Hive SQL进阶练习(HQL)
一.数据准备(4表联查)
1.创建车辆信息表:
create external table car(
car_id string comment '车辆ID',
customer_id string comment '客户ID',
car_brand string comment '车辆品牌',
car_serial string comment '车辆系列',
yearcheck_dt string comment '车辆年检日期'
)
row format delimited
fields terminated by '\t';
测试数据:
备注:在linux服务器中找一个目录,在目录中 vi car.csv 之后复制数据再保存即可.
mmm0001 t0001 标志 508 202007
mmm0002 t0002 奔驰 E 202010
mmm0003 t0003 现代 圣达菲 202005
mmm0004 t0004 长安 哈弗H6 201911
mmm0005 t0005 奥迪 A8 201908
mmm0006 t0006 保时捷 玛凯 202001
mmm0007 t0007 保时捷 911 202005
mmm0008 t0008 法拉利 458 202003
mmm0009 t0009 奔驰 GLK 202012
mmm0010 t0010 大众 途锐 202001
2.创建客户信息表:
create external table customer(
customer_id string,
customer_name string,
gender string,
mobile string,
birth string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n';
测试数据:
t0001 王一 男 11111111111 1980/02/14
t0002 黄二 女 22222222222 1985/03/13
t0003 张三 男 33333333333 1973/12/12
t0004 李四 男 44444444444 1990/01/29
t0005 王五 男 55555555555 1960/08/03
t0006 赵六 男 66666666666 1972/01/03
t0007 田七 女 77777777777 1986/06/25
t0008 胡八 男 88888888888 1979/11/22
t0009 陈九 男 99999999999 1995/04/20
t0010 洪十 女 11111111110 1992/07/19
3.创建车辆维修记录信息表:
create external table repair_info(
repair_code string,
customer_id string,
car_id string,
repair_grade string,
repair_dt string,
payment_dt string,
repair_charge string
)
row format delimited
fields terminated by ',';
测试数据:
001,t0010,mmm0010,小修,2019-01-07 13:37:19,2019-01-07 15:26:20,1593.0
002,t0009,mmm0009,小修,2019-01-07 13:36:16,2019-01-07 15:43:11,4023.0
003,t0008,mmm0008,大修,2019-01-07 12:56:20,2019-01-07 14:57:12,329416.0
004,t0007,mmm0007,小修,2019-01-07 12:58:29,2019-01-07 13:51:05,8000.0
005,t0006,mmm0006,小修,2019-01-04 15:05:47,2019-01-04 15:56:55,8000.0
006,t0004,mmm0004,保养,2019-01-04 13:22:12,2019-01-04 15:57:36,2400.0
007,t0002,mmm0002,小修,2019-01-02 13:57:51,2019-01-02 15:16:12,6062.0
008,t0001,mmm0001,大修,2019-01-02 09:40:07,2019-01-02 11:10:09,34667.0
009,t0009,mmm0009,钣喷,2018-12-21 14:43:11,2018-12-21 14:57:43,2000.0
010,t0007,mmm0007,保养,2018-12-21 13:42:35,2018-12-21 15:07:57,142426.0
011,t0008,mmm0008,保养,2018-12-16 12:57:39,2018-12-16 15:01:18,1600.0
012,t0006,mmm0006,小修,2018-11-25 14:21:11,2018-12-25 15:36:17,41906.0
013,t0009,mmm0009,保养,2018-11-25 13:37:15,2018-12-26 08:47:20,922.0
014,t0001,mmm0001,小修,2018-11-25 12:41:07,2018-12-25 16:19:25,600.0
4.创建维修项目表:
create external table repair_jobs(
serial_number int,
repair_code string,
repair_content string
)
row format delimited
fields terminated by '\t';
测试数据:
1 001 更换后轮轮胎
2 001 更换机油机油格
3 001 检查刹车片
4 001 更换前刹车盘
5 002 更换前刹车片
6 002 前保拆装,右前叶整形,后保拆装
7 003 前保油漆,后保油漆,右前叶油漆
8 003 全车打蜡
9 003 更换机油机油格
10 003 车辆初检
11 003 更换轮胎3条,原右前轮换到后轮,四轮定位
12 004 开车门或启动后轮嗡嗡异响
13 004 右后门油漆
14 004 右后门整形修复
15 005 更换机油机油格
16 005 车辆初检
17 005 检查后盖不能自动升降
18 006 全车28项检查
19 007 添加冷媒
20 007 更换水管
21 007 全车打蜡
22 008 检修四轮过减速带“蹦蹦蹦”异响
23 008 更换波箱然热油管
24 008 右后门抛光处理
25 008 更换变速箱油一套:循环清洗
26 010 更换机油机油格
27 010 全车去污打蜡
28 011 全车28项检查
29 012 更换汽油格
30 012 检修车子加油门没反应,有时会熄火
31 012 发动机和底盘常规检查
32 013 车辆初检
33 013 天窗及车身排水系统养护
34 014 更换空气流量计
35 014 更换火花塞
36 014 更换发动机皮带及套件
37 014 全车去污打蜡
二.将数据加载到Hive对应的表中
1.创建测试数据存放目录:
hdfs dfs -mkdir /hqltest 或 hadoop fs -mkdir /hqltest
2.将linux本地目录中的数据上传到hdfs目录中:
hdfs dfs -put car.csv /hqltest
3.加载数据
load data inpath ‘/hqltest/car.csv’ into table hqltestdb.car;
或直接加载本地数据(不用将数据上传到hdfs中)(hqltestdb是数据库名):
load data local inpath ‘/root/hqltest/car.csv’ into table hqltestdb.car;
(其他表的数据加载步骤相同,此处省略)
三.测试
1.字符串操作
(1).字符串截取:substr(字段,截取的起始位置,截取长度)
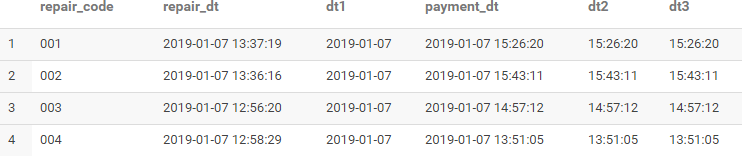
select repair_code,repair_dt,
substr(repair_dt,1,10) dt1,
payment_dt,
substr(payment_dt,12,8) dt2,
substr(payment_dt,12) dt3
from repair_info limit 4;
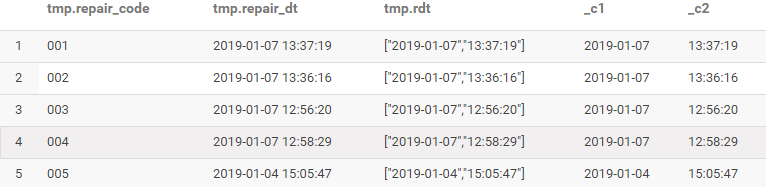
(2).字符串拆分(split拆分后用[]中括号获取数组中的值,下标从0开始)
select *, rdt[0],rdt[1]
from (select repair_code,repair_dt,
split(repair_dt,' ') rdt
from repair_info)tmp
limit 5;
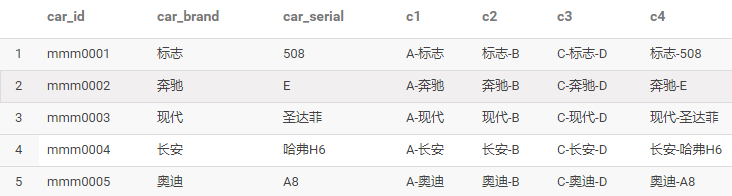
(3).字符串拼接
select car_id,car_brand,car_serial,
concat('A-',car_brand) c1,
concat(car_brand,'-B') c2,
concat('C-',concat(car_brand,'-D')) c3,
concat_ws('-',car_brand,car_serial) c4
from car limit 5
(4).其他
select car_id,
length(car_id) `获取长度`,
reverse(car_id) `反转`,
regexp_replace(car_id,'\\d','-') `匹配所有数字`,
regexp_replace(car_id,'\\D','+') `匹配所有非数字`
from hqltestdb.car limit 4;

