【PyTorch学习笔记】18:pooling,up-sample,ReLU
pooling池化是下采样(down-sample)的一种手段,让feature map减小;而up-sample则是上采样,实际上做了放大图像的操作。
在CNN中,基本的单元是一个Conv2d,后面配上[Batch Norm, pooling, ReLU],后面三个的顺序不一定。
pooling
图像的down-sample
在图像中要缩小图像的尺寸,常用的是隔行采样的方式,例如纵向每隔一行,横向每隔一列采样一个:
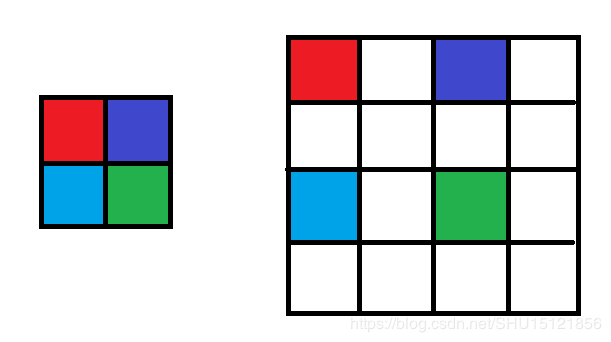
CNN中的pooling
CNN中用一个池化层来完成下down-sample,这个有一个池化核,类似于卷积核一样,不过池化核的移动位置一般是没有重叠的,然后在池化核扫过的地方进行一个函数运算,将其映射到一个新值上,也就完成了down-sample。
例如,最大池化(max pooling):
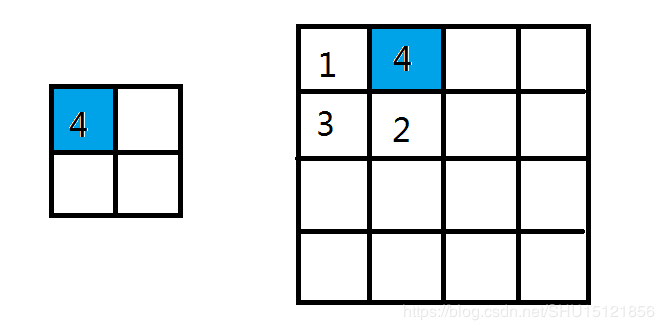
图中Max(1,4,3,2)=4,所以池化运算后映射出的一个值是4。若使用average pooling,那么就是取池化核扫过的小块的平均值作为映射后的值。
在LeNet的架构上,在卷积层后用的还是图像的下采样方式(隔行采样),到了AlexNet就采用了pooling进行下采样。
类式接口
接着上节卷积运算得到的输出,1张16通道的14乘14的图像,在此基础上做池化。
x = out # torch.Size([1, 16, 14, 14])
# 池化层(池化核为2*2,步长为2),最大池化
layer = nn.MaxPool2d(2, stride=2)
out = layer(x)
print(out.shape)
运行结果:
torch.Size([1, 16, 7, 7])
函数式接口
使用函数式接口时,输入值就直接传进去了。
x = out # torch.Size([1, 16, 14, 14])
# 池化运算(池化核为2*2,步长为2),平均池化
out = F.avg_pool2d(x, 2, stride=2)
print(out.shape)
运行结果:
torch.Size([1, 16, 7, 7])
需要注意的是这里的池化stride并不会像Keras里那样默认就没有重叠,而是要手动指定,当它和池化核变长一样时也就是正好没有重叠了。
相比卷积运算,池化运算一定不会改变图像的通道数,其目的就是将其降维,减小其尺寸。
up-sample
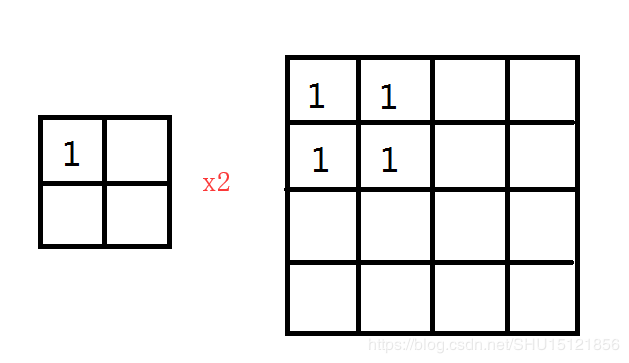
最近插值
最近插值,只要简单复制最近的元素指定的次数就可以了:
函数式接口
x = out # torch.Size([1, 16, 7, 7])
# 向上采样,放大2倍,最近插值
out = F.upsample(x, scale_factor=2, mode='nearest') # 旧的接口
print(out.shape)
out = F.interpolate(x, scale_factor=2, mode='nearest') # 新的接口
print(out.shape)
运行结果:
torch.Size([1, 16, 14, 14])
torch.Size([1, 16, 14, 14])
ReLU
把负的地方映射到0,相当于把feature map中的响应低的部分去掉,并保持正的响应不变。
类式接口
x = out # torch.Size([1, 16, 7, 7])
# ReLU激活,inplace=True表示直接覆盖掉ReLU目标的内存空间
layer = nn.ReLU(inplace=True)
out = layer(x)
print(x.shape)
运行结果:
torch.Size([1, 16, 7, 7])
函数式接口
x = out # torch.Size([1, 16, 7, 7])
# ReLU激活
out = F.relu(x)
print(x.shape)
运行结果:
torch.Size([1, 16, 7, 7])