PyTorch 深度学习:60分钟快速入门
此教程为翻译官方地址
Github 地址
简书地址
CSDN地址
本教程的目标:
- 深入理解PyTorch张量库和神经网络
- 训练一个小的神经网络来分类图片
这个教程假设你熟悉numpy的基本操作。
注意
请确保torch和torchvision包已经安装。
一、PyTorch 是什么
他是一个基于Python的科学计算包,目标用户有两类
- 为了使用GPU来替代numpy
- 一个深度学习援救平台:提供最大的灵活性和速度
开始
张量(Tensors)
张量类似于numpy的ndarrays,不同之处在于张量可以使用GPU来加快计算。
1 2 |
from __future__ import print_function import torch |
构建一个未初始化的5*3的矩阵:
1 2 |
x = torch.Tensor(5, 3) print(x) |
输出 :
1 2 3 4 5 6 7 |
1.00000e-10 * -1.1314 0.0000 -1.1314 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 [torch.FloatTensor of size 5x3] |
构建一个随机初始化的矩阵
1 2 |
x = torch.rand(5, 3) print(x) |
输出:
1 2 3 4 5 6 |
0.2836 0.6710 0.5146 0.8842 0.2821 0.7768 0.3409 0.0428 0.6726 0.1982 0.6950 0.6040 0.0272 0.6586 0.3555 [torch.FloatTensor of size 5x3] |
获取矩阵的大小:
1 |
print(x.size()) |
输出:
1 |
torch.Size([5, 3]) |
注意
torch.Size实际上是一个元组,所以它支持元组相同的操作。
操作
张量上的操作有多重语法形式,下面我们以加法为例进行讲解。
语法1
1 2 |
y = torch.rand(5, 3) print(x + y) |
输出:
1 2 3 4 5 6 |
0.9842 1.5171 0.8148 1.1334 1.6540 1.5739 0.9804 1.1647 0.4759 0.6232 0.2689 1.0596 1.0777 1.1705 0.3206 [torch.FloatTensor of size 5x3] |
语法二
1 |
print(torch.add(x, y)) |
输出:
1 2 3 4 5 6 |
0.9842 1.5171 0.8148 1.1334 1.6540 1.5739 0.9804 1.1647 0.4759 0.6232 0.2689 1.0596 1.0777 1.1705 0.3206 [torch.FloatTensor of size 5x3] |
语法三:给出一个输出向量
1 2 3 |
result = torch.Tensor(5, 3) torch.add(x, y, out=result) print(result) |
输出:
1 2 3 4 5 6 |
0.9842 1.5171 0.8148 1.1334 1.6540 1.5739 0.9804 1.1647 0.4759 0.6232 0.2689 1.0596 1.0777 1.1705 0.3206 [torch.FloatTensor of size 5x3] |
语法四:原地操作(in-place)
1 2 3 |
# 把x加到y上 y.add_(x) print(y) |
输出:
1 2 3 4 5 6 |
0.9842 1.5171 0.8148 1.1334 1.6540 1.5739 0.9804 1.1647 0.4759 0.6232 0.2689 1.0596 1.0777 1.1705 0.3206 [torch.FloatTensor of size 5x3] |
注意
任何在原地(in-place)改变张量的操作都有一个’_‘后缀。例如x.copy_(y), x.t_()操作将改变x.
