python2x的str/unicode转换以及python3x中的str/bytes转换
写在开头
为什么哪里都会出现编码问题,而编码问题总是那么难搞懂?我想在读这篇博客前大家都应该深刻地了解下为什么会出现所谓的编码问题?
Python2x中的str/unicode转换
字符的十六进制表达
首先,我们在ULtraEdit中做个试验
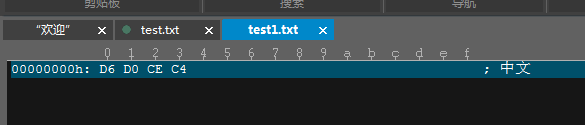

图一:我们先用记事本保存了“中文”二字,然后以ANSI编码格式保存后用ULtraEdit打开,再转成十六进制编辑环境后就可以看到“中文”二字用ANSI编码存储的十六进制的表达,可以看到是4个字节。
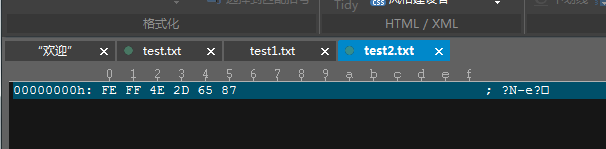
图二:是用Unicode BigEndian保存的”中文“二字的十六进制表达,即从”4E“到”87“对应的4个字节,前面的两个字节是头,不管他,有兴趣的读者可以自行度娘。
图三:是用UTF-8编码存储的”中文“二字的十六进制表达,即从“E4“到”87“这6个字节,前三个字节是头,不管他。
可以看到,用不同的编码保存同样的字符,底层就会有不同的十六进制表达,ANSI底层是用两个字节存储一个中文字符的,Unicode也是用两个字节存储一个中文字符的,而UTF-8编码是用三个字节存储一个中文字符的。
Python2x中Str&Unicode
接下来我们来讨论Python2x中的Str和Unicode。
首先我打开Python2.7的编译环境。输入以下代码:
>>>a="中文"
>>>a
'\xd6\xd0\xce\xc4'
>>>type(a)
'str'>
>>>b=a.decode('gbk')
>>>b
u'\u4e2d\u6587'
>>>type(b)
'unicode'>
>>>a.decode('ascii')
可以看到在Python2.7shell中,我们输入”中文“这两个中文字符时,用了解释器的默认编码格式,在windows下即为GBK,所以我们看到的是上面第一个图中的十六进制表达。可以看到此时a的类型是str。
当我们对str类型的a用”gbk“解码后赋给变量b,可以b的类型是unicode,十六进制的表达式类似上面第二个图。
但是我们用ASCII编码去解码却得到DecodeError的结果。
所以我们得到一个结论:[str].decode(str对应的编码)=[unicode],并且用什么码编码就用什么码解码。
>>>c=b.encode('utf8')
>>>c
'\xe4\xb8\xad\xe6\x96\x87'
>>>type(c)
<type 'str'>
>>>print c
涓?枃我们可以看到对unicode类型的变量b用utf8编码后变成了str类型的c,它的底层十六进制表达如上面的第三张图。unicode转换成utf8的规则可以参看这个网址上的博客:传送门
当我们print c的时候就打印出来乱码了,原因是此时的str变量c用的是utf8编码,但是解释器的编码是gbk,相当于用gbk的编码方式去解释用utf8编码的字符串,自然打印出来的是乱码。(而且,上面说过gbk是两个字节表示一个中文字符,utf8是三个字节表示一个中文字符,所以打印出来是三个乱码的字符)
所以我们得到另一个结论:[unicode].encode(你想要的编码方式)=[str],解释器编码方式要与字符串的编码方式一样才能解出正确的字符。
好了,说到这读者应该知道了Python里的str和unicode转换是怎么回事,以及底层那串”0101“的数字发生了什么变化。再说一句,Python2x中可以直接对str调用encode函数进行编码,我们可以这么理解他的背后实际做法:(str).decode(默认的编码).encode(你想要的编码)。那有读者要疑惑了,unicode decode是什么呢,Python2x中我试了下还是原unicode,我猜是Python不希望它出错,故意那这个接口留着,却不作为。
Python3x中的str/bytes转换
好吧,有些读者可能刚理解了上面说的Python2x中的unicode和str是怎么回事,不就是str解个码变成unicode,然后unicode编个码变成你想要的编码编的str嘛,简单!
然而到了Python3x后发现,咦,str不能解码了,str对象压根没有decode属性了,这还怎么入手?
首先我们要知道,在Python3x中不在有unicode这一说了,只有str和bytes这两个概念了(其实是Python把unicode隐藏了)。来看下面的代码
a = '中'
a.decode('utf8') #AttributeError: 'str' object has no attribute 'decode'
print(type(a)) #<class 'str'>
print(a.encode('utf8')) #b'\xe4\xb8\xad'
print(type(a.encode('utf8'))) #<class 'bytes'>
b = bytes(a,"utf8")
print (b) #b'\xe4\xb8\xad'
print(type(b)) #<class 'bytes'>
print(b.decode('utf8')) #中
print(type(b.decode('utf8'))) #<class 'str'>我们可以看到:
Python3x中(str).encode(编码)=(bytes)
(bytes).decode(‘bytes对应的编码’)=(str)
str不能上来就解码了
这是为什么呢?其实我们可以把unicode概念加上,帮助你理解,这里的str其实是unicode类型的字符串,你可以把它看成Python2x中的unicode,而bytes只不过带有指定编码的字节序列,可以看成Python2x中的str。这下你再看,是不是str(unicode)编码变bytes(str),bytes(str)解码变str(unicode)。可以这么想,我们输入的字符串直接被Python3x处理成Unicode形式的字符串,那么你可以干嘛,只能编码后才会变成字节序列啊。
说了这些可能你会觉得有点晕,那么来看下面的对比:


图一是Python3.4环境下的shell,图二是Python2.7环境下的shell,要读取的文本是以UTF-8的编码格式保存的,还是”中文“二字,我们可以想象,底层的字节序列应该是”\xe4\xb8\xad\xe6\x96\x87“。
可以看到Python2.7可以读取,并且底层的字节序列是怎么保存的他就怎么读取。但是Python3.4呢,他报错了,是decode错误,很显然,他在读取的时候想把UTF-8编码的字节序列用GBK去解码,想把它变成unicode,自然就出现了错误。我试了用ASNI编码保存的话,他就会正常读取,而且type是str。
所以我说实际上Python3x一旦读取了文本中的字符串,事实上它已经替你解码成unicode了,但是告诉你这是str类型。
总结
我们来总结一下,Python2x中,保存了什么字节序列,他就原封不动的读取进来,然后告诉你这是str类型(底层是字节序列),那么你可以把它decode一下,变成可以跨平台使用的unicode。好了,你要输出到文件中去了,那你得以一个具体的规则输出,也就是把unicode encode一下又变str(字节序列)。
Python3x中,文本中保存了字节序列,读取的时候Python解释器用设定的默认编码去解码了一道,变成了unicode,所以你不需要操作了,但是它告诉你这是str,你就当不知道,反正不管怎么夸平台都不会出错了。到了要输出的时候,再把unicode encode成bytes(字节序列)。