Netty学习笔记(2)
Buffers(缓冲)
写入数据到ByteBuf后,写入索引是增加的字节数量。开始读字节后,读取索引增加。你可以读取字节,直到写入索引和读取索引处理相同的位置,次数若继续读取,则会抛出IndexOutOfBoundsException。调用ByteBuf的任何方法开始读/写都会单独维护读索引和写索引。ByteBuf的默认最大容量限制是Integer.MAX_VALUE,写入时若超出这个值将会导致一个异常。
1. ByteBuf directBuf = Unpooled.directBuffer(16);
2. if(!directBuf.hasArray()){
3. int len = directBuf.readableBytes();
4. byte[] arr = new byte[len];
5. directBuf.getBytes(0, arr);
6. }
访问直接缓冲区的数据数组需要更多的编码和更复杂的操作,建议若需要在数组访问数据使用堆缓冲区会更好。
Composite Buffer(复合缓冲区)
复合缓冲区,我们可以创建多个不同的ByteBuf,然后提供一个这些ByteBuf组合的视图。复合缓冲区就像一个列表,我们可以动态的添加和删除其中的ByteBuf,JDK的ByteBuffer没有这样的功能。
ByteBuf的字节操作
ByteBuf提供了许多操作,允许修改其中的数据内容或只是读取数据。ByteBuf和JDK的ByteBuffer很像,但是ByteBuf提供了更好的性能。
随机访问索引
ByteBuf使用zero-based-indexing(从0开始的索引),第一个字节的索引是0,最后一个字节的索引是ByteBuf的capacity - 1,下面代码是遍历ByteBuf的所有字节:
ByteBuf使用zero-based-indexing(从0开始的索引),第一个字节的索引是0,最后一个字节的索引是ByteBuf的capacity - 1,下面代码是遍历ByteBuf的所有字节:
1. //create a ByteBuf of capacity is 16
2. ByteBuf buf = Unpooled.buffer(16);
3. //write data to buf
4. for(int i=0;i<16;i++){
5. buf.writeByte(i+1);
6. }
7. //read data from buf
8. for(int i=0;i顺序访问索引
ByteBuf提供两个指针变量支付读和写操作,读操作是使用readerIndex(),写操作时使用writerIndex()。这和JDK的ByteBuffer不同,ByteBuffer只有一个方法来设置索引,所以需要使用flip()方法来切换读和写模式。
ByteBuf一定符合:0 <= readerIndex <= writerIndex <= capacity。
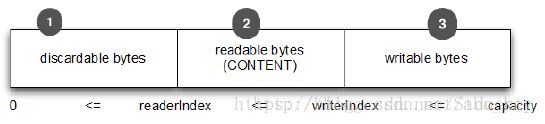
Discardablebytes废弃字节
我们可以调用ByteBuf.discardReadBytes()来回收已经读取过的字节,discardReadBytes()将丢弃从索引0到readerIndex之间的字节。调用discardReadBytes()方法后会变成如下图:

ByteBuf.discardReadBytes()可以用来清空ByteBuf中已读取的数据,从而使ByteBuf有多余的空间容纳新的数据,但是discardReadBytes()可能会涉及内存复制,因为它需要移动ByteBuf中可读的字节到开始位置,这样的操作会影响性能,一般在需要马上释放内存的时候使用收益会比较大。
可读字节(实际内容)
任何读操作会增加readerIndex,如果读取操作的参数也是一个ByteBuf而没有指定目的索引,指定的目的缓冲区的writerIndex会一起增加,没有足够的内容时会抛出IndexOutOfBoundException。新分配、包装、复制的缓冲区的readerIndex的默认值都是0。下面代码显示了获取所有可读数据:
1. ByteBuf buf = Unpooled.buffer(16);
2. while(buf.isReadable()){
3. System.out.println(buf.readByte());
4. }
可写字节Writable bytes
任何写的操作会增加writerIndex。若写操作的参数也是一个ByteBuf并且没有指定数据源索引,那么指定缓冲区的readerIndex也会一起增加。若没有足够的可写字节会抛出IndexOutOfBoundException。新分配的缓冲区writerIndex的默认值是0。下面代码显示了随机一个int数字来填充缓冲区,直到缓冲区空间耗尽:
1. Random random = new Random();
2. ByteBuf buf = Unpooled.buffer(16);
3. while(buf.writableBytes() >= 4){
4. buf.writeInt(random.nextInt());