你可以使用所有的numpy索引操作。
1 |
print(x[:, 1]) |
输出:
1 2 3 4 5 6 |
1.5171 1.6540 1.1647 0.2689 1.1705 [torch.FloatTensor of size 5] |
稍后阅读
这里描述了一百多种张量操作,包括转置,索引,数学运算,线性代数,随机数等。
numpy桥
把一个torch张量转换为numpy数组或者反过来都是很简单的。
Torch张量和numpy数组将共享潜在的内存,改变其中一个也将改变另一个。
把Torch张量转换为numpy数组
1 2 |
a = torch.ones(5) print(a) |
输出:
1 2 3 4 5 6 |
1 1 1 1 1 [torch.FloatTensor of size 5] |
1 2 3 |
b = a.numpy() print(b) print(type(b)) |
输出:
1 2 |
[ 1. 1. 1. 1. 1.] |
通过如下操作,我们看一下numpy数组的值如何在改变。
1 2 3 |
a.add_(1) print(a) print(b) |
1 2 3 4 5 6 7 8 |
2 2 2 2 2 [torch.FloatTensor of size 5] [ 2. 2. 2. 2. 2.] |
把numpy数组转换为torch张量
看看改变numpy数组如何自动改变torch张量。
1 2 3 4 5 6 |
import numpy as np a = np.ones(5) b = torch.from_numpy(a) np.add(a, 1, out=a) print(a) print(b) |
1 2 3 4 5 6 7 8 |
[ 2. 2. 2. 2. 2.] 2 2 2 2 2 [torch.DoubleTensor of size 5] |
所有在CPU上的张量,除了字符张量,都支持在numpy之间转换。
CUDA张量
使用.cuda函数可以将张量移动到GPU上。
1 2 3 4 5 |
# let us run this cell only if CUDA is available if torch.cuda.is_available(): x = x.cuda() y = y.cuda() x + y |
脚本总运行时间:0.003秒
Python源码
Jupyter源码
二、Autograd: 自动求导(automatic differentiation)
PyTorch 中所有神经网络的核心是autograd包.我们首先简单介绍一下这个包,然后训练我们的第一个神经网络.
autograd包为张量上的所有操作提供了自动求导.它是一个运行时定义的框架,这意味着反向传播是根据你的代码如何运行来定义,并且每次迭代可以不同.
接下来我们用一些简单的示例来看这个包
变量(Variable)
autograd.Variable是autograd包的核心类.它包装了张量(Tensor),支持几乎所有的张量上的操作.一旦你完成你的前向计算,可以通过.backward()方法来自动计算所有的梯度.
你可以通过.data属性来访问变量中的原始张量,关于这个变量的梯度被计算放入.grad属性中

对自动求导的实现还有一个非常重要的类,即函数(Function).
变量(Variable)和函数(Function)是相互联系的,并形成一个非循环图来构建一个完整的计算过程.每个变量有一个.grad_fn属性,它指向创建该变量的一个Function,用户自己创建的变量除外,它的grad_fn属性为None.
如果你想计算导数,可以在一个变量上调用.backward().如果一个Variable是一个标量(它只有一个元素值),你不必给该方法指定任何的参数,但是该Variable有多个值,你需要指定一个和该变量相同形状的的grad_output参数(查看API发现实际为gradients参数).
1 2 |
import torch from torch.autograd import Variable |
创建一个变量:
1 2 |
x = Variable(torch.ones(2, 2), requires_grad=True) print(x) |
输出:
1 2 3 4 |
Variable containing: 1 1 1 1 [torch.FloatTensor of size 2x2] |
在变量上执行操作:
1 2 |
y = x + 2 print(y) |
输出:
1 2 3 4 |
Variable containing: 3 3 3 3 [torch.FloatTensor of size 2x2] |
因为y是通过一个操作创建的,所以它有grad_fn,而x是由用户创建,所以它的grad_fn为None.
1 2 |
print(y.grad_fn) print(x.grad_fn) |
输出:
1 2 |
|
在y上执行操作
1 2 3 4 |
z = y * y * 3 out = z.mean() print(z, out) |
输出:
1 2 3 4 5 6 7 |
Variable containing: 27 27 27 27 [torch.FloatTensor of size 2x2] Variable containing: 27 [torch.FloatTensor of size 1] |
梯度(Gradients)
现在我们来执行反向传播,out.backward()相当于执行out.backward(torch.Tensor([1.0]))
1 |
out.backward() |
输出out对x的梯度d(out)/dx:
1 |
print(x.grad) |
输出:
1 2 3 4 |
Variable containing: 4.5000 4.5000 4.5000 4.5000 [torch.FloatTensor of size 2x2] |
你应该得到一个值全为4.5的矩阵,我们把变量out称为o,则o=14∑izi,zi=3(xi+2)2,zi|xi=1=27,因此∂o∂xi=32(xi+2),∂o∂xi=92=4.5
我们还可以用自动求导做更多有趣的事!
