Hadoop 2.5.1 虚拟集群搭建——Hadoop基本配置
上一篇博文 http://blog.csdn.net/stormragewang/article/details/41116213中介绍了虚拟机集群的基本环境的安装,当各个虚拟机设置好共享文件夹,安装好JAVA并且master结点可以通过ssh了解到slave1和slave2结点,这时候我们就可以进行Hadoop的安装工作了。
还是先把集群的规划贴出来
| 主机名 | 别名 | OS | IP | HDFS角色 | Yarn角色 |
| Yarn-Matser | master | CentOS_6.5_i686 minimal desktop | 192.168.137.100 | namenode,datanode | resourcemanager,nodemanager |
| Yarn-Slave_1 | slave1 | CentOS_6.5_i686 minimal | 192.168.137.101 | datanode | nodemanager |
| Yarn-Slave_2 | slave2 | CentOS_6.5_i686 minimal | 192.168.137.102 | datanode | nodemanager |
首先去 http://hadoop.apache.org/releases.html#Download下载一个版本,我用的是2.5.1版本,放到共享文件夹中待用。
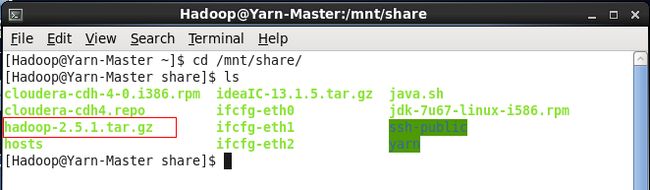
对于3个节点都进行以下操作:在Hadoop用户的用户目录下新建了个文件夹命名为Hadoop,并在下面新建3个文件夹:2.5.1、dfs、tmp,并在tmp下新建2个文件夹data、name。同时将下载的压缩文件解析到文件夹2.5.1中
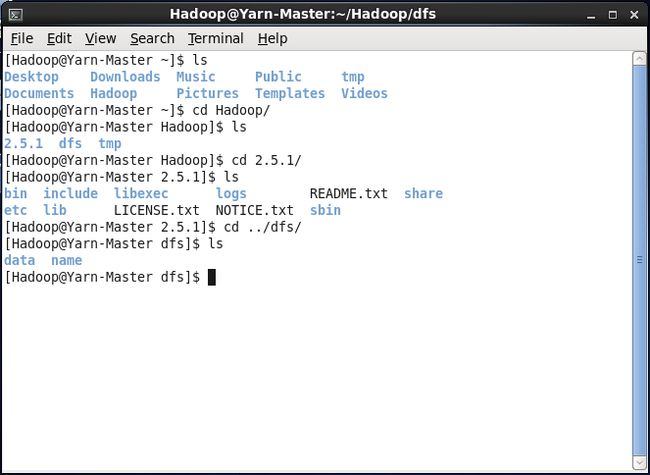
hadoop的配置文件都在etc/hadoop文件下
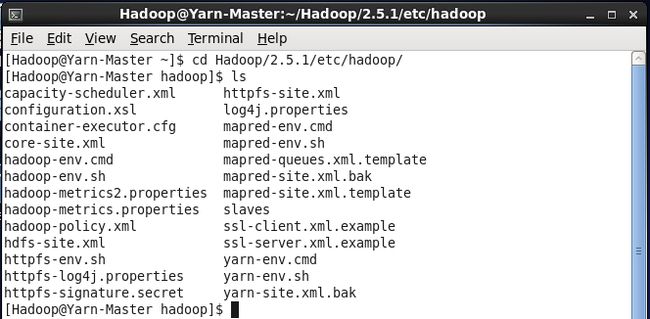
其中有2个*.bak文件是我自己创建的,对于基本配置有4个文件要注意:core-site.xml、 hdfs-site.xml、 mapred-site.xml、 yarn-site.xml、 slaves 这5个文件,详细的信息可以参考官方文档 http://hadoop.apache.org/docs/r2.5.1/hadoop-project-dist/hadoop-common/ClusterSetup.html
先配置master节点,只需要配置core-site.xml、 hdfs-site.xml、 slaves 这3个文件
core-site.xml 文件如下
fs.defaultFS
hdfs://master
hadoop.tmp.dir
file:/home/Hadoop/tmp
A base for other temporary directories.
dfs.datanode.data.dir
file:/home/Hadoop/Hadoop/dfs/data
Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks.
dfs.namenode.name.dir
file:/home/Hadoop/Hadoop/dfs/name
Path on the local filesystem where the NameNode stores the namespace and transaction logs persistently.
dfs.replication
2
master
slave1
slave2然后配置slave1和slave2节点,只需要配置core-site.xml、 hdfs-site.xml、 yarn-site.xml这3个文件
core-site.xml文件如下
fs.defaultFS
hdfs://master
hadoop.tmp.dir
file:/home/Hadoop/tmp
A base for other temporary directories.
dfs.datanode.data.dir
file:/home/Hadoop/Hadoop/dfs/data
Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks.
