Hadoop+Spark+Zookeeper高可用集群搭建(二)
文章目录
- 1. 需下载的文件
- 2. 通过Xftp上传压缩包,并解压
- 3. 安装配置JDK
- 4. 安装Hadoop
- 4.1 上传文件并解压缩
- 4.2 配置Hadoop环境变量
- 4.3 验证Hadoop是否安装成功
- 4.4 配置文件
- 4.4.1 core-site.xml 文件
- 4.4.2 配置hadoop-env.sh文件
- 4.4.3 配置hdfs-site.xml 文件
- 4.4.4 配置mapred-site.xml 文件
- 4.4.5 配置slaves文件
- 4.4.6 配置yarn-site.xml文件
- 5. 安装SSH
- 5.1 yum工具
- 5.2 安装server和clients软件
- 5.3 验证SSH是否安装成功
- 5.3.1 ssh命令
- 5.3.2 rpm验证
1. 需下载的文件
- jdk-1.8
- Hadoop-2.6.5
- zookeeper-3.4.10
- Scala-2.11.12
- spark-2.4.3
2. 通过Xftp上传压缩包,并解压
首先,创建software文件夹,所有文件都存放于software文件夹。
cd ~
mkdir software
3. 安装配置JDK
在解压完JDK后,需要在root用户下配置profile文件
vi /etc/profile
插入以下内容:

需要通过命令:
source /etc/profile
使环境变量生效,然后测试JDK是否安装成功:输入 java - version ,出现JDK版本号则说明安装成功。
4. 安装Hadoop
4.1 上传文件并解压缩
tar -zxf hadoop-2.6.5.tar.gz
4.2 配置Hadoop环境变量
首先,切换到root用户,再次编辑profile文件,插入Hadoop配置:
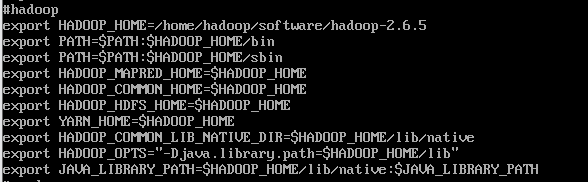
然后,再使环境变量生效,source /etc/profile
4.3 验证Hadoop是否安装成功

4.4 配置文件
4.4.1 core-site.xml 文件
首先,切换到hadoop用户下,进入到hadoop-2.6.5/etc/hadoop目录,使用vi命令编辑此文件,配置内容如下:
<configuration>
<property>
<name>ha.zookeeper.quorumname>
<value>slave001:2181,slave002:2181,slave003:2181value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/software/hadoop-2.6.5/tmpvalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
configuration>
4.4.2 配置hadoop-env.sh文件
此文件同样也是在hadoop-2.6.5/etc/hadoop目录下,使用vi命令编辑,修改java_home地址:

4.4.3 配置hdfs-site.xml 文件
此文件同样也是在hadoop-2.6.5/etc/hadoop目录下,使用vi命令编辑,主要用于配置集群名字空间,访问端口,URL地址,故障转移等信息,配置内容如下:
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>master001:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>master002:9000value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>master001:50070value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>master002:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://slave001:8485;slave002:8485;slave003:8485/QJClustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/home/hadoop/software/hadoop-2.6.5/QJEditsDatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/home/hadoop/software/hadoop-2.6.5/ensure.sh)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
4.4.4 配置mapred-site.xml 文件
Hadoop本身是没有这个文件的,为了方便操作给出了mapred-site.xml.template模板文件,从而复制出该文件:
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
然后,插入以下配置信息:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
4.4.5 配置slaves文件
在HDFS中,DataNode节点用来指定存储数据的节点文件的,所以集群中所有的DataNode节点都需要写入到slaves文件中,Master节点会读取slaves文件来获取相应的存储信息。
vi slaves
删除原本带有的localhost,插入如下图所示内容:

4.4.6 配置yarn-site.xml文件
此文件主要是用于配置ResourceManager进程相关的配置参数:
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>master001value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
5. 安装SSH
由于集群中大量主机进行分布式计算需要相互进行数据通信,服务器之间的连接需要通过SSH来进行。在CentOS系统下,我们可以通过yum在线安装。
5.1 yum工具
yum本身是属于root用户的工具,所以在使用时需要切换到root用户下,再进行在线安装。
5.2 安装server和clients软件
在安装SSH之前需要先查找yum库有哪些SSH软件的rpm包:
 然后,进行在线安装即可:
然后,进行在线安装即可:
yum install -y openssh-clients.x86_64
yum install -y openssh-server.x86_64
5.3 验证SSH是否安装成功
5.3.1 ssh命令
5.3.2 rpm验证
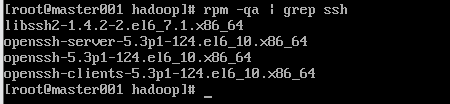
至此,我们单个虚拟机配置已经基本完成。
未完待续。。。