1 2 3 4 5 6 7 8 |
x = torch.randn(3)
x = Variable(x, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
|
输出:
1 2 3 4 5 |
Variable containing: 682.4722 -598.8342 692.9528 [torch.FloatTensor of size 3] |
1 2 3 4 |
gradients = torch.FloatTensor([0.1, 1.0, 0.0001]) y.backward(gradients) print(x.grad) |
输出:
1 2 3 4 5 |
Variable containing:
102.4000
1024.0000
0.1024
[torch.FloatTensor of size 3]
|
稍后阅读:
关于Variable和Function的文档在http://pytorch.org/docs/autograd.
以上脚本的总的运行时间为0.003秒.
Python源码
Jupyter源码
三、神经网络
可以使用torch.nn包来构建神经网络.
你已知道autograd包,nn包依赖autograd包来定义模型并求导.一个nn.Module包含各个层和一个forward(input)方法,该方法返回output.
例如,我们来看一下下面这个分类数字图像的网络.
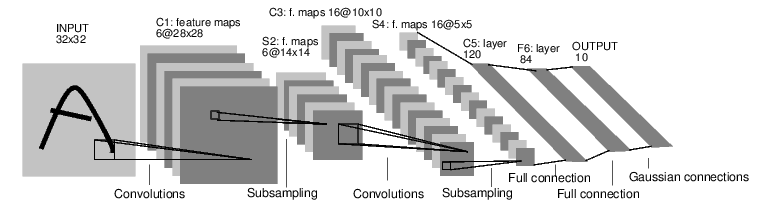
convnet
他是一个简单的前馈神经网络,它接受一个输入,然后一层接着一层的输入,直到最后得到结果.
神经网络的典型训练过程如下:
- 定义神经网络模型,它有一些可学习的参数(或者权重);
- 在数据集上迭代;
- 通过神经网络处理输入;
- 计算损失(输出结果和正确值的差距大小)
- 将梯度反向传播会网络的参数;
- 更新网络的参数,主要使用如下简单的更新原则:
1
weight = weight - learning_rate * gradient
定义网络
我们先定义一个网络
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import torch
from torch.autograd import Variable
import torch.nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5*5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
|
输出:
1 2 3 4 5 6 7 |
Net ( (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear (400 -> 120) (fc2): Linear (120 -> 84) (fc3): Linear (84 -> 10) ) |
你只需定义forward函数,backward函数(计算梯度)在使用autograd时自动为你创建.你可以在forward函数中使用Tensor的任何操作.
net.parameters()返回模型需要学习的参数
1 2 3 4 |
params = list(net.parameters()) print(len(params)) for param in params: print(param.size()) |
输出:
1 2 3 4 5 6 7 8 9 10 11 |
10 torch.Size([6, 1, 5, 5]) torch.Size([6]) torch.Size([16, 6, 5, 5]) torch.Size([16]) torch.Size([120, 400]) torch.Size([120]) torch.Size([84, 120]) torch.Size([84]) torch.Size([10, 84]) torch.Size([10]) |
forward的输入和输出都是autograd.Variable.注意:这个网络(LeNet)期望的输入大小是32*32.如果使用MNIST数据集来训练这个网络,请把图片大小重新调整到32*32.
1 2 3 |
input = Variable(torch.randn(1, 1, 32, 32)) out = net(input) print(out) |
输出:
1 2 3 |
Variable containing: -0.0536 -0.0548 -0.1079 0.0030 0.0521 -0.1061 -0.1456 -0.0095 0.0704 0.0259 [torch.FloatTensor of size 1x10] |
将所有参数的梯度缓存清零,然后进行随机梯度的的反向传播.
1 2 |
net.zero_grad() out.backward(torch.randn(1, 10)) |
注意
torch.nn只支持小批量输入,整个torch.nn包都只支持小批量样本,而不支持单个样本- 例如,
nn.Conv2d将接受一个4维的张量,每一维分别是sSamples nChannels Height Width(样本数\通道数*高*宽). - 如果你有单个样本,只需使用
input.unsqueeze(0)来添加其它的维数.
在继续之前,我们回顾一下到目前为止见过的所有类.
回顾
torch.Tensor-一个多维数组autograd.Variable-包装一个Tensor,记录在其上执行过的操作.除了拥有Tensor拥有的API,还有类似backward()的API.也保存关于这个向量的梯度.nn.Module-神经网络模块.封装参数,移动到GPU上运行,导出,加载等nn.Parameter-一种变量,当把它赋值给一个Module时,被自动的注册为一个参数.autograd.Function-实现一个自动求导操作的前向和反向定义,每个变量操作至少创建一个函数节点,(EveryVariableoperation, creates at least a singleFunctionnode, that connects to functions that created aVariableand encodes its history.)
