作者: 一字马胡
转载标志 【2017-11-03】
更新日志
| 日期 | 更新内容 | 备注 |
|---|---|---|
| 2017-11-03 | 添加转载标志 | 持续更新 |
ChannelHandler
Netty线程模型及EventLoop详解
Netty源码分析之服务端Accept过程详解
对于Netty的认识正在逐步加深,目前为止,分析了Netty的线程模型以及它的EventLoop的实现,以及一些关于EventLoopGroup的内容,并且知道了一个Channel是怎么被分配给一个EventLoop来支持读写事件的,以及一个Channel的事件循环是如何运转起来的。现在来分析如何使用Netty来实现服务端和客户端的业务逻辑。服务端accept一个新的Channel之后,需要监听这个Channel上的事件,并且将所发生的事件投递到正确的handler上来处理,Netty使用ChannelHandler组件来处理Channel上发生的事件,处理完成之后再将结果发送出去,而ChannelPipeline就是将多个ChannelHandler组合在一起,形成一个链条,这个链条会拦截Channel上的事件,然后在链条中传播。
ChannelHandlerContext是一个特别重要的组件,首先,每一个新创建的Channel都会分配给一个ChannelPipeline,而ChannelHandlerContext将ChannelHandler和ChannelPipeline联系起来,ChannelHandlerContext提供了和ChannelPipeline类似的方法,但是调用ChannelHandlerContext上的方法只会从当前ChannelHandler开始传播,并且只会传播到下一个ChannelHandler上,而调用ChannelPipeline上的方法会沿着链条一直传递下去。
ChannelHandler分为ChannelInboundHandler和ChannelOutboundHandler,分别代表入站处理器和出站处理器,在实际应用中,我们没必要直接实现ChannelInboundHandler接口或者ChannelOutboundHandler接口,下面的图片展示了Netty为我们提供的一些实现子类:
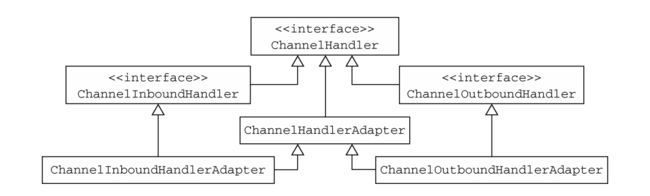
对于入站处理,我们只需要继承ChannelInboundHandlerAdapter就可以了,然后重写我们需要的方法,对于出站处理来说,只需要继承ChannelOutboundHandlerAdapter子类,然后重写需要的接口就可以了。如果我们不再希望将事件传递下去,你应该在处理完消息之后释放它,否则这个消息会一直传递下去直到最后一个处理器。
ChannelPipeline
ChannelPipeline将多个ChannelHandler链接在一起来让事件在其中传播处理。一个ChannelPipeline中可能不仅有入站处理器,还有出站处理器,入站处理器只会处理入站的事件,而出站处理器只会处理出站的数据,下面展示了一个同时具有入站处理器和出站处理器的ChannelPipeline:
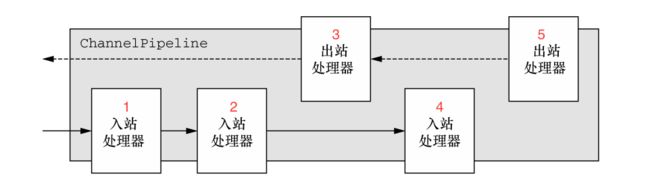
下面的图片展示了一另外一种理解ChannelPipeline的事件拦截处理过程,左边的流程为入站数据的拦截与处理过程,而右边则体现了出站数据的拦截与处理过程,从某种意义上可以这样理解出站与入站,如果表现出某种主动性,比如write这样想要发送数据到对等端的事件就是出站事件,它是事件源头,而被动消费数据的一方比如read就是入站事件,它是某种意义上事件的尾部(其中有若干个ChannelHandler来消费数据)。

需要注意的是,对于入站事件,总是从左往右传播事件,所以图中第一个处理入站数据的ChannelHandler是1,然后是2,然后是4,对于出站事件来说,总是从右往左传播事件,所以图中第一个处理出站数据的ChannelHandler是5,然后是3。为了探索Netty究竟是如何实现ChannelPipeline的,下面来分析一下代码。为了结合实例,下面展示了一段使用Netty编写的服务端代码:
// Configure the server.
