利用中文数据跑Google开源项目word2vec
一直听说word2vec在处理词与词的相似度的问题上效果十分好,最近自己也上手跑了跑Google开源的代码(https://code.google.com/p/word2vec/)。
1、语料
首先准备数据:采用网上博客上推荐的全网新闻数据(SogouCA),大小为2.1G。
从ftp上下载数据包SogouCA.tar.gz:
1 wget ftp://ftp.labs.sogou.com/Data/SogouCA/SogouCA.tar.gz [email protected] --ftp-password=4FqLSYdNcrDXvNDi -r
解压数据包:
1 gzip -d SogouCA.tar.gz 2 tar -xvf SogouCA.tar
再将生成的txt文件归并到SogouCA.txt中,取出其中包含content的行并转码,得到语料corpus.txt,大小为2.7G。
1 cat *.txt > SogouCA.txt 2 cat SogouCA.txt | iconv -f gbk -t utf-8 -c | grep "" > corpus.txt
2、分词
用ANSJ对corpus.txt进行分词,得到分词结果resultbig.txt,大小为3.1G。
分词工具ANSJ参见 http://blog.csdn.net/zhaoxinfan/article/details/10403917
在分词工具seg_tool目录下先编译再执行得到分词结果resultbig.txt,内含426221个词,次数总计572308385个。
分词结果:

3、用word2vec工具训练词向量
1 nohup ./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -binary 1 &
vectors.bin是word2vec处理resultbig.txt后生成的词的向量文件,在实验室的服务器上训练了1个半小时。
4、分析
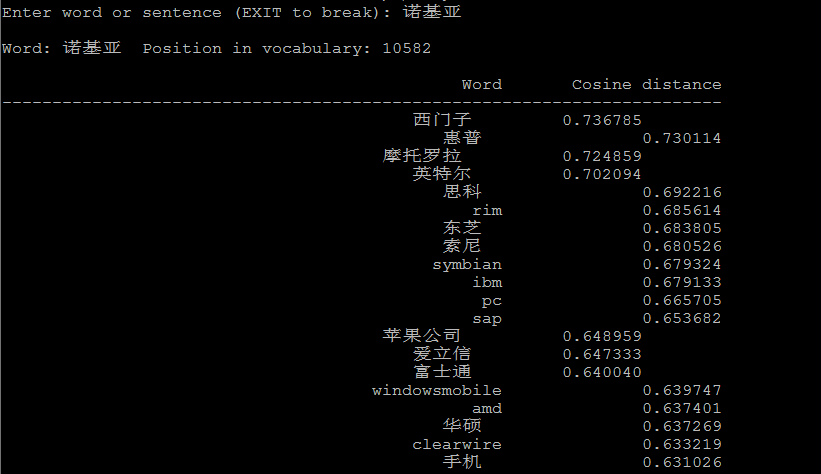
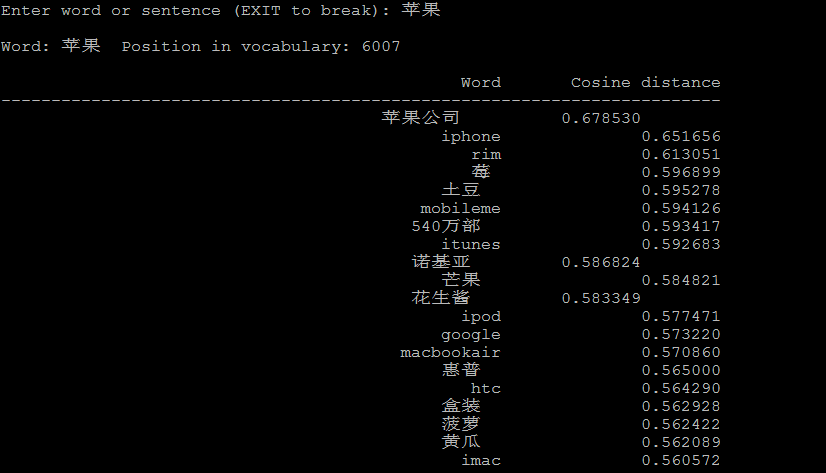
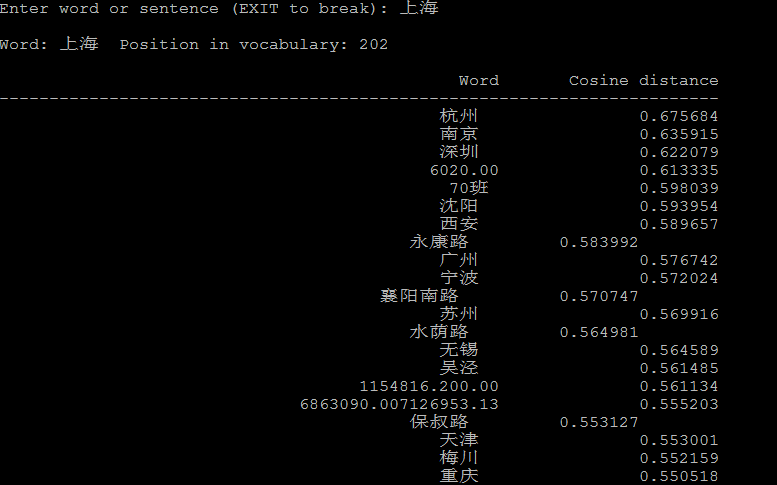
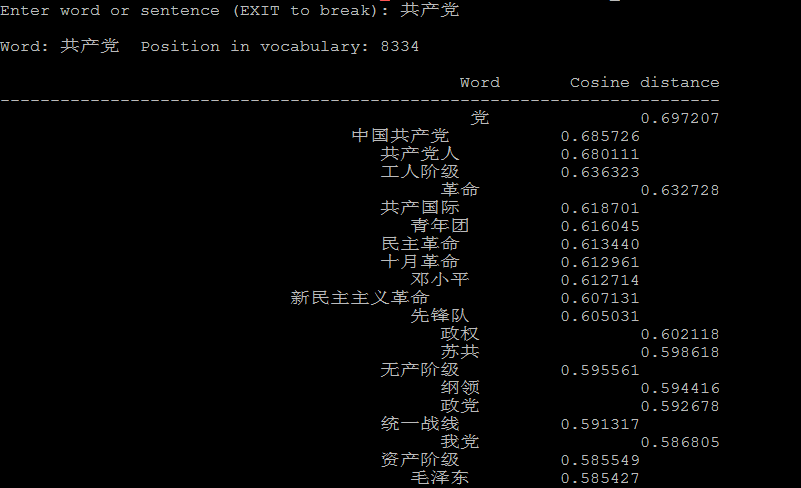
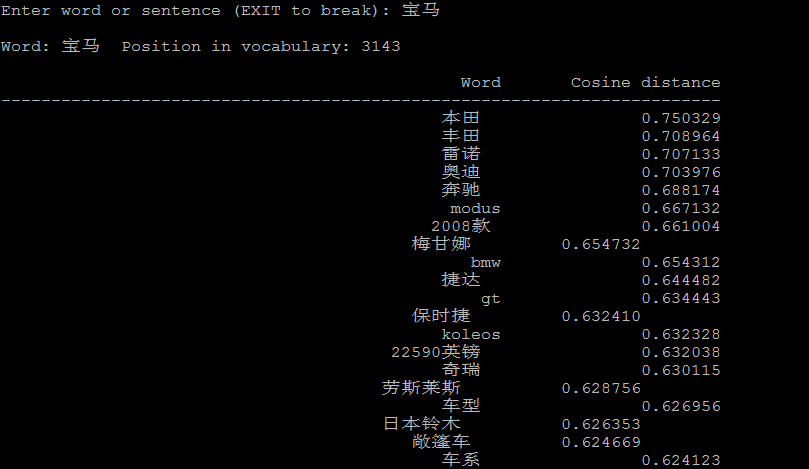
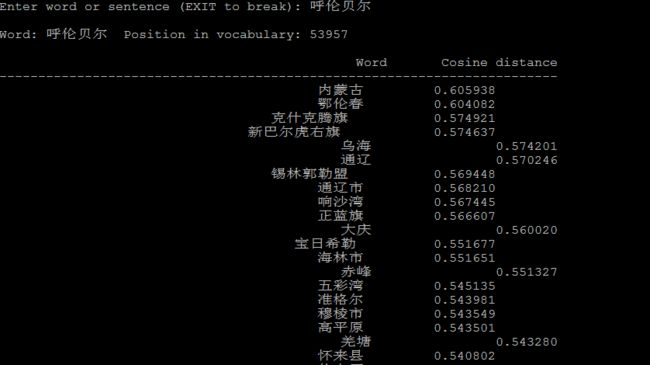
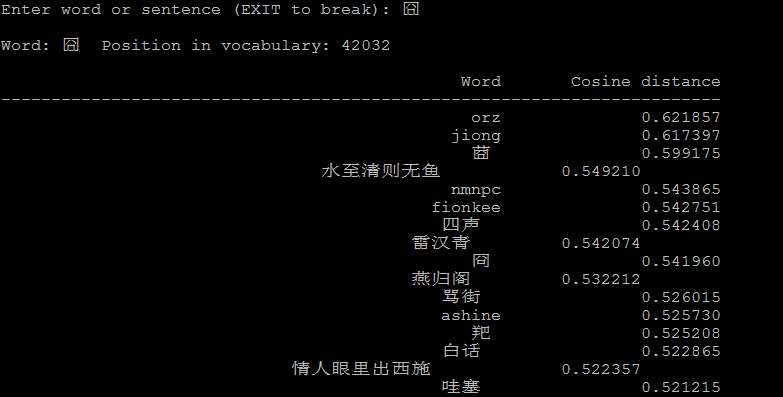
4.1 计算相似的词:
1 ./distance vectors.bin
./distance可以看成计算词与词之间的距离,把词看成向量空间上的一个点,distance看成向量空间上点与点的距离。
下面是一些例子:

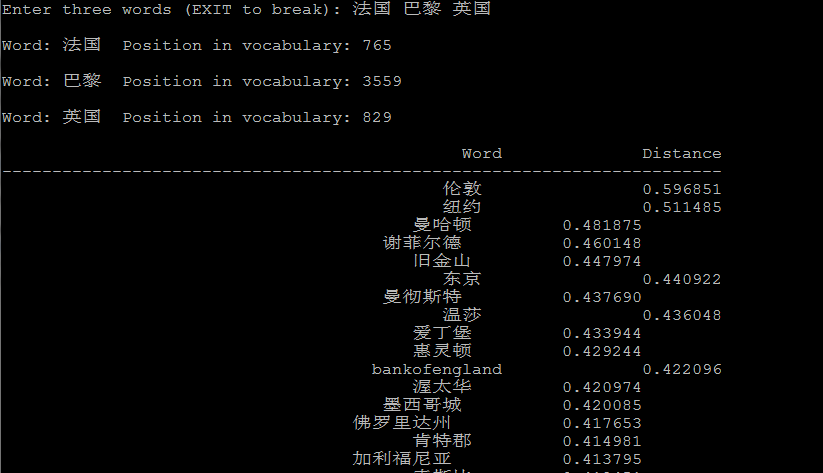
4.2 潜在的语言学规律
在对demo-analogy.sh修改后得到下面几个例子:
法国的首都是巴黎,英国的首都是伦敦, vector("法国") - vector("巴黎) + vector("英国") --> vector("伦敦")"
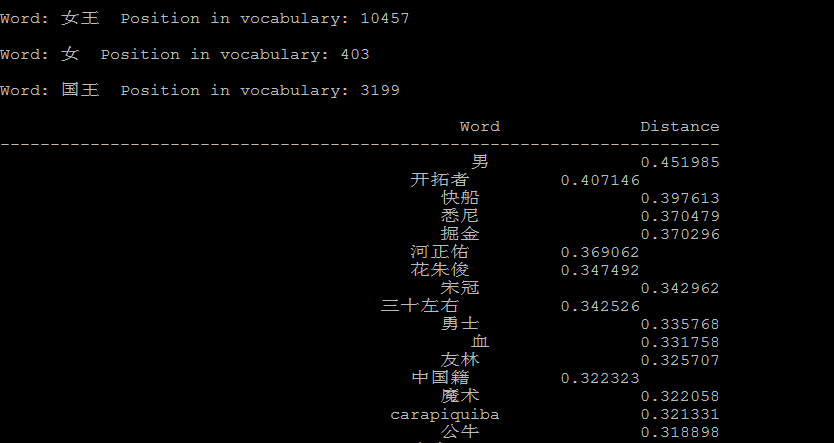
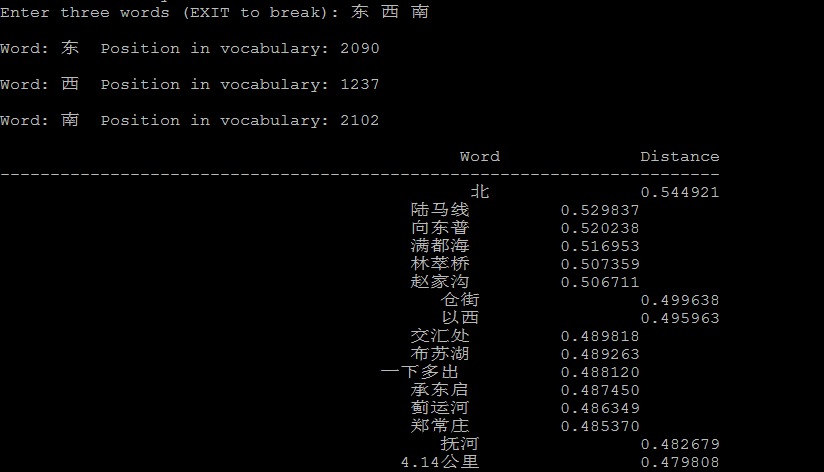
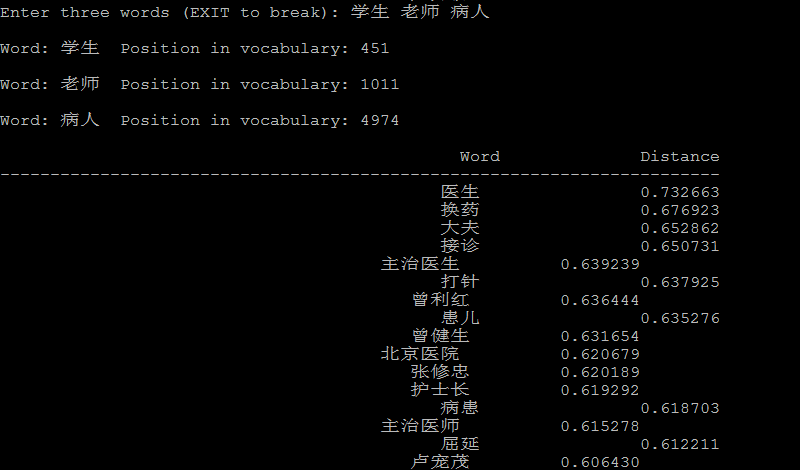
4.3 聚类
将经过分词后的语料resultbig.txt中的词聚类并按照类别排序:
1 nohup ./word2vec -train resultbig.txt -output classes.txt -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -classes 500 & 2 sort classes.txt -k 2 -n > classes_sorted_sogouca.txt