现在,我们包含了如下内容:
- 定义一个神经网络
- 处理输入和调用
backward
剩下的内容:
- 计算损失值
- 更新神经网络的权值
损失函数
一个损失函数接受一对(output, target)作为输入(output为网络的输出,target为实际值),计算一个值来估计网络的输出和目标值相差多少.
在nn包中有几种不同的损失函数.一个简单的损失函数是:nn.MSELoss,他计算输入(个人认为是网络的输出)和目标值之间的均方误差.
例如:
1 2 3 4 5 6 |
out = net(input) target = Variable(torch.arange(1, 11)) # a dummy target, for example criterion = nn.MSELoss() loss = criterion(out, target) print(loss) |
输出:
1 2 3 |
Variable containing: 38.1365 [torch.FloatTensor of size 1] |
现在,你反向跟踪loss,使用它的.grad_fn属性,你会看到向下面这样的一个计算图:
1 2 3 4 |
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
|
所以, 当你调用loss.backward(),整个图关于损失被求导,图中所有变量将拥有.grad变量来累计他们的梯度.
为了说明,我们反向跟踪几步:
1 2 3 |
print(loss.grad_fn) # MSELoss print(loss.grad_fn.next_functions[0][0]) # Linear print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU |
输出:
1 2 3 |
|
反向传播
为了反向传播误差,我们所需做的是调用loss.backward().你需要清除已存在的梯度,否则梯度将被累加到已存在的梯度.
现在,我们将调用loss.backward(),并查看conv1层的偏置项在反向传播前后的梯度.
输出(官网的例子)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
conv1.bias.grad before backward Variable containing: 0numpy 0 0 0 0 0 [torch.FloatTensor of size 6] conv1.bias.grad after backward Variable containing: -0.0317 -0.1682 -0.0158 0.2276 -0.0148 -0.0254 [torch.FloatTensor of size 6] |
本人运行输出
1 2 3 4 5 6 7 8 9 10 11 |
conv1.bias.grad before backward None conv1.bias.grad after backward Variable containing: 0.0011 0.1170 -0.0012 -0.0204 -0.0325 -0.0648 [torch.FloatTensor of size 6] |
不同之处在于backward之前不同,官网示例的梯度为0,而实际运行出来却是None.
现在我们已知道如何使用损失函数.
稍后阅读
神经网络包包含了各种用来构成深度神经网络构建块的模块和损失函数,一份完整的文档查看这里
唯一剩下的内容:
- 更新网络的权重
更新权重
实践中最简单的更新规则是随机梯度下降(SGD).
weight=weight−learning_rate∗gradient
我们可以使用简单的Python代码实现这个规则.
1 2 3 |
learning_rate = 0.01 for f in net.parameters(): f.data.sub_(f.grad.data * learning_rate) |
然而,当你使用神经网络是,你想要使用各种不同的更新规则,比如SGD,Nesterov-SGD,Adam, RMSPROP等.为了能做到这一点,我们构建了一个包torch.optim实现了所有的这些规则.使用他们非常简单:
1 2 3 4 5 6 7 8 9 10 11 |
import torch.optim as optim # create your optimizer optimizer = optim.SGD(net.parameters(), lr=0.01) #in your trainning loop: optimizer.zero_grad() # zero the gradient buffers output = net(input) loss = criter(output, target) loss.backward() optimizer.step() # does the update |
脚本总运行时间: 0.367秒
Python源码
Jupyter源码
四、训练一个分类器
你已经看到如何去定义一个神经网络,计算损失值和更新网络的权重.
你现在可能在思考.
关于数据
通常,当你处理图像,文本,音频和视频数据时,你可以使用标准的Python包来加载数据到一个numpy数组中.然后把这个数组转换成torch.*Tensor.
- 对于图像,有诸如Pillow,OpenCV包.
- 对于音频,有诸如scipy和librosa包
- 对于文本,原始Python和Cython来加载,或者NLTK和SpaCy是有用的.