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 100)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
p.addLast(new EchoServerHandler());
}
});
// Start the server.
ChannelFuture f = b.bind(PORT).sync();
// Wait until the server socket is closed.
f.channel().closeFuture().sync();
} finally {
// Shut down all event loops to terminate all threads.
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
注意childHandler这个方法,这个方法里面传递了一个ChannelInitializer类型的对象,ChannelInitializer继承了ChannelInboundHandlerAdapter类,所以它是一个入站处理器,当这个参数调用它的initChannel方法的时候就会去初始化ChannelPipeline,什么时候会调用initChannel这个方法呢?
下面是我追踪的方法调用链条:
-> ChannelInitializer.initChannel
-> ChannelInitializer.channelRegistered
-> AbstractChannelHandlerContext.invokeChannelRegistered
-> AbstractChannelHandlerContext.fireChannelRegistered
-> AbstractChannel.AbstractUnsafe.register0
-> AbstractChannel.AbstractUnsafe.register
-> AbstractBootstrap.initAndRegister
-> AbstractBootstrap.doBind
-> AbstractBootstrap.bind
上面的方法调用时倒过来的,最开始的方法是AbstractBootstrap.bind方法,这个已经分析过了,其实将这个调用链路和EventLoop的初始化结合起来,就可以理解ChannelInitializer的initChannel方法是怎么被执行的了。也就可以理解ChannelPipeline是什么时候被初始化的了,知道了是什么时候被初始化的,那下面来分析一下
ChannelPipeline是怎么初始化的,以及ChannelPipeline的工作方式是怎么样的。其实第一个问题很简单,因为我们上文已经分析了initChannel被执行的流程,并且已经知道ChannelPipeline是在initChannel方法中被初始化的,那初始化过程的分析只需要沿着initChannel方法往下追踪就可以发现了,下面来看一下这个方法被执行的上下文:
private boolean initChannel(ChannelHandlerContext ctx) throws Exception {
if (initMap.putIfAbsent(ctx, Boolean.TRUE) == null) { // Guard against re-entrance.
try {
initChannel((C) ctx.channel()); //在这里初始化,调用用户编写的initChannel方法
} catch (Throwable cause) {
// Explicitly call exceptionCaught(...) as we removed the handler before calling initChannel(...).
// We do so to prevent multiple calls to initChannel(...).
