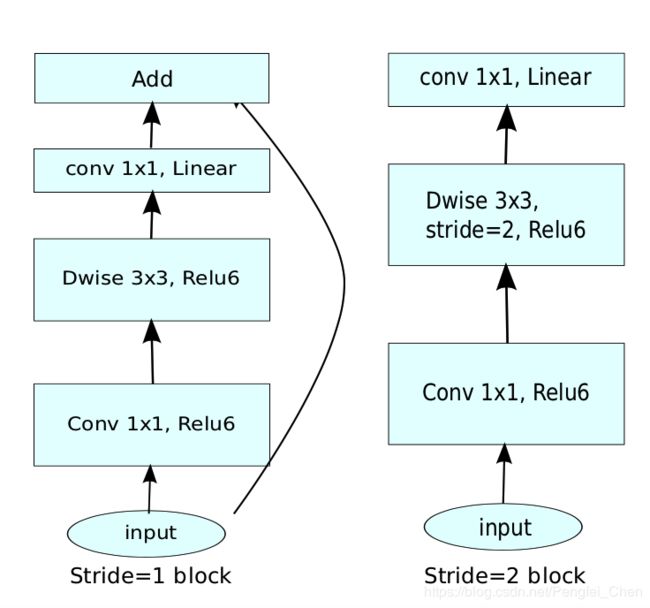
和MobileNet相比,v2主要加入了两个创新点。
1.Inverted residuals。
论文采用了ResNet的思想,将输入先经过1 * 1,在经过3 * 3,在经过1 * 1和输入进行相加,最后进行输出。但是和RestNet不同的是,ResNet秉承先压缩、再卷积、最后扩张的思路,而MobileNet_v2则是先扩张,在进行Deep-wise卷积,再压缩的思路。在1 * 1卷积阶段,将输入通道数扩张6倍,因为输入通道数对Deep-wise操作有着很大的影响,如果使用压缩操作,那么保留的信息过少,在后面的1 * 1卷积阶段进行压缩。
2.Linear bottlenecks。
然后使用Linear bottlenecks进行输出,不使用Relu的原因是,因为此处使用压缩操作,如果再使用Relu,则会丢失更多信息(负数都消失了),然后和输入进行相加,最后输出。Linear bottlenecks就是直接取消Relu操作即可。具体网路如下图所示。
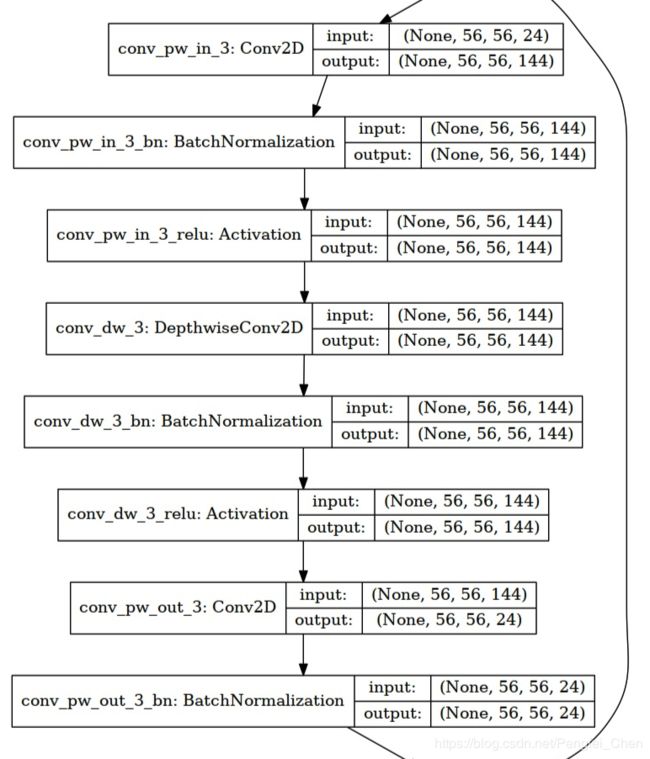
shuffleNet网络结构(2017):
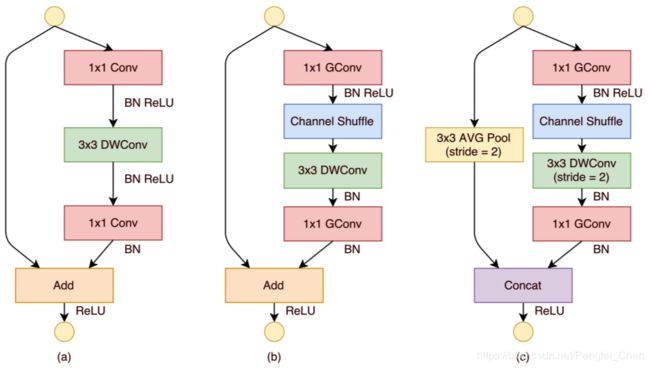
shuffleNet主要采用了三种方式对网络进行轻量化处理:(1)channel shuffle;(2)pointwise group convolutions;(3)deepwise separable convolution
(1)channel shuffle
假设输入的feature map 通道数为N,filter的数量为M,我们将feature map和filter分成g个group,那么每一个group中只有N/g个feature map和M/g个filter,对每一个组内部做卷积操作,然后将每一个组的输出进行concat。但是如果对多步骤进行分组操作,则会出现边界效应——层与层之间的关系只涉及到组内,没有用到组间的信息,导致信息丢失。所以采用了channel shuffle的方式,每做完一次group内的卷积,就把其他组内的数据进行重新分配,从而解决边界效应,channel shuffle的操作如下图(b)、(c)所示。

(2)pointwise group convolutions和deepwise separable convolution
前者就是带group操作的1 * 1卷积,作者认为大量的1 * 1卷积核的计算量也不可以忽视,在下图中,GConv就代表带group的卷积操作。(b)和(c)就是shuffleNet提出的两种unit结构。
部分资料参考自:https://blog.csdn.net/u012897374/article/details/79199935