对于视觉,我们创建了一个torchvision包,包含常见数据集的数据加载,比如Imagenet,CIFAR10,MNIST等,和图像转换器,也就是torchvision.datasets和torch.utils.data.DataLoader.
这提供了巨大的便利,也避免了代码的重复.
在这个教程中,我们使用CIFAR10数据集,它有如下10个类别:’airplane’,’automobile’,’bird’,’cat’,’deer’,’dog’,’frog’,’horse’,’ship’,’truck’.这个数据集中的图像大小为3*32*32,即,3通道,32*32像素.

训练一个图像分类器
我们将一次按照下列顺序进行:
- 使用
torchvision加载和归一化CIFAR10训练集和测试集. - 定义一个卷积神经网络
- 定义损失函数
- 在训练集上训练网络
- 在测试机上测试网络
1. 加载和归一化CIFAR0
使用torchvision加载CIFAR10是非常容易的.
1 2 3 |
import torch import torchvision import torchvision.transforms as transforms |
torchvision的输出是[0,1]的PILImage图像,我们把它转换为归一化范围为[-1, 1]的张量.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
|
输出:
1 2 |
Files already downloaded and verified Files already downloaded and verified |
为了好玩,我们展示一些训练图像.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
|
输出:
1 |
truck cat car plane |

2. 定义一个卷积神经网络
从之前的神经网络一节复制神经网络代码,并修改为接受3通道图像取代之前的接受单通道图像.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
|
3. 定义损失函数和优化器
我们使用交叉熵作为损失函数,使用带动量的随机梯度下降.
1 2 3 4 |
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) |
4. 训练网络
这是开始有趣的时刻.我们只需在数据迭代器上循环,听歌数据输入给网络,并优化.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# wrap them in Variable
inputs, labels = Variable(inputs), Variable(labels)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.data[0]
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
|
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[1, 2000] loss: 2.191 [1, 4000] loss: 1.866 [1, 6000] loss: 1.696 [1, 8000] loss: 1.596 [1, 10000] loss: 1.502 [1, 12000] loss: 1.496 [2, 2000] loss: 1.422 [2, 4000] loss: 1.370 [2, 6000] loss: 1.359 [2, 8000] loss: 1.321 [2, 10000] loss: 1.311 [2, 12000] loss: 1.275 Finished Training |
5. 在测试集上测试网络
我们在整个训练集上训练了两次网络,但是我们需要检查网络是否从数据集中学习到东西.
我们通过预测神经网络输出的类别标签并根据实际情况进行检测.如果预测正确,我们把该样本添加到正确预测列表.
第一步,显示测试集中的图片一遍熟悉图片内容.
1 2 3 4 5 6 |
dataiter = iter(testloader)
images, labels = dataiter.next()
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
|

输出:
1 |
GroundTruth: cat ship ship plane |
现在我们来看看神经网络认为以上图片是什么?
1 |
outputs = net(Variable(images)) |
输出是10个标签的能量.一个类别的能量越大,神经网络越认为他是这个类别.所以让我们得到最高能量的标签.
1 2 3 4 |
_, predicted = torch.max(outputs.data, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
|
输出:
1 |
Predicted: cat ship car plane |
这结果看起来非常的好.
接下来让我们看看网络在整个测试集上的结果如何.
1 2 3 4 5 6 7 8 9 10 11 |
correct = 0
total = 0
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
|
输出:
1 |
Accuracy of the network on the 10000 test images: 55 % |
结果看起来好于偶然,偶然的正确率为10%,似乎网络学习到了一些东西.
那在什么类上预测较好,什么类预测结果不好呢.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
|
输出:
1 2 3 4 5 6 7 8 9 10 |
Accuracy of plane : 60 % Accuracy of car : 46 % Accuracy of bird : 44 % Accuracy of cat : 35 % Accuracy of deer : 38 % Accuracy of dog : 43 % Accuracy of frog : 57 % Accuracy of horse : 76 % Accuracy of ship : 71 % Accuracy of truck : 74 % |
接下来干什么?
我们如何在GPU上运行神经网络呢?
在GPU上训练
你是如何把一个Tensor转换GPU上,你就如何把一个神经网络移动到GPU上训练.这个操作会递归遍历有所模块,并将其参数和缓冲区转换为CUDA张量.