exceptionCaught(ctx, cause);
} finally {
remove(ctx);
}
return true;
}
return false;
}
可以发现,在调用了initChannel之后,有一个remove方法被调用了,参数是ctx。下面来分析一下remove方法到底做了什么:
private void remove(ChannelHandlerContext ctx) {
try {
ChannelPipeline pipeline = ctx.pipeline();
if (pipeline.context(this) != null) {
pipeline.remove(this);
}
} finally {
initMap.remove(ctx);
}
}
public final ChannelHandlerContext context(ChannelHandler handler) {
if (handler == null) {
throw new NullPointerException("handler");
}
AbstractChannelHandlerContext ctx = head.next;
for (;;) {
if (ctx == null) {
return null;
}
if (ctx.handler() == handler) {
return ctx;
}
ctx = ctx.next;
}
}
结合两个方法,我们可以得出结论,在执行了initChannel方法之后,Pipeline会将这个this从Pipeline中删除掉,而this是什么?就是我们当初为服务端配置的那个ChannelInitializer,ChannelInitializer是一种特殊的ChannelHandler,它可以作为Pipeline初始化的handler,初始化完成之后它会自动被Pipeline删除,仅留下我们配置的ChannelHandler。
至此,我们已经分析了ChannelInitializer的initChannel方法调用的全链路,并且可以知道ChannelInitializer在初始化Pipeline完成之后就会从其中删除,留下用户配置的ChannelHandler,下面来分析一下ChannelPipeline是如何工作的。首先,我们在上面的remove方法中貌似看出了一些猫腻,ChannelPipeline貌似是一种链表,在上文中也提到ChannelPipeline是一种链表,并且它是一种双向链表,对于入站数据来说将从左到右传播数据,而对于出站数据则从右往左传播数据。为了更好的分析它,现在结合实际的例子看一下。在上面给出的例子中,有类似下面的代码:
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
//p.addLast(new LoggingHandler(LogLevel.INFO));
p.addLast(new EchoServerHandler());
}
在initChannel中使用了Pipeline的addLast方法来将我们的EchoServerHandler添加到Pipeline的尾端,我们来看一下addLast方法的内容:
public final ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler) {
final AbstractChannelHandlerContext newCtx;
synchronized (this) {
checkMultiplicity(handler);
newCtx = newContext(group, filterName(name, handler), handler);
addLast0(newCtx);
// If the registered is false it means that the channel was not registered on an eventloop yet.
// In this case we add the context to the pipeline and add a task that will call
// ChannelHandler.handlerAdded(...) once the channel is registered.
if (!registered) {
newCtx.setAddPending();
callHandlerCallbackLater(newCtx, true);
return this;
}
EventExecutor executor = newCtx.executor();
if (!executor.inEventLoop()) {
newCtx.setAddPending();
executor.execute(new Runnable() {
@Override
public void run() {
callHandlerAdded0(newCtx);
}
});
return this;
}
}
callHandlerAdded0(newCtx);
return this;
}
private void addLast0(AbstractChannelHandlerContext newCtx) {
AbstractChannelHandlerContext prev = tail.prev;
newCtx.prev = prev;
newCtx.next = tail;
prev.next = newCtx;
tail.prev = newCtx;
}
从上面的方法调用来看,ChannelPipeline并不允许你重复插入ChannelHandler到Pipeline中去,并且Pipeline管理的双向链表貌似存储的不是ChannelHandler本身,而是使用newContext方法将其变为了例外一种类型,而这种类型就是我们上文中提到的AbstractChannelHandlerContext,ChannelPipeline管理着的就是一个由多个AbstractChannelHandlerContext节点组成的双向链表,而AbstractChannelHandlerContext内部也是一个双向链表,分别存储着前一个AbstractChannelHandlerContext和后一个AbstractChannelHandlerContext。后面的addLast0就是将新的ChannelHandler保存在双向链表的尾部节点。除了addLast方法,ChannelPipeline还提供了大量操作ChannelPipeline的方法,不仅可以添加ChannelHandler,并且还可以删除ChannelHandler,而且还可以replace,更多的方法参考Netty的Api文档。需要注意的一点是,这些更改是实施动态进行的,这也就预示着我们可以更加灵活的来操作我们的数据,更加动态的对出站和入站的数据进行加工。
ChannelPipeline的事件传播
现在来分析一下ChannelPipeline是如何传播事件的。首先再次说明,ChannelHandler分为出站和入站,不同的事件会走不同的方向。出站类型的handler不会处理入站数据,反过来也是。上文中提到,如果我们想写一个处理入站数据的handler,只需要继承ChannelInboundHandlerAdapter就可以了,而处理出站数据则继承ChannelOutboundHandlerAdapter就可以了。所以我们从这两个类中开始分析,首先分析入站数据在ChannelPipeline中的传播。当有数据可以读的时候,channelRead方法会被触发,下面是它的方法:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ctx.fireChannelRead(msg);