例如:
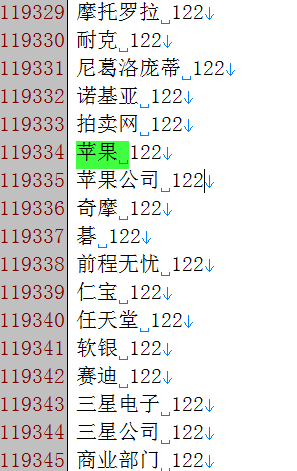

4.4 短语分析
先利用经过分词的语料resultbig.txt中得出包含词和短语的文件sogouca_phrase.txt,再训练该文件中词与短语的向量表示。
1 ./word2phrase -train resultbig.txt -output sogouca_phrase.txt -threshold 500 -debug 2 2 ./word2vec -train sogouca_phrase.txt -output vectors_sogouca_phrase.bin -cbow 0 -size 300 -window 10 -negative 0 -hs 1 -sample 1e-3 -threads 12 -binary 1
下面是几个计算相似度的例子:
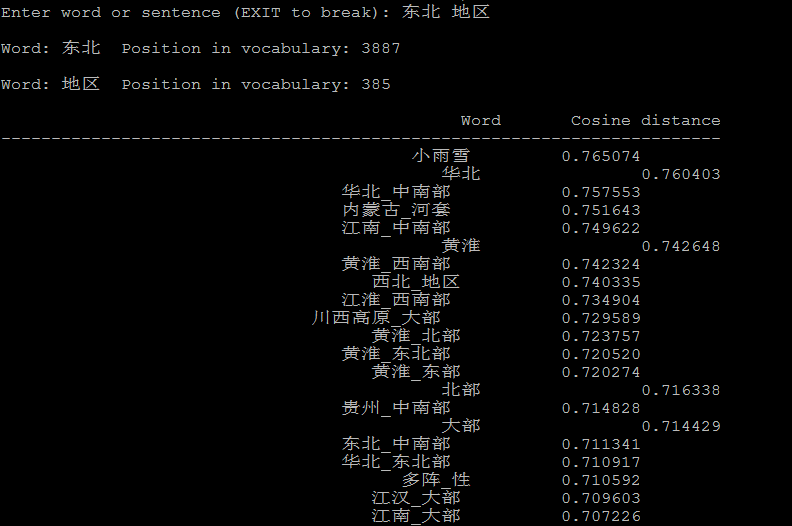
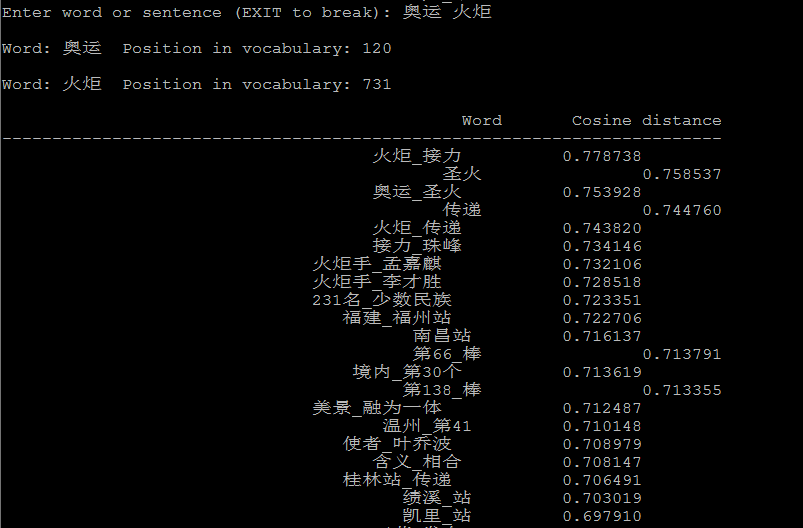
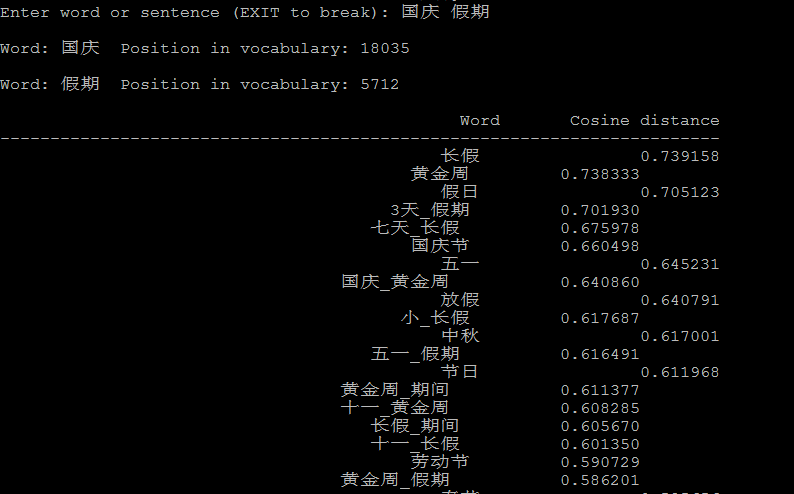
5、参考链接:
1. word2vec:Tool for computing continuous distributed representations of words,https://code.google.com/p/word2vec/
2. 用中文把玩Google开源的Deep-Learning项目word2vec,http://www.cnblogs.com/wowarsenal/p/3293586.html
3. 利用word2vec对关键词进行聚类,http://blog.csdn.net/zhaoxinfan/article/details/11069485
6、后续准备仔细阅读的文献:
[1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
[2] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
[3] Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL HLT, 2013.
[4] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. The Journal of Machine Learning Research, 2011, 12: 2493-2537.