1 |
net.cuda() |
请记住,你也必须在每一步中把你的输入和目标值转换到GPU上:
1 |
inputs, labels = Variable(inputs.cuda()), Variable(target.cuda()) |
为什么我们没注意到GPU的速度提升很多?那是因为网络非常的小.
实践:尝试增加你的网络的宽度(第一个nn.Conv2d的第2个参数, 第二个nn.Conv2d的第一个参数,他们需要是相同的数字),看看你得到了什么样的加速.
实现的目标:
- 深入了解了PyTorch的张量库和神经网络.
- 训练了一个小网络来分类图片.
在多GPU上训练
如果你希望使用所有GPU来更大的加快速度,请查看选读:数据并行
接下来做什么?
- 训练神经网络玩电子游戏
- 在ImageNet上训练最好的ResNet
- 使用对抗生成网络来训练一个人脸生成器
- 使用LSTM网络训练一个字符级的语言模型
- 更多示例
- 更多教程
- 在论坛上讨论PyTorch
- 在Slack上与其他用户聊天)
脚本总运行时间:3:24.484
Python源码
Jupyter源码
五、数据并行(选读)
作者:Sung Kim和Jenny Kang
在这个教程里,我们将学习如何使用DataParallel来使用多GPU.
PyTorch非常容易的就可以使用GPU,你可以用如下方式把一个模型防盗GPU上:
1 |
model.gpu() |
然后你可以复制所有的张量到GPU上:
1 |
mytensor = mytensor.gpu() |
请注意,只调用mytensor.gpu()并没有复制张量到GPU上。你需要把它赋值给一个新的张量并在GPU上使用这个张量。
在多GPU上执行前向和反向传播是自然而然的事。然而,PyTorch默认将只是用一个GPU。你可以使用DataParallel让模型并行运行来轻易的让你的操作在多个GPU上运行。
1 |
model = nn.DataParallel(model) |
这是这篇教程背后的核心,我们接下来将更详细的介绍它。
导入和参数
导入PyTorch模块和定义参数。
1 2 3 4 5 6 7 8 9 10 11 |
import torch import torch.nn as nn from torch.autograd import Variable from torch.utils.data import Dataset, DataLoader # Parameters and DataLoaders input_size = 5 output_size = 2 batch_size = 30 data_size = 100 |
虚拟数据集
制作一个虚拟(随机)数据集,你只需实现__getitem__.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, 100),
batch_size=batch_size, shuffle=True)
|
简单模型
作为演示,我们的模型只接受一个输入,执行一个线性操作,然后得到结果。然而,你能在任何模型(CNN,RNN,Capsule Net等)上使用DataParallel。
我们在模型内部放置了一条打印语句来检测输入和输出向量的大小。请注意批等级为0时打印的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 |
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print(" In Model: input size", input.size(),
"output size", output.size())
return output
|
创建一个模型和数据并行
这是本教程的核心部分。首先,我们需要创建一个模型实例和检测我们是否有多个GPU。如果我们有多个GPU,我们使用nn.DataParallel来包装我们的模型。然后通过model.gpu()(看代码实际是model.cuda())把模型放到GPU上。
运行模型
现在我们可以看输入和输出张量的大小。
1 2 3 4 5 6 7 8 9 |
for data in rand_loader:
if torch.cuda.is_available():
input_var = Variable(data.cuda())
else:
input_var = Variable(data)
output = model(input_var)
print("Outside: input size", input_var.size(),
"output_size", output.size())
|
输出:
1 2 3 4 5 6 7 8 |
In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2]) |
结果
当我们对30个输入和输出进行批处理时,我们和期望的一样得到30个输入和输出,但是如果你有多个GPU,你得到如下的结果。
2个GPU
如果你有2个GPU,你将看到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# on 2 GPUs
Let's use 2 GPUs!
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
|
3个GPU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Let's use 3 GPUs!
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
|
8个GPU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
Let's use 8 GPUs!
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
|
总结
DataParallel自动的划分数据,并将作业发送到多个GPU上的多个模型。在每个模型完成作业后,DataParallel收集并合并结果返回给你。
更多信息请看这里:
http://pytorch.org/tutorials/beginner/former_torchies/parallelism_tutorial.html
脚本总运行时间:0.0003秒
Python源码
Jupyter源码