}
可以看到,这个方法仅仅是调用了ChannelHandlerContext的fireChannelRead方法,这个方法在AbstractChannelHandlerContext中被重写,下面是它的实现细节:
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(), msg);
return this;
}
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
可以发现,在fireChannelRead方法中,调用了findContextInbound()方法来寻找下一个符合要求的ChannelHandler,然后调用invokeChannelRead来调用下一个ChannelHandler的invokeChannelRead方法,也就是将时间传递给了下一个ChannelHandler,下面来看一下findContextInbound方法的细节:
private AbstractChannelHandlerContext findContextInbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.next;
} while (!ctx.inbound);
return ctx;
}
AbstractChannelHandlerContext对象会有两个标志inbound和outbound,不同的handler实现会设置相应的标志位。findContextInbound方法的含义就是在ChannelPipeline中寻找下一个属于入站属性的handler,可以看到,寻找的方向是从head到tail。下面来分析一下出站数据传播的细节。我们从ChannelOutboundHandlerAdapter的write方法开始分析:
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ctx.write(msg, promise);
}
当然你需要继承ChannelOutboundHandlerAdapter并且重写write方法来实现你的业务处理逻辑,但是你想要传递数据,你就需要调用ctx.write(msg, promise)方法,它会调用AbstractChannelHandlerContext的等效方法,下面是一个它调用链路上的方法:
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
private AbstractChannelHandlerContext findContextOutbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.prev;
} while (!ctx.outbound);
return ctx;
}
首先通过findContextOutbound方法来寻找下一个符合要求的handler,这个方法将向前寻找,也就是出站事件的传播方向为从后往前。到此我们明白了ChannelPipeline的事件传播方向。对于入站数据,如果传递到了tail节点,会发生什么呢?回忆一下invokeWriteAndFlush方法,它有一个判断invokeHandler()方法,下面是它的细节:
private boolean invokeHandler() {
// Store in local variable to reduce volatile reads.
int handlerState = this.handlerState;
return handlerState == ADD_COMPLETE || (!ordered && handlerState == ADD_PENDING);
}
我们只需要关系handlerState == ADD_COMPLETE的时候会返回true,那么就会执行下面的方法:
invokeWrite0(msg, promise);
invokeFlush0();
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
而invokeWrite0方法中会使用一个方法 handler(),它的意思实际上是返回当前context,我们再来看一下两个特殊的context,一个是head节点,一个是tail节点,下面是它们的构造函数:
HeadContext(DefaultChannelPipeline pipeline) {
super(pipeline, null, HEAD_NAME, false, true);
unsafe = pipeline.channel().unsafe();
setAddComplete();
}
TailContext(DefaultChannelPipeline pipeline) {
super(pipeline, null, TAIL_NAME, true, false);
setAddComplete();
}
final void setAddComplete() {
for (;;) {
int oldState = handlerState;
// Ensure we never update when the handlerState is REMOVE_COMPLETE already.
// oldState is usually ADD_PENDING but can also be REMOVE_COMPLETE when an EventExecutor is used that is not
// exposing ordering guarantees.
if (oldState == REMOVE_COMPLETE || HANDLER_STATE_UPDATER.compareAndSet(this, oldState, ADD_COMPLETE)) {
return;
}
}
}
他们都执行了一个方法setAddComplete,而这个方法的作用就是将状态设置为REMOVE_COMPLETE。也就是说,对于入站事件,要是事件传播到了tail,那么就会执行TailContext的等效方法,比如read,就会执行TailContext的channelRead方法:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
onUnhandledInboundMessage(msg);
}
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug(
"Discarded inbound message {} that reached at the tail of the pipeline. " +
"Please check your pipeline configuration.", msg);
} finally {
ReferenceCountUtil.release(msg);
}
}
可以看到消息传递到tail之后,就不会再传递下去了,并且会释放它。出站事件也是类似,当事件传递到head的时候,会调用HeadContext的等效方法,然后就不会再传递下去了。