2.日期时间类型操作
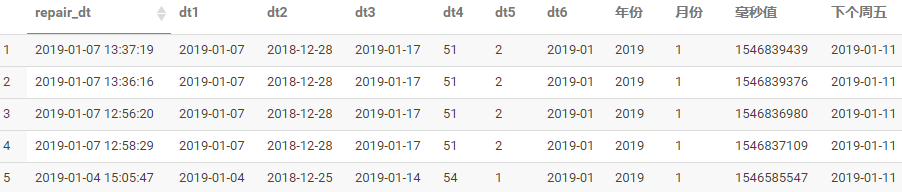
select repair_dt,
to_date(repair_dt) dt1,
date_sub(repair_dt,10) dt2,
date_add(repair_dt,10) dt3,
datediff(current_date(),repair_dt) dt4,
weekofyear(repair_dt) dt5,
date_format(repair_dt,'yyyy-MM') dt6,
year(repair_dt) `年份`,
month(repair_dt) `月份`,
unix_timestamp(repair_dt) `毫秒值`,
next_day(repair_dt,'FR') `下个周五`
from hqltestdb.repair_info limit 5;
3.数字类型操作
select count(1) `计数`,
sum(repair_charge) `求和`,
max(repair_charge) `字符串最大`,
max(cast(repair_charge as double)) `数值最大`,
min(repair_charge) `求最小`,
avg(repair_charge) `求平均1`,
round(avg(repair_charge)) `求平均2`,
round(avg(repair_charge),3) `求平均3`
from hqltestdb.repair_info;

4.常用窗口函数操作
select repair_code,customer_id,repair_charge,
row_number()over(order by customer_id) c1,
dense_rank()over(order by customer_id) c2,
rank()over(order by customer_id) c3,
max(cast(repair_charge as double))over(partition by customer_id) c4,
lag(repair_code,3)over(order by repair_code) c5,
lead(repair_code,3)over(order by repair_code) c6
from hqltestdb.repair_info
order by c1;

