人工智能实践:Tensrfow笔记
文章目录
- 一. 人工智能概述
- 1. 什么是人工智能
- 2. 人工智能、机器学习、深度学习之间的关系
- 3. 什么是机器学习
- 4. 机器学习与传统机器工作的差异
- 5. 机器学习的三要素
- 6. 机器学习最主要的应用
- 7. 机器学习的应用领域
- 8. 什么是深度学习
- 9. 神经元模型是什么
- 10. 计算机神经网络的发展(三起两落)
- 二. Tensorflow框架
- 1. 神经网络的参数
- 2. 神经网络的实现过程
- 3. 搭建第一个神经网络
- 4. 前向传播
一. 人工智能概述
1. 什么是人工智能
人工智能是机器模拟人的意识和思维
2. 人工智能、机器学习、深度学习之间的关系

3. 什么是机器学习
机器学习是实现人工智能的一种方法,属于人工智能的子集。它是一种统计学方法,计算机利用已有数据,得出某种模型,再利用此模型预测结果。
特点:随着经验的增加,效果会变好
4. 机器学习与传统机器工作的差异
传统冯诺依曼的计算机工作原理:指令和数据都被预先存储,按照指令先后顺序,逐条读取并运行。特点是:输出结果是特定的。
机器学习的工作原理:预先读取大量已有数据,根据已有数据训练出模型。当模型训练完成,输入新的数据,会计算出新数据对应的结果,输出是结果出现的概率。

简而言之,先用以往数据训练模型,再用模型预测新数据的结果。
5. 机器学习的三要素
数据、算法、算力
6. 机器学习最主要的应用
对连续数据的预测:如预测某小区100平米的房价卖多少钱。
对于离散数据的分类:如根据肿瘤患者的年龄和肿瘤的大小判断良性、恶性。
7. 机器学习的应用领域
计算机视觉、语音识别、自然语言处理。
8. 什么是深度学习
深度学习是深层次神经网络,是机器学习的一种实现方法,是机器学习的子集。
9. 神经元模型是什么

神经元模型:一个包含输入、输出与计算功能的模型
数据输入可以模拟神经元的树突,数据输出可以模拟神经元的轴突,计算可以细胞核,此模型是构建神经网络的基础。
10. 计算机神经网络的发展(三起两落)

二. Tensorflow框架
1. 神经网络的参数
神经网络的参数即神经网络线上的权重W,用变量表示,随机给初值。
W = tf.Variable(tf.random_normal([2,3],stddev=2,mean=0,seed=1))
将生成方式写在Variable方法中,其中:
tf.random_normal():生成正太分布的随机数
[2,3]:产生2行3列矩阵
stddev=2:标准差为2
mean=0:均值为0。随机种子如果去掉,每次生成的随机数会不一致
seed=1:随机种子为1
tf.random_normal()函数可以用tf.truncated_normal()函数替换,表示去掉过大偏离点的正太分布,如果随机生成的数据偏离平均值超过两个标准差,这个数据将重新生成。用平均分布函数tf.random_uniform()替换。
除了生成随机数,还可以生成常量:
tf.zeros生成全0数组:tf.zeros([3,2],int(32))生成[[0,0],[0,0],[0,0]]
tf.ones生成全1数组:tf.ones([3,2],iint(32))生成[[1,1],[1,1],[1,1]]
tf.fill生成全定值数组:tf.fill([3,2],6)生成[[6,6],[6,6],[6,6]]
tf.constant直接给出数组的值,tf.contant([3,2,1])生成[3,2,1]
2. 神经网络的实现过程
1、准备数据集,提取特征,作为输入,喂给神经网络(NN)
2、搭建NN结构,从输入到输出(先搭建计算图,再用会话执行)(NN前向传播算法,计算输出)
3、大量数据喂给NN,迭代优化NN参数(NN反向传播算法,优化参数训练模型)
4、使训练好的模型预测分类
3. 搭建第一个神经网络
-
基于Tensorflow的NN
用张量表示数据,用计算图搭建神经网络,用会话执行计算图,优化线上的权重(参数),得到模型。 -
张量(tensor)
张良就是多维数组(列表),张量可以表示0阶到n阶数组(列表)。用阶表示张量的维数,0阶张量就是标量,表示一个单独的数。
| 维数 | 阶 | 名字 | 例子 |
|---|---|---|---|
| 0-D | 0 | 标量scalar | s = 123 |
| 1-D | 1 | 向量vector | v = [1,2,3] |
| 2-D | 2 | 矩阵matrix | m = [[1,2,3],[,4,5,6],[7,8,9]] |
| n-D | n | 张量tensor | t = [[[… |
- 修改vim
[root@instance-mtfsf05r ~]# vim ~/.vimrc,在.vimrc文件中写入:
set ts = 4
ser nm
ts = 4表示在vim中缩进一个tab键缩进4个空格
nm在vim中显示行号
- 两个张量的加法
# coding:utf-8
# 实现两个张量的加法
import tensorflow as tf # 导入tensorflow模块,简写为tf
a = tf.constant([1.0, 2.0]) # 定义张量a,constant方法用来定义常数
b = tf.constant([3.0, 4.0]) # 定义张量b
rs = a + b
print(rs)
控制台打印:Tensor(“add:0”, shape=(2,), dtype=float32)
add:0:表示张量的名字
add:节点
0:第0个输出
shape=(2,):维度信息
shape:维度
(2,):一维数组,长度为2
dtype=float32:表示数据类型
dtype:数据类型
float32:浮点型数据
- 计算图(Graph)
控制台打印:Tensor(“add:0”, shape=(2,), dtype=float32),只显示这个结果是张量,但并没有运算张量具体的值。计算图:搭建神经网络的计算过程,只搭建、不计算。
神经元的基本模型:
y = XW = x1 * w1 + x2 * w2
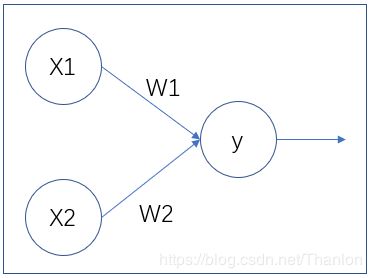
用张量运算描述这个神经元:
# coding:utf-8
# 实现两个张量的加法
import tensorflow as tf # 导入tensorflow模块,简写为tf
x = tf.constant([[1.0, 2.0]]) # 定义张量a,constant方法用来定义常数
w = tf.constant([[3.0], [4.0]]) # 定义张量b
y = tf.matmul(x, w)
print(y)
控制台打印:Tensor(“MatMul:0”, shape=(1, 1), dtype=float32)
结果是一行一列的二维张量。
- 会话(Session)
会话用来执行计算图中的节点运算。
使用Session得到运算结果:
# coding:utf-8
# 实现两个张量的加法
import tensorflow as tf # 导入tensorflow模块,简写为tf
x = tf.constant([[1.0, 2.0]]) # 定义张量a,constant方法用来定义常数
w = tf.constant([[3.0], [4.0]]) # 定义张量b
y = tf.matmul(x, w)
# print(y)
# 使用Session得到运算结果
with tf.Session() as sess:
print(sess.run(y)) # [[11.]]
控制台打印:[[11.]]
即:1.03.0 + 2.04.0 = 11.0
4. 前向传播
前向传播:搭建模型,实现推理(以全连接网络为例)
如:生成一批零件,将体积x1和重量x2为特征输入NN,通过NN后输出一个值。
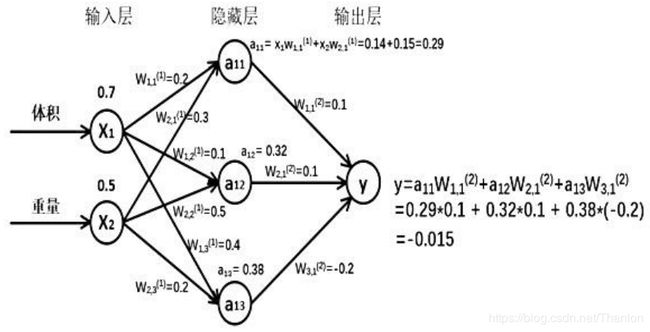
Tensorflow描述前向传播:
X是输入为1x2的矩阵,W前节点编号,后节点编号(层数)为待优化的参数。
W(1)为2x3的矩阵:

a(1) = [a11,a12,a13]为1x3的矩阵=XW(1)
W(2)是3x1的矩阵:
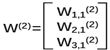
y = a(1)W(2)
则:
a = tf.matmul(X,W1)
y = tf.matmul(a,W2)
两层简单神经网络的计算:
向神经网络喂入一组输入特征:
# coding:utf-8
# 两层简单神经网络(1)
import tensorflow as tf
# 定义输入和参数
x = tf.constant([[0.5, 0.8]])
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 定义前向传播的过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 用会话计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer() # 初始化所有变量的函数简写为初始化节点,用init_op表示
sess.run(init_op)
print(sess.run(y)) # [[3.1674924]]
下面使用placeholder方法实现输入定义,可以在with结构中喂入多组输入特征,方便批量处理:
# coding:utf-8
# 两层简单神经网络
import tensorflow as tf
# 定义输入和参数
# 使用placeholder方法实现输入定义,可以在with结构中喂入多组输入特征,方便批量处理
x = tf.placeholder(tf.float32, shape=(1, 2))
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 定义前向传播的过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 用会话计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer() # 初始化所有变量
sess.run(init_op)
# 喂入一组特征
print(sess.run(y, feed_dict={x: [[0.5, 0.8]]})) # [[3.1674924]]
向神经网络喂入多组特征:
# coding:utf-8
# 两层简单神经网络
import tensorflow as tf
# 定义输入和参数
# 使用placeholder方法实现输入定义,可以在with结构中喂入多组输入特征,方便批量处理.session.run喂入多组数据
x = tf.placeholder(tf.float32, shape=(None, 2))
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 定义前向传播的过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 用会话计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer() # 初始化所有变量
sess.run(init_op)
# 喂入一组特征
print(sess.run(y, feed_dict={x: [[0.5, 0.8], [0.1, 0.2], [0.3, 0.4], [0.3, 0.6], [0.2, 0.9]]})) # [[3.1674924]]
print()
print("w1:", sess.run(w1))
print()
print('w2:', sess.run(w2))
'''
[[3.1674924 ]
[0.72020966]
[1.7270732 ]
[2.160629 ]
[2.5243084 ]]
w1: [[-0.8113182 1.4845988 0.06532937]
[-2.4427042 0.0992484 0.5912243 ]]
w2: [[-0.8113182 ]
[ 1.4845988 ]
[ 0.06532937]]
'''
PS:我的站点:https://www.blueflags.cn
技术交流加微信:
