Python 爬取 4027 条脉脉职言,解读程序员真实的互联网生活!
脉脉是一个实名职场社交平台。之前爬了脉脉职言版块,大概爬了4027条评论,本文对爬取过程给出详细说明,对于评论内容仅做可视化分析。
爬虫
仍然使用Python编程,对爬虫没兴趣的可直接跳过看下部分,不影响阅读。网址 https://maimai.cn/gossip_list ,需要先登录才能看到里面的内容。
爬取目标:
Python资源共享群:484031800
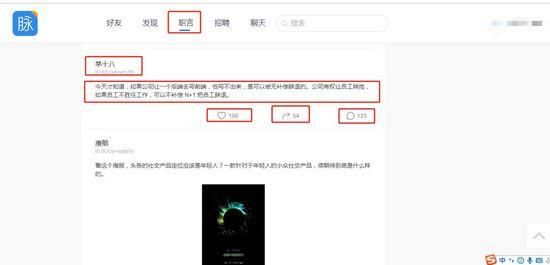
只爬文字部分,图片不考虑。
在浏览器内按F12打开开发者,向下滑,会看到很多gossip开头的json文件(不行的话刷新一下)。
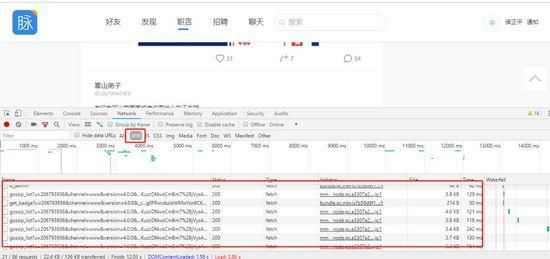
右键open in new tab,里面是一条一条记录,text后面是评论内容。

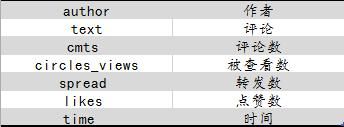
我们感兴趣的信息是下面这些:
看一看每个网站的地址,都是page=数字结尾,所以爬的时候写一个循环,数字从1开始往后取就可以了。
学习过程中有不懂的可以加入我们的学习交流秋秋圈784中间758后面214,与你分享Python企业当下人才需求及怎么从零基础学习Python,和学习什么内容。相关学习视频资料、开发工具都有分享
https://maimai.cn/sdk/web/gossip_list?u=206793936&channel=www&version=4.0.0&_csrf=coAlLvgS-UogpI75vEgHk4O1OQivF2ofLce4&access_token=1.9ff1c9df8547b2b2c62bf58b28e84b97&uid=%22MRlTFjf812rF62rOeDhC6vAirs3A3wL6ApgZu%2Fo1crA%3D%22&token=%22rE8q1xp6fZlxvwygWJn1UFDjrmMXDrSE2tc6uDKNIDZtRErng0FRwvduckWMwYzn8CKuzcDfAvoCmBm7%2BjVysA%3D%3D%22&page=1&jsononly=1
json的最开头有total和remain两个参数,给出了目前所有可见评论剩余数和总数,可以作为循环的停止条件。

但比较坑的一点是,脉脉并不能可见所有评论,而且评论是不断刷新的,所有如果爬完一页循环到下一页或者尝试过很多次之后,它会提示你:

直接看的时候有这样的提示会体验很好,但对于爬虫来说就不是很友好了,需要加个if判断。
另外爬得太快,也会出错,记得加time.sleep。
大概把能踩的坑都踩了,所以如果顺利的话,每次只能爬几百条信息,想爬更多的话,需要过一段时间等信息更新的差不多了再爬,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 19 18:50:03 2018
"""
import urllib
import requests
from fake_useragent import UserAgent
import json
import pandas as pd
import time
import datetime
#comment_api = 'https://maimai.cn/sdk/web/gossip_list?u=206793936&channel=www&version=4.0.0&_csrf=7ZRpwOSi-JHa7JrTECXLA8njznQZVbi7d4Uo&access_token=1.b7e3acc5ef86e51a78f3410f99aa642a&uid=%22MRlTFjf812rF62rOeDhC6vAirs3A3wL6ApgZu%2Fo1crA%3D%22&token=%22xoNo1TZ8k28e0JTNFqyxlxg%2BdL%2BY6jtoUjKZwE3ke2IZ919o%2FAUeOvcX2yA03CAx8CKuzcDfAvoCmBm7%2BjVysA%3D%3D%22&page={}&jsononly=1'
# 发送get请求
comment_api = 'https://maimai.cn/sdk/web/gossip_list?u=206793936&channel=www&version=4.0.0&_csrf=FfHZIyBb-H4LEs35NcyhyoAvRM7OkMRB0Jpo&access_token=1.0d4c87c687410a15810ee6304e1cd53b&uid=%22MRlTFjf812rF62rOeDhC6vAirs3A3wL6ApgZu%2Fo1crA%3D%22&token=%22G7rGLEqmm1wY0HP4q%2BxpPFCDj%2BHqGJFm0mSa%2BxpqPg47egJdXL%2FriMlMlHuQj%2BgM8CKuzcDfAvoCmBm7%2BjVysA%3D%3D%22&page={}&jsononly=1'
"""
author:作者
text:评论
cmts :评论数
circles_views:被查看数
spread :转发数
likes :点赞数
time : 时间
"""
headers = { "User-Agent": UserAgent(verify_ssl=False).random}
j = 0
k = 0
response_comment = requests.get(comment_api.format(0),headers = headers)
json_comment = response_comment.text
json_comment = json.loads(json_comment)
num = json_comment['total']
cols = ['author','text','cmts','likes','circles_views','spreads','time']
dataall = pd.DataFrame(index = range(num),columns = cols)
remain = json_comment['remain']
print(remain)
while remain!= 0 :
n = json_comment['count']
for i in range(n):
if json_comment['data'][i]['text'] !='下面内容已经看过了,点此刷新':
dataall.loc[j,'author'] = json_comment['data'][i]['author']
dataall.loc[j,'text'] = json_comment['data'][i]['text']
dataall.loc[j,'cmts'] = json_comment['data'][i]['cmts']
dataall.loc[j,'likes'] = json_comment['data'][i]['likes']
dataall.loc[j,'circles_views'] = json_comment['data'][i]['circles_views']
dataall.loc[j,'spreads'] = json_comment['data'][i]['spreads']
dataall.loc[j,'time'] = json_comment['data'][i]['time']
j+= 1
else:
k = -1
break
k+= 1
comment_api1 = comment_api.format(k)
response_comment = requests.get(comment_api1,headers = headers)
json_comment = response_comment.text
json_comment = json.loads(json_comment)
remain = json_comment['remain']
print('已完成 {}% !'.format(round(j/num*100,2)))
time.sleep(3)
dataall = dataall.dropna()
dataall = dataall.drop_duplicates()
dataall.to_csv('data_20181216_part3.csv',index = False)
数据可视化
就这样断断续续爬了一堆文件去重之后,得到了4027条数据,格式如下:

接下来对爬到的数据做一些简单的分析。因为并不没有爬到全量评论,只是一个小样本,所以结果肯定是有偏的,但爬的时间很随机,而且前前后后爬了两周多,这样选样也比较随机,还是有一定的代表性。
脉脉中发言用户有两类,一类是完全匿名的,用系统生成的昵称,一类显示为xx公司员工,我们统计爬到的样本中这两种用户的数量及发帖量。4027条职言中,不同发帖人共计1100名。