5.条件函数
select repair_code,customer_id,repair_grade,repair_charge,
(case repair_grade when '小修' then cast(repair_charge as double)-200
when '大修' then cast(repair_charge as double)-800
when '保养' then cast(repair_charge as double)-100
when '钣喷' then cast(repair_charge as double)-300 end) as t1,
case when repair_grade='小修' then 'XiaoXiu' else 'Others' end as t2,
if(repair_grade='大修','大修','Others') t3
from hqltestdb.repair_info limit 10;
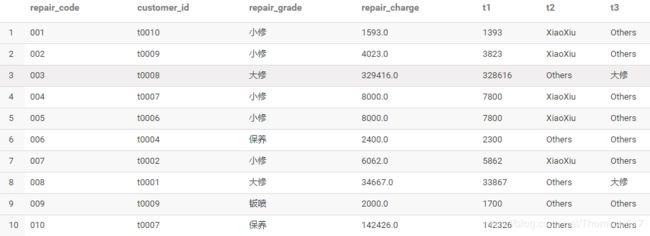
备注:COALESCE(T v1, T v2, …) 返回第一非null的值,如果全部都为NULL就返回NULL.此处不做演示
6.行列转换(内置的UDAF与UDTF)
select repair_code,
concat_ws(';',collect_set(repair_content)) contents
from hqltestdb.repair_jobs
group by repair_code limit 6;

将上图的查询结果进行UDTF转换:
select repair_code,content
from (select repair_code,
concat_ws(';',collect_set(repair_content)) contents
from hqltestdb.repair_jobs
group by repair_code limit 6) tmp
lateral view explode(split(contents,';')) jobs as content;

7.自定义函数的使用
自定义UDF求季度
(1).在Maven中导入依赖(选择Hive的相关版本)
org.apache.hive
hive-exec
2.1.0
(2).自定义Java类继承 org.apache.hadoop.hive.ql.exec.UDF
import org.apache.hadoop.hive.ql.exec.UDF;
public class MyUDF1 extends UDF {
public int evaluate(String date) { //String也可写成Text类型
Integer month = Integer.valueOf(date.substring(5, 7));
/* double v = Math.ceil(month / 3.1);
int quarter = new Double(v).intValue();*/
int quarter = month / 4 + 1;
return quarter;
}
}
(3).将jar包打包发送到服务器中(推荐发送到HDFS的目录下)
(4).创建函数关联Class
将jar包添加到hive的classpath路径中:
add JAR 'hdfs:///path/to/hive_func/quarter.jar'
创建临时函数与开发好的java class关联:
create temporary function quarter2 as ‘com.sun.core.MyUDF1’;
或创建永久使用的函数:
create function quarter2 as 'com.sun.core.MyUDF1' using jar 'hdfs:///path/to/hive_func/quarter.jar'
(5).使用自定义函数
select birth,quarter2(birth) from hqltestdb.customer;
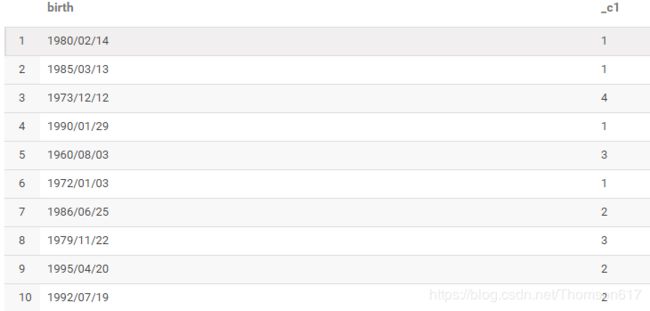
8.综合
查询客户来店维修次数并根据消费总额排名
select t1.*,
concat(concat(car_brand,'-'),car_serial) as car_model,
t3.repair_times,
t3.total_cost,
row_number()over(order by total_cost desc) as ranking
from hqltestdb.customer t1
join (select customer_id,
count(customer_id) as repair_times,
sum(cast(repair_charge as double)) as total_cost
from hqltestdb.repair_info
group by customer_id) t3
on t1.customer_id=t3.customer_id
left join hqltestdb.car t2
on t1.customer_id=t2.customer_id
order by total_cost desc;

查询有车辆打蜡处理的用户信息及维修项
select t2.customer_name,
t2.gender,
ceil(datediff(current_date(),regexp_replace(t2.birth,'/','-'))/365) as age,
t2.mobile,
t3.car_brand,
t3.car_serial,
to_date(t1.repair_dt) repair_dt,
t1.repair_grade,
tmp.repair_contents
from hqltestdb.repair_info t1
join (select repair_code,
concat_ws(';',collect_set(repair_content)) repair_contents
from hqltestdb.repair_jobs
group by repair_code) tmp
on t1.repair_code=tmp.repair_code
left join hqltestdb.customer t2
on t1.customer_id=t2.customer_id
left join hqltestdb.car t3
on t1.car_id=t3.car_id
where repair_contents like '%打蜡%';
