数据库之存储
无论是什么数据库,其本质还是以数据的形式存储在计算机的物理介质上的,所以,我们先来看看什么是物理存储介质。
物理存储介质:高速缓冲存储器->主存储器->快闪存储器->磁盘->光盘->磁带,从左到右性能由高到低,价格也由高到低。
1.磁盘性能的度量:容量,访问时间,数据传输率和可靠性
平均寻道时间:磁盘臂移动到正确的磁道花费的时间的平均值
平均等待时间:磁盘等待旋转到指定的扇区需要的平均时间,一般是旋转一圈花费时间的一半
访问时间=平均寻道时间+平均旋转等待时间
数据传输率:数据写入磁盘或者从磁盘中读取的速率。目前磁盘系统支持25~100MB的数据最大传输率
平均故障时间(可靠性)
2.磁盘块访问的优化
2.1缓冲:从磁盘读取的块暂时存储在内存缓冲区中,因为从缓冲中读取数据需要的时间成本比一次磁盘读写小了几个量级,基本上可以忽略不计。
2.2磁盘预读:当一个磁盘块被访问时,相同磁道的连续块也会被读入到内存缓冲区,即对还未被访问的磁盘块预先读取到缓冲区中,为什么会设计磁盘预读?这样做能够有什么好处?
在实际的磁盘使用中,人们总结出一个规律:当一个磁盘块被访问时,下一次访问操作有80%的概率会读取上一个磁盘块周围的磁盘块(顺序读取的概率是远远大于随机读取的),针对这种规律,便设计出了磁盘预读这种操作。需要注意的四,对于随机块的访问,预读的效率并不好。
2.3调度:优化磁盘性能度量的指标中的访问时间的影响因素之寻道时间
如果说当前需要访问的道的次序分别是:1 5 8 9 12 15,上一次访问的磁道是10号磁道,那么接下来该怎么调度能够在最少的时间内确保都能读取的情况?
最短寻道优先磁盘调度算法:每次都读取离当前磁道最近的磁道。这种算法思想下的确能够优化整体上的寻道时间,但是该算法的特性导致离当前磁道越远的磁盘读取需要的时间越远,这使得磁盘访问出现两极化(旱的旱死,涝的涝死)。
先来先服务:先请求的磁盘先访问,这种情况下能够确保很好的公平性,但是磁盘的访问时间很难优化。
电梯调度算法:确定一个方向,每次都从该方向上找到最近的磁道,就像电梯一样,每次都是朝着一个方向移动,电梯调度算法协调了效率和公平性这两个相互冲突的目标。
2.4文件组织:为了减少块访问时间,我们可以按照与预期的数据访问方式最接近的方式来组织磁盘上的块。例如,我们预计一个文件将顺序访问,那么在理想情况下我们应该使文件的所有块存储在连续的相邻柱面上。
2.5非易失性写缓冲区:因为主存储器中的内容在发生电源故障时将全部丢失,所以关于数据库更新的信息必须记录到磁盘上,这样才能在系统崩溃时得以保存。因此,更新操作密集的数据库应用的性能,如事务处理系统的性能,高度依赖于磁盘写操作的速度,这也是问什么Mysql会使用B+树结构存储的原因(后面会有专门的文章进行介绍)。实际上可以通过飞翼式新随机访问存储区大幅度家属写磁盘的操作。
2.6日志磁盘:减少写等待时间另一种方法就是使用日志磁盘,即一种专门用于写顺序日志的磁盘,这和非易失性RAM缓冲区的使用非常相似。对日志磁盘的所有访问都是顺序的,这从根本上消除了寻道时间,并且一次可以写连续几个的块,使得写日志磁盘比随机的写要快许多倍。
在数据库系统中,不需要等待写操作的完成,日志磁盘会在之后完成写操作(操作延时),进一步说,日志磁盘可以为了最少化磁盘臂的移动而重排写操作的顺序(就是先收集一些写操作,然后最这些写操作进行重新排序,使得写入性能提高)。支持这种日志磁盘的文件系统统称为日志文件系统。
3.独立磁盘冗余阵列RAID
如果一个系统中使用大量的磁盘为提高数据读写速率提供了机会,如果并行访问磁盘的话,很多独立的读和写操作可以并发执行。此外,这种组织方式提供了提高数据存储可靠性的潜力,因为可以在多张磁盘中存储冗余信息,因此一个磁盘的故障不会导致数据的丢失。这种为了提高性能和可靠性而允许冗余的技术就是独立磁盘冗余阵列RAID。
通过冗余提高可靠性:首先从可靠性方面切入,N张磁盘集合中的某张磁盘发生故障的概率比特定的一张磁盘发生故障的概率要高。假设一张磁盘发生故障的平均时间是100小时,那么由100张磁盘组成的阵列发生磁盘故障的平均时间是1小时。引入冗余是解决这个可靠性问题的解决方法,实现冗余最简单的方法就是镜像:复制一张磁盘,这样的话,一张逻辑磁盘对应两张物理磁盘,并且每一次写操作都要在两张磁盘上执行。两个磁盘同时故障的情况下才会导致数据丢失,忽略故障磁盘的恢复的话,发生磁盘故障的平均时间是100*100/2=5000小时,但实际上故障的发生的独立性并不是那么高的。
3.1.通过并行提高性能
通过磁盘镜像,处理读请求的速度将翻倍,因为读请求可以发送到任意一张磁盘上(只要组成一对的两张磁盘都有用),每个读操作的操作速率和单一磁盘系统中的传输速率是一样的,但是每单位时间内读操作的数目将翻倍。
我们可以通过在多张磁盘上进行数据拆分来提高传输速率。数据拆分最简单的形式是将每个字节按比特分开,存储到多个磁盘上。这种拆分成为比特级拆分:例如,有8个磁盘的阵列中,将每一字节的第i位存储到第i个磁盘中,这8张磁盘组成的阵列可以看做一个逻辑上的单独的磁盘,这张逻辑磁盘的扇区大小将是一般扇区的8倍。
除了比特级拆分,还有块级拆分,块级拆分是将块拆分到多张磁盘中,把磁盘阵列看做一个单独的大磁盘。块级拆分是最常用的数据拆分形式。
磁盘系统中的并行有两个主要的目的:
1.负载平衡多个小的访问操作(块访问),以提高这种访问操作的吞吐量。
2.并行执行大的访问操作,以减少大访问操作的响应时间。
数据拆分提供高传输率,但不确保可靠性;镜像提供了高可靠性,但他十分昂贵(重复的写操作的代价)
3.2RAID级别:
通过结合“奇偶校验位”和磁盘拆分思想,从而以较低的代价提供数据冗余,人们提出不同的方案,这些方案具有不同的成本和性能之间的权衡,并且分为若干RAID级别。
RAID0级:指块级拆分但没有任何冗余的磁盘阵列。
RAID1级:指的是使用块级拆分的磁盘镜像(每张磁盘都有镜像)
RAID2级:内存风格的纠错码组织结构,使用奇偶检验位(汉明码校验)。
以汉明码(Hamming Code)的方式将数据进行编码后分区为独立的比特,并将数据分别写入硬盘中。因为在数据 中加入了错误修正码(ECC,Error Correction Code),所以数据整体的容量会比原始数据大一些,RAID2最少要三台磁 盘驱动器方能运作。实际中并不使用此级别。 
RAID3级:位交叉的奇偶检验组织结构。数据内的比特分散在不同的硬盘上,每张磁盘都要参与I每个I/O请求,每秒钟支 持的I/O操作数较少,所以这种规格比较适于读取大量数据时使用。如果一个扇区被破坏,系统能准确地知道是哪个扇区 坏了,并且对扇区中的每一位,系统可以通过计算其他磁盘上的对应扇区的对应位的奇偶值来推断出该位是1还是0。
如果 其余位的奇偶校验位等于存储的奇偶校验位,则丢失的位是0,反之为1。