dfs.replication
2
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
然后配置hadoop环境参数,对于3个节点都进行以下操作:
先编辑.bash_profile如下:
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin
export PATH
# make all configuration files in $HOME/.env_vars works
for i in $HOME/.env_vars/*.sh ; do
if [ -r "$i" ]; then
. "$i"
fi
done
# setup environment variables of hadoop_2.5.1
#
export HADOOP_PREFIX=$HOME/Hadoop/2.5.1
export HADOOP_HOME=$HADOOP_PREFIX
export HADOOP_COMMON_HOME=$HADOOP_PREFIX
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_PREFIX
export HADOOP_MAPRED_HOME=$HADOOP_PREFIX
export HADOOP_YARN_HOME=$HADOOP_PREFIX
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
首先在master节点关闭防火墙
[Hadoop@Yarn-Master ~]$ su
Password:
[root@Yarn-Master Hadoop]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@Yarn-Master Hadoop]#
然后在$HADOOP_HOME/sbin目录下依次启动HDFS和YARN,先启动dfs
[Hadoop@Yarn-Master ~]$ cd Hadoop/2.5.1/sbin/
[Hadoop@Yarn-Master sbin]$ ls
distribute-exclude.sh start-all.cmd stop-all.sh
hadoop-daemon.sh start-all.sh stop-balancer.sh
hadoop-daemons.sh start-balancer.sh stop-dfs.cmd
hdfs-config.cmd start-dfs.cmd stop-dfs.sh
hdfs-config.sh start-dfs.sh stop-secure-dns.sh
httpfs.sh start-secure-dns.sh stop-yarn.cmd
mr-jobhistory-daemon.sh start-yarn.cmd stop-yarn.sh
refresh-namenodes.sh start-yarn.sh yarn-daemon.sh
slaves.sh stop-all.cmd yarn-daemons.sh
[Hadoop@Yarn-Master sbin]$ ./start-dfs.sh
14/11/15 20:41:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [master]
master: starting namenode, logging to /home/Hadoop/Hadoop/2.5.1/logs/hadoop-Hadoop-namenode-Yarn-Master.out
slave2: starting datanode, logging to /home/Hadoop/Hadoop/2.5.1/logs/hadoop-Hadoop-datanode-Yarn-Slave_2.out
slave1: starting datanode, logging to /home/Hadoop/Hadoop/2.5.1/logs/hadoop-Hadoop-datanode-Yarn-Slave_1.out
master: starting datanode, logging to /home/Hadoop/Hadoop/2.5.1/logs/hadoop-Hadoop-datanode-Yarn-Master.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/Hadoop/Hadoop/2.5.1/logs/hadoop-Hadoop-secondarynamenode-Yarn-Master.out
14/11/15 20:42:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[Hadoop@Yarn-Master sbin]$
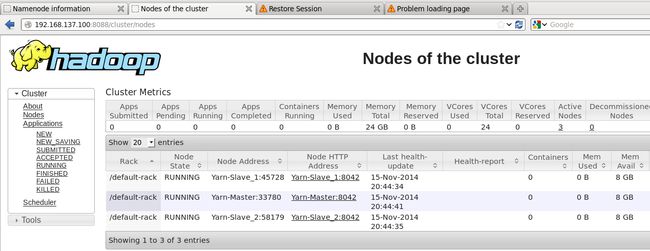
可以在浏览器中查看结点状态
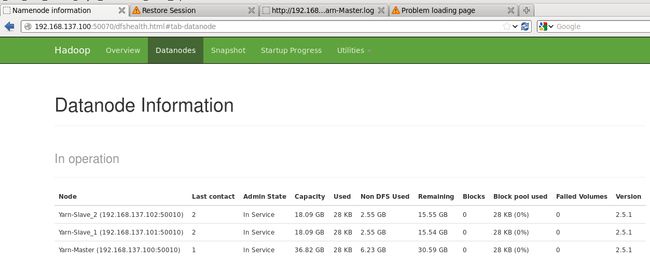
再启动YARN
[Hadoop@Yarn-Master sbin]$ ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/Hadoop/Hadoop/2.5.1/logs/yarn-Hadoop-resourcemanager-Yarn-Master.out
slave2: starting nodemanager, logging to /home/Hadoop/Hadoop/2.5.1/logs/yarn-Hadoop-nodemanager-Yarn-Slave_2.out
slave1: starting nodemanager, logging to /home/Hadoop/Hadoop/2.5.1/logs/yarn-Hadoop-nodemanager-Yarn-Slave_1.out
master: starting nodemanager, logging to /home/Hadoop/Hadoop/2.5.1/logs/yarn-Hadoop-nodemanager-Yarn-Master.out
[Hadoop@Yarn-Master sbin]$
这样整个集群就启动了!
如果启动过程中有问题,在$HADOOP_HOME/log中有日志文件,根据具体出现问题去google就基本上都可以解决,后续的工作就是优化参数和跑跑程序了。