匿名发帖人超过70%,大家都并不愿意用真实身份发言,毕竟被公司/学校人肉风险还是很高的。
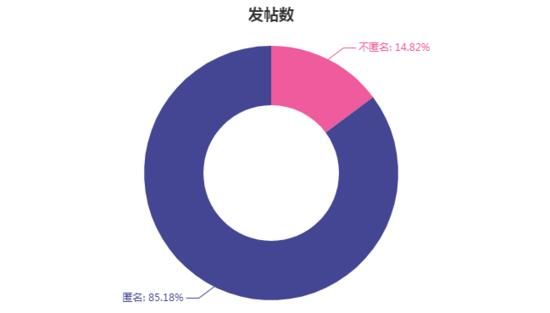
发帖数也毫无意外,匿名发帖人贡献了85%以上的帖子。
匿名发帖人无法获取更细致的数据,但对于那些不匿名的发帖人,可以获取他们所在公司信息,将发帖数按公司汇总,看各大企业发帖量,可以作为整体的一个估计。统计时已经考虑了公司名称输入不一致的情况,将蚂蚁金服、支付宝等替换成了阿里巴巴,京东金融等替换成京东,今日头条、抖音等替换为字节跳动,取发帖数TOP20。
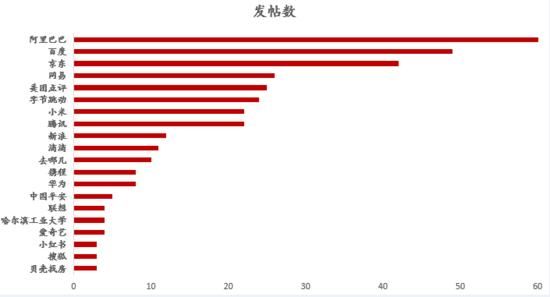
可以看到,发帖人大多来自互联网企业,金融、地产等其他企业相对较少。
文本分析
对于转发、评论数、点赞数,因为有爬取时间上的差异,所以不好直接比较,给出评论数最多的前5条评论,看看大家最愿意参与的话题是什么。
1. 用一个字概括一下你的2018年。(1659条评论) 2. 【再就业求助帖】本人是刚被优化掉的知乎程序员,工作3年。比较想去BAT等大厂,希望贵厂HR们带公司认证来回复一下,发一发真实有hc的岗位,祝愿兄弟们都能找到新工作。(610条评论) 3. 用两个字概括你现在的工作。(477条评论) 4. 网易涨今年薪涨了50%.....公司是发财了吗?(458条评论) 5. 用2个字总结你的工作。(415条评论)
1、4、5都是蛮有意思的问题,我们把1、4、5的评论都爬下来,做成词云,看看大家都在说些什么。
用一个字概括你的2018年
爬虫过程跟上面基本是一样的,找到json,不过这个可以爬到全部评论。
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 19 18:50:03 2018
"""
import urllib
import requests
from fake_useragent import UserAgent
import json
import pandas as pd
import time
# 发送get请求
comment_api = 'https://maimai.cn/sdk/web/gossip/getcmts?gid=18606987&page={}&count=50&hotcmts_limit_count=1&u=206793936&channel=www&version=4.0.0&_csrf=38244DlN-X0iNIk6A4seLXFx6hz3Ds6wfQ0Y&access_token=1.9ff1c9df8547b2b2c62bf58b28e84b97&uid=%22MRlTFjf812rF62rOeDhC6vAirs3A3wL6ApgZu%2Fo1crA%3D%22&token=%22rE8q1xp6fZlxvwygWJn1UFDjrmMXDrSE2tc6uDKNIDZtRErng0FRwvduckWMwYzn8CKuzcDfAvoCmBm7%2BjVysA%3D%3D%22'
"""
author:作者
text:评论
、
"""
#headers = { "User-Agent": UserAgent(verify_ssl=False).random,'Cookie':cookie}
headers = { "User-Agent": UserAgent(verify_ssl=False).random}
j = 0
k = 0
response_comment = requests.get(comment_api.format(0),headers = headers)
json_comment = response_comment.text
json_comment = json.loads(json_comment)
num = json_comment['total']
cols = ['author','text']
dataall = pd.DataFrame(index = range(num),columns = cols)
while j < num :
n = json_comment['count']
for i in range(n):
dataall.loc[j,'author'] = json_comment['comments'][i]['name']
dataall.loc[j,'text'] = json_comment['comments'][i]['text']
j+= 1
k += 1
comment_api1 = comment_api.format(k)
response_comment = requests.get(comment_api1,headers = headers)
json_comment = response_comment.text
json_comment = json.loads(json_comment)
print('已完成 {}% !'.format(round(j/num*100,2)))
time.sleep(3)
dataall.to_excel('用一个字概括你的2018年.xlsx')
爬下来之后,删掉超过一个字的评论,按词频确定大小,做词云图如下:

用两个字概括你现在的工作/用2个字总结你的工作
2、5是一样的,爬下来合并到一起后分析。代码不再重复,实际上用上面那段代码,找到json地址后替换,任何一个话题下的评论都可以全爬到,删掉不是2个字的评论后根据词频作图:

使用SnowNLP对评论进行情感分析,最终4027条中,积极的有2196条,消极的有1831条。
积极:

消极:

模型对大部分评论的情感倾向判断的比较准确,小部分有误。
最后对所有评论提取关键词做词云收尾:

万水千山总是情,点个「好看 」行不行。