5. } 清除缓冲区索引Clearing the buffer indexs
调用ByteBuf.clear()可以设置readerIndex和writerIndex为0,clear()不会清除缓冲区的内容,只是将两个索引值设置为0。请注意ByteBuf.clear()与JDK的ByteBuffer.clear()的语义不同。
下图显示了ByteBuf调用clear()之前:

下图显示了调用clear()之后:
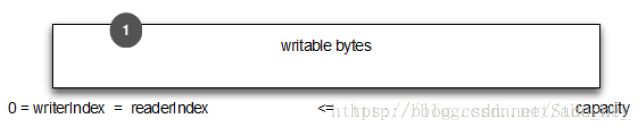
和discardReadBytes()相比,clear()是便宜的,因为clear()不会复制任何内存。
标准和重置Mark and reset
每个ByteBuf有两个标注索引,一个存储readerIndex,一个存储writerIndex。你可以通过调用一个重置方法重新定位两个索引之一,它类似于InputStream的标注和重置方法,没有读限制。我们可以通过调用readerIndex(int readerIndex)和writerIndex(intwriterIndex)移动读索引和写索引到指定位置,调用这两个方法设置指定索引位置时可能抛出IndexOutOfBoundException。
怎么获得ByteBuf
ByteBufAllocator对象
获取ByteBufAllocator对象很容易,可以从Channel的alloc()获取,也可以从ChannelHandlerContext的alloc()获取
ByteBufAllocator.heapBuffer()
ByteBufAllocator.directBuffer()
ByteBufAllocator.compositeBuffer()
Unpooled
Unpooled 也是用来创建缓冲区的工具类, Unpooled 的使用也很容易1. //创建复合缓冲区
2. CompositeByteBuf compBuf = Unpooled.compositeBuffer();
3. //创建堆缓冲区
4. ByteBuf heapBuf = Unpooled.buffer(8);
5. //创建直接缓冲区
ByteBuf directBuf = Unpooled.directBuffer(16);
ChannelHandler
ChannelPipeline
ChannelPipeline是ChannelHandler实例的列表,用于处理或截获通道的接收和发送数据。ChannelPipeline提供了一种高级的截取过滤器模式,让用户可以在ChannelPipeline中完全控制一个事件及如何处理ChannelHandler与ChannelPipeline的交互。
对于每个新的通道,会创建一个新的ChannelPipeline并附加至通道。一旦连接,Channel和ChannelPipeline之间的耦合是永久性的。Channel不能附加其他的ChannelPipeline或从ChannelPipeline分离。
下图描述了 ChannelHandler 在 ChannelPipeline 中的 I/O 处理,一个 I/O 操作可以由一个 ChannelInboundHandler 或 ChannelOutboundHandler 进行处理,并通过调用 ChannelInboundHandler 处理入站 IO 或通过 ChannelOutboundHandler 处理出站 IO 。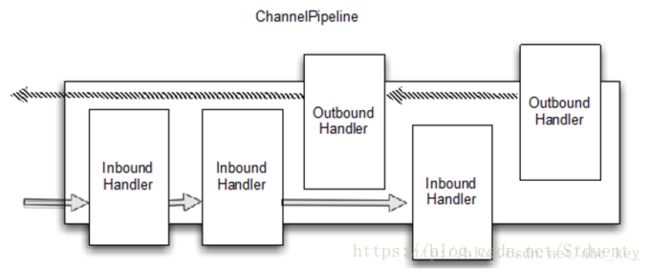
如上图所示,ChannelPipeline是ChannelHandler的一个列表;如果一个入站I/O事件被触发,这个事件会从第一个开始依次通过ChannelPipeline中的ChannelHandler;若是一个入站I/O事件,则会从最后一个开始依次通过ChannelPipeline中的ChannelHandler。ChannelHandler可以处理事件并检查类型,如果某个ChannelHandler不能处理则会跳过,并将事件传递到下一个ChannelHandler。ChannelPipeline可以动态添加、删除、替换其中的ChannelHandler,这样的机制可以提高灵活性。
修改ChannelPipeline的方法:
- addFirst(...),添加ChannelHandler在ChannelPipeline的第一个位置
- addBefore(...),在ChannelPipeline中指定的ChannelHandler名称之前添加ChannelHandler
- addAfter(...),在ChannelPipeline中指定的ChannelHandler名称之后添加ChannelHandler
- addLast(ChannelHandler...),在ChannelPipeline的末尾添加ChannelHandler
- remove(...),删除ChannelPipeline中指定的ChannelHandler
- replace(...),替换ChannelPipeline中指定的ChannelHandler
1. ChannelPipeline pipeline = ch.pipeline();
2. FirstHandler firstHandler = new FirstHandler();
3. pipeline.addLast("handler1", firstHandler);
4. pipeline.addFirst("handler2", new SecondHandler());
5. pipeline.addLast("handler3", new ThirdHandler());
6. pipeline.remove("“handler3“");
7. pipeline.remove(firstHandler);
8. pipeline.replace("handler2", "handler4", new FourthHandler());
状态模型
Netty有一个简单但强大的状态模型,并完美映射到ChannelInboundHandler的各个方法。下面是Channel生命周期四个不同的状态:
- channelUnregistered
- channelRegistered
- channelActive
- channelInactive
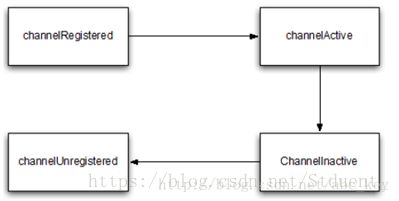
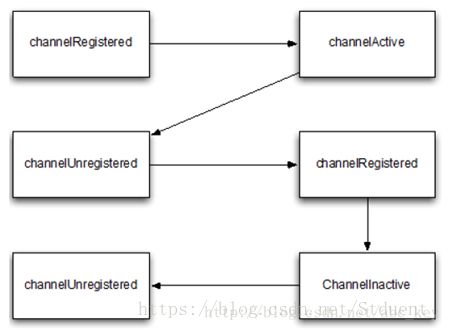
还可以看到额外的状态变化,因为用户允许从EventLoop中注销Channel暂停事件执行,然后再重新注册。在这种情况下,你会看到多个channelRegistered和channelUnregistered状态的变化,而永远只有一个channelActive和channelInactive的状态,因为一个通道在其生命周期内只能连接一次,之后就会被回收;重新连接,则是创建一个新的通道。
下图显示了从EventLoop中注销Channel后再重新注册的状态变化:
ChannelHandler和其子类
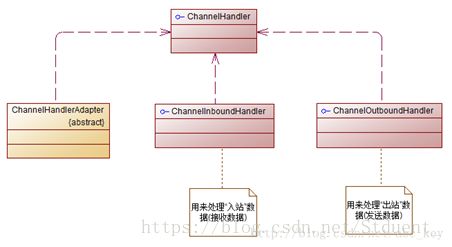
ChannelInboundHandler
ChannelInboundHandler提供了一些方法再接收数据或Channel状态改变时被调用。下面是ChannelInboundHandler的一些方法:
- channelRegistered,ChannelHandlerContext的Channel被注册到EventLoop;
- channelUnregistered,ChannelHandlerContext的Channel从EventLoop中注销
- channelActive,ChannelHandlerContext的Channel已激活
- channelInactive,ChannelHanderContxt的Channel结束生命周期
- channelRead,从当前Channel的对端读取消息
- channelReadComplete,消息读取完成后执行
- userEventTriggered,一个用户事件被处罚
- channelWritabilityChanged,改变通道的可写状态,可以使用Channel.isWritable()检查
- exceptionCaught,重写父类ChannelHandler的方法,处理异常
Netty提供了一个实现了ChannelInboundHandler接口并继承ChannelHandlerAdapter的类:ChannelInboundHandlerAdapter。ChannelInboundHandlerAdapter实现了ChannelInboundHandler的所有方法,作用就是处理消息并将消息转发到ChannelPipeline中的下一个ChannelHandler。ChannelInboundHandlerAdapter的channelRead方法处理完消息后不会自动释放消息。
ChannelOutboundHandler
ChannelOutboundHandler用来处理“出站”的数据消息。ChannelOutboundHandler提供了下面一些方法:
- bind,Channel绑定本地地址
- connect,Channel连接操作
- disconnect,Channel断开连接
- close,关闭Channel
- deregister,注销Channel
- read,读取消息,实际是截获ChannelHandlerContext.read()
- write,写操作,实际是通过ChannelPipeline写消息,Channel.flush()属性到实际通道
- flush,刷新消息到通道
Netty提供了ChannelOutboundHandler的实现:ChannelOutboundHandlerAdapter。ChannelOutboundHandlerAdapter实现了父类的所有方法,并且可以根据需要重写感兴趣的方法。所有这些方法的实现,在默认情况下,都是通过调用ChannelHandlerContext的方法将事件转发到ChannelPipeline中下一个ChannelHandler。调用writeAndFlush会自动释放消息。