RAID4级:块交叉的奇偶校验组织结构。RAID4使用块交叉的奇偶校验组织结构,而RAID3是位交叉奇偶校验组织结构。它像RAID0一样使用块级拆分,此外在一张独立的磁盘上为其他N张磁盘上对应的块保留一个奇偶校验块。它读取一个块只访问一张磁盘,因此允许其他的请求在其他磁盘上执行,有较高的总I/O传输率。
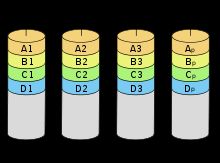
RAID5级:块交叉的分步奇偶检验位的组织结构。RAID5在RAID4的基础上进行了改进,将数据和奇偶校验位都分布到所有的N+1张磁盘中,而不是在N张磁盘上存储数据并在一张磁盘上存储奇偶校验位。实际中一般用RAID5而不用RAID4。
RAID6级:P+Q冗余方案。与RAID 5相比,RAID 6增加了第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。但RAID 6需要分配给奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。较差的性能和复杂的实作方式使得RAID 6很少得到实际应用。
RAID1+0:RAID 1+0是先镜像再拆分数据,再将所有硬盘分为两组,视为是RAID 0的最低组合,然后将这两组各自视为RAID 1运作。

RAID0+1:RAID 0+1则是跟RAID 1+0的程序相反,是先分区再将数据镜射到两组硬盘。它将所有的硬盘分为两组,变成RAID 1的最低组合,而将两组硬盘各自视为RAID 0运作。

性能上,RAID 0+1比RAID 1+0有着更快的读写速度。
可靠性上,当RAID 1+0有一个硬盘受损,其余三个硬盘会继续运作。RAID 0+1 只要有一个硬盘受损,同组RAID 0的另一只硬盘亦会停止运作,只剩下两个硬盘运作,可靠性较低。
3.3RAID级别的选择:
应当考虑的因素:
1.所需的额外磁盘存储带来的花费
2.在I/O操作数量方面的性能需求
3.磁盘故障时的性能
4.数据重建过程
RAID0级用于数据安全性不是很重要的高性能应用。因为RAID2和RAID4被RAID3和RAID5所包含,所以RAID级别的选择只限于在剩下的级别中进行。比特级拆分(RAID3)不如块级拆分(RAID5),这是因为块级拆分对于大量数据的传输有与RAID3级同样好的数据传输率,同时对于小量数据的传输使用更少的磁盘。对于小量数据传输,磁盘访问时间占主要地位,所以并行读取并没有好处。RAID6提供比RAID5更高的可靠性,可以用于数据安全十分重要的应用。在RAID1和RAID5中选择十分困难。RAID1(包括RAID0+1和RAID1+0)提供最好的写操作性能。RAID5与RAID1相比具有较低的存储负载,但写操作需要更高的时间开销。对于经常进行读操作而很少进行写操作的应用,RAID5是首选。随着磁盘存储容量快速的发展,RAID1应用变广。