卷积码和Turbo码
通信原理相关博文目录:目录
我们常在移动通信中遇到的卷积码就是一种非分组码,卷积码和信号处理中的卷积运算有关系吗?
是不是就是信号处理中的卷积运算,先看看编码器的编码原理再说:
下面是一个比较实用的卷积码编码器:
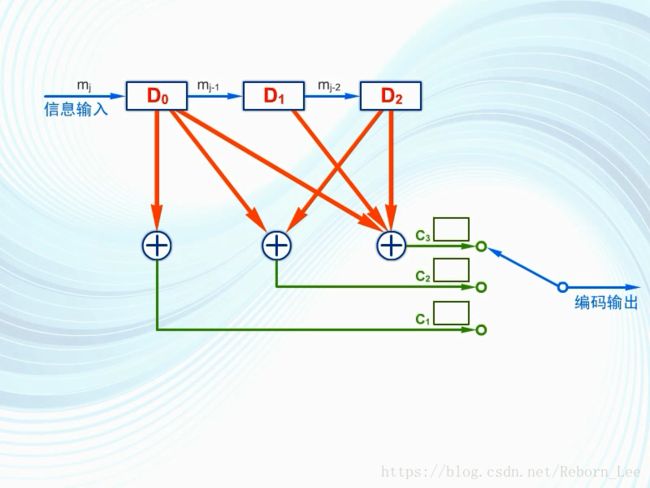
它有三个移位寄存器D0,D1,D2和三个模2加法器,以及一个旋转开关组成,编码前,先将各级移位寄存器清零:

现在假设输入的信息码元是1101:

当输入的第一个码元为1时,三个模2加法器计算的结果都为1:

旋转开关在这个间隙内依次接到c1,c2,c3:



因此编码输出为111:

输入第二个码元1时,之前的码元右移一位,输出为110:


以此类推,输入码元0时,输出010:

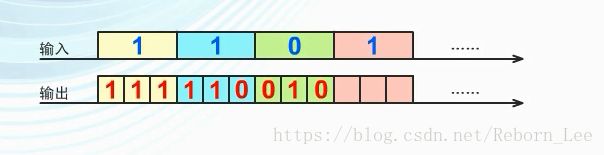
输入最后一个码元1时,输出100:
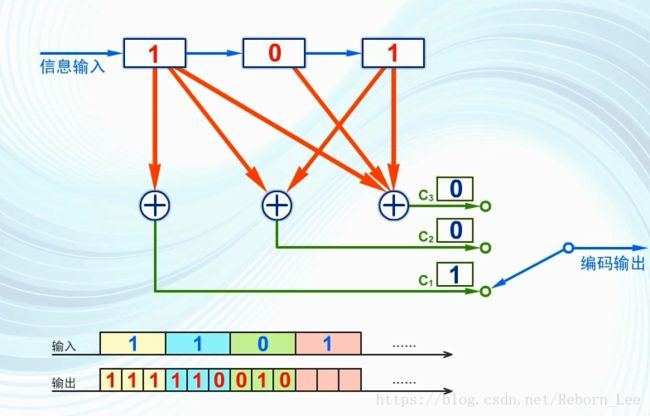

因此输入1101,编码输出为:
111 110 010 100。
其中每一码组的监督码元都和本码组的信息码元,以及前两组的信息码元有关,也就是说本码组的监督码不仅监督本码组,而且对前面两个码组也有监督作用,这是和分组码特别不同的地方,分组码的监督码仅监督本码组的信息,所以把分组码表示成(n,k),而把卷积码表示为(n,k,m),其中n为分组长度,k为分组中的信息码元数目,m为本信息段之前的相关信息段数目,显然一个码组的监督码元监督着m+1个信息段,因此也将N=m+1称为码组的约束长度,在本例中,相关数值如下:

编码效率:

既然卷积码也有码组,为什么说它不是分组码呢?
真正的分组应该是独立的,但卷积码的码组之间是有着约束关系的,另外,分组码有着严格的代数结构,而卷积码至今尚未找到如此严谨的数学手段,因此不能简单的应用代数译码,实际上大多数译码器采用的是概率译码,这其中最流行的当属维特比译码了。
维特比译码,现在不说。
现在可以回答一开始的那个问题了,卷积编码和卷积运算有什么关系呢?
自然是有关系的,直观上,卷积编码过程具有翻转、右移、叠加和相关等特征,这个咱们在信号中演示的卷积运算何其相似啊。

实际上,在数学推算中,每输入一个信息码组,所获得的输出码组,的确可以看做由卷积运算得来的,这也是卷积码名称的由来。
下面介绍Turbo码:




所谓最大似然,就是最像的意思。
因为编码是随机的,没有严格的代数运算,所以译码就只能看收到的码组最像哪个许用码组,就判为哪个码组。
既要码组很长,又要最大似然译码,听说这是左右为难的事情?
因为码组加长,译码难度就会成指数增长,所以长期以来,人们都认为,随机编译码仅仅是香农为证明定理的存在而引入的理论方法,实际上是不可能实现的,但是Turbo码的出现,显然改变了这一人们固有的观念。
Turbo码的思想是利用短码来构造长码,通过对长码的伪随机交织,实现大约束长度的随机编码。
而在译码时,则使用迭代译码,将长码化成短码,从而以较小复杂度来获得接近最大似然译码的性能。
编码器结构:

由两个递归系统卷积编码器通过交织器并行级联而成,所以Turbo码也被称为并行级联卷积码。
这个所谓的递归系统卷积编码器,简称RSC编码器。
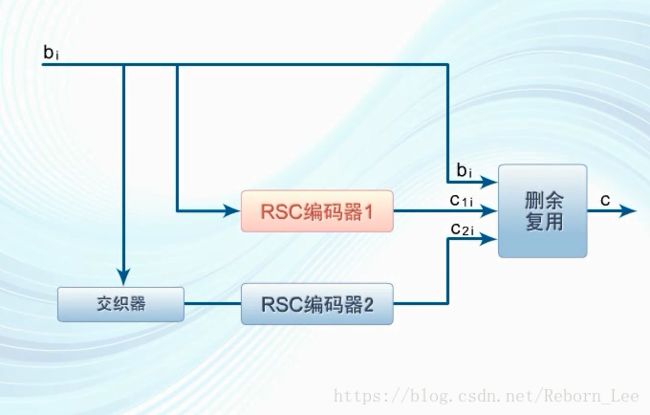
RSC编码器和前面讨论的卷积编码器主要的区别是每一个移位寄存器的输出,都有反馈回信息的输入端,
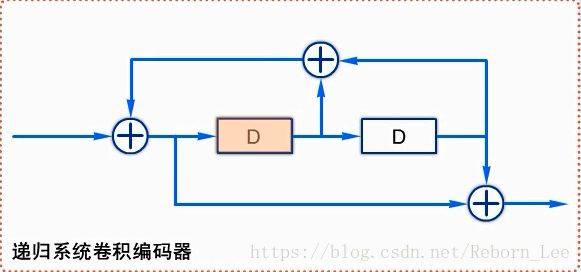


这就是所谓的递归的意思:

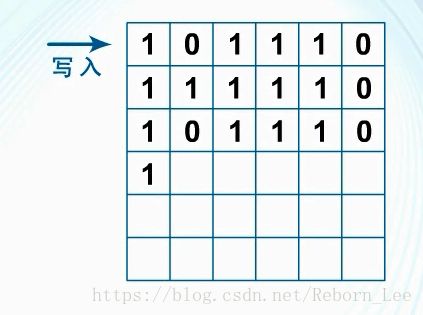
交织器的基本原理:

将输入序列按行写入,
按列读出,
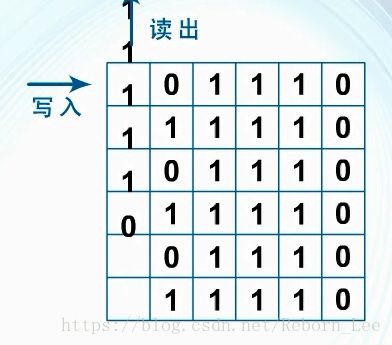
目的是将突发的错码分散开,变成随机错码,使两个RSC编码器趋近独立,同时可以变短码为长码,使之接近香农定理的条件,也就是码组足够长,并且是随机的。
然后删余,是为了提高编码效率,周期删除一些多余的校验位,
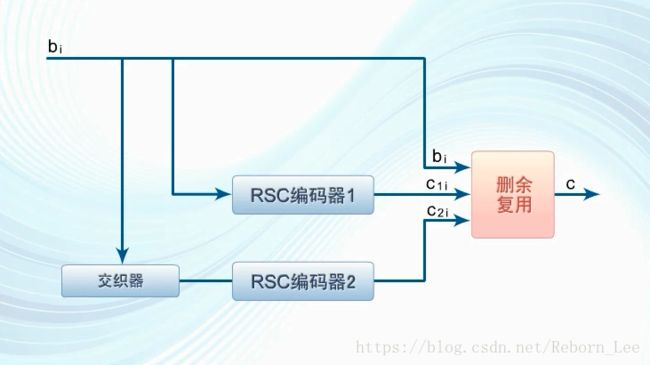
复用则是一种并串转换,将信息位和校验位合并输出,

Turbo码译码原理:
这是Turbo码译码器的基本结构,编码器用了两个RSC编码器,译码时相应用了连个译码器,

收到编码器发来的编码序列后,

首先要进行串并转换,分离出信息序列,和两个校验序列,对于那些要删余的地方要补0,


译码器1并没有对信息序列作判决,而是产生一个被称为外信,1的可信度译码信息,这个信息可以帮组译码器2对信息序列作更精确的判断,这里的交织器的作用是使译码器2的输入信息,在所有时刻上都是相对应的,译码器2用与译码器1同样的方法,再次产生一个外信息2,这个外信息2经过去交织后,反馈回译码器1,作为译码器1的输入,这一过程就称为循环迭代。

经过多次循环迭代后,译码器2对信息序列的判断会更为精确,最后对译码器2输出的似然序列去交织后,再进行一次硬判决,就得到了最终的输出信息。
综上,编码用递归,译码用迭代。
分组码,卷积码,Turbo码的优缺点?
分组码是在严密的代数理论上建立的,因而它的编译码电路都比较简单,应用较为广泛,适合于发现和纠正突发错误,所谓突发错误,即错误突然集中发生;
卷积码可以纠正随机错码,而且在码率和复杂性相同的情况下,卷积码的性能优于分组码;
Turbo码的编码性能无疑是这几种码中最好的,但大家都看到了,编译码较为复杂,相比之下有较大的延迟,所以通常只应用在对延迟不太敏感的数据通信中。