分布式搜索引擎框架ElasticSearch(针对全文检索)
ElasticSearch(ES)
概念:是全文检索的一种框架,解决了lucene的不足,实现了高可用的分布式集群搜索方案,全文检索是从海量数据中通过关键字查询,类似的全文检索框架还有solr、katta、HadoopContrib,但ES仅支持json格式,在搜索效率上是高于solr的,基于Resultful风格(一种请求就是一个资源、是一种请求的设计规范、语法格式路径/参数)
2)ElasticSearch使用
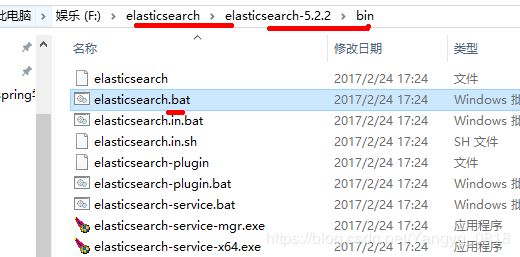
官方下载地址:https://www.elastic.co/downloads/elasticsearch
无需安装
解压运行即可
bin/elasticsearch.bat
启动成功
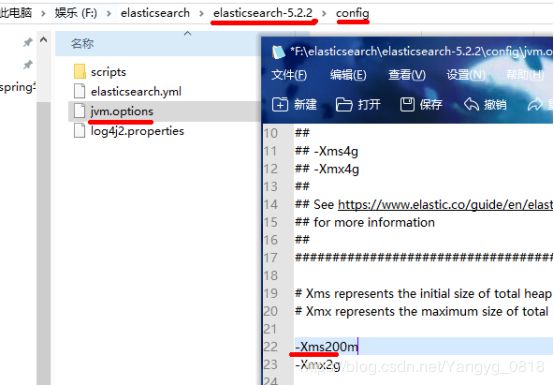
注意启动会消耗内存 一般默认2g 可用自己设置 然后再监控性能内存变化
F:\elasticsearch\elasticsearch-5.2.2\config
![]()
配置ElasticSearch辅助管理工具
Kibana5.2.2下载地址:https://www.elastic.co/downloads/kibana
同样解压启动kibana.bat客户端


访问http://localhost:5601

启动成功
开始es数据管理工作(类似于写mysql的sql语句在客户端)
学习术语:PUT 是创建也是修改 存在就修改,没有就创建
POST 创建
GET 查询
DELETE删除
语法:PUT 索引库名/文档名/文档id
英语注释哈
Kibana--在pc端基本语法使用(练习)
创建一个索引文档
#匹配所有查询
GET _search
{
"query": {
"match_all": {}
}
}
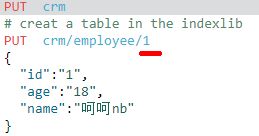
# creat a indexlib 创建一个索引库
PUT crm
# creat a table in the indexlib 在库创建一个等同于Mysql的table {数据}
PUT crm/employee/1
{
"id":"1",
"age":"18",
"name":"呵呵nb"
}
# select a table infomation 根据id查询文档信息
GET crm/employee/1
# select some field 查询部分字段
GET crm/employee/1?_source=age
# only select _source 只查数据源
GET crm/employee/1/_source
# update table 修改文档全部数据
PUT crm/employee/2
{
"id":"2",
"age":"66",
"name":"hahanb"
}
# select a table infomation 查询
GET crm/employee/2
# update some _source 修改部分数据
POST crm/employee/2/_update
{
"doc":{
"name":"yyyyyy"
}
}
GET crm/employee/2
# script update doc fomart:ctx._source.age += 5 使用脚本修改数据
POST crm/employee/2/_update
{
"script" : "ctx._source.age += 5"
}
GET crm/employee/2
# search all 查询全部
GET crm/employee/_search
PUT crm/employee/3
{
"id":"3",
"age":"266",
"name":"hahanb"
}
# delete doc 根据id删除
DELETE crm/employee/3
# many operate delete create index 批量操作
POST _bulk
{ "delete": { "_index": "crm", "_type": "employee", "_id": "1" }}
{ "create": { "_index": "crm", "_type": "blog", "_id": "2" }}
{ "title": "我发布的博客"}
{ "index": { "_index": "crm", "_type": "blog" }}
{ "title": "我的第二博客" }
{ "create": { "_index": "crm", "_type": "blog", "_id": "3" }}
{ "title": "我发布的博客san"}
DELETE crm
#oneMehod many get document filed 批量获取第一种方式
GET _mget
{
"docs":[
{
"_index" : "crm",
"_type" : "blog",
"_id" : 2,
"_source": ["title"]
}
]
}
#oneMehod many get document filed 批量获取第二种方式
GET crm/blog/_mget
{
"ids" : [ "3", "2" ]
}
#page search 分页搜索
POST _bulk
{ "create": { "_index": "crm", "_type": "blog", "_id": "1" }}
{ "title": "我发布的博客1","name":"liu"}
{ "create": { "_index": "crm", "_type": "blog", "_id": "2" }}
{ "title": "我发布的博客2","name":"tang"}
{ "create": { "_index": "crm", "_type": "blog", "_id": "3" }}
{ "title": "我发布的博客3","name":"yyg"}
{ "create": { "_index": "crm", "_type": "blog", "_id": "4" }}
{ "title": "我发布的博客4","name":"qian"}
GET _search?size=2&from=1
#search on the basic of the name 根据name字段搜索 q=File:value
GET crm/blog/_search?q=name:liu
DELETE crm
#DSL search DSL搜索:条件搜索方式
POST _bulk
{ "create": { "_index": "crm", "_type": "user", "_id": "1" }}
{ "title": "我发布的博客1","name":"liu","age":16,"sex":"男"}
{ "create": { "_index": "crm", "_type": "user", "_id": "2" }}
{ "title": "我发布的博客2","name":"tang","age":14,"sex":"女"}
{ "create": { "_index": "crm", "_type": "user", "_id": "3" }}
{ "title": "我发布的博客3","name":"yyg","age":12,"sex":"女"}
{ "create": { "_index": "crm", "_type": "user", "_id": "4" }}
{ "title": "我发布的博客4","name":"qian","age":13,"sex":"男"}
{ "create": { "_index": "crm", "_type": "user", "_id": "5" }}
{ "title": "我发布的博客5","name":"you","age":29,"sex":"男"}
{ "create": { "_index": "crm", "_type": "user", "_id": "6" }}
{ "title": "我发布的博客6","name":"ai","age":15,"sex":"男"}
GET crm/user/_search
#DSL search page and sort 分页排序搜索
GET crm/user/_search
{
"query": {
"match": {"sex": "男"}
},
"from": 1,
"size": 4,
"_source": ["name","age","title"],
"sort": [{"age": "desc"}]
}
#bool query 判断搜索 must必须出现的
GET crm/user/_search
{
"query": {
"bool": {
"must": [
{"match": {"sex": "男"}
}
],
"filter": {
"term": {"name": "ai"}
}
}
}
}
#mangs insert data 批量插入数据
POST _bulk
{ "create": { "_index": "crm", "_type": "user", "_id": "1" }}
{"title":"我发布的博客1","name":"liu","age":16,"sex":"男","join_date":"1990-06-30"}
{ "create": { "_index": "crm", "_type": "user", "_id": "2" }}
{"title":"我发布的博客2","name":"tang","age":14,"sex":"女","join_date":"1990-09-30"}
{ "create": { "_index": "crm", "_type": "user", "_id": "3" }}
{ "title": "我发布的博客3","name":"yyg","age":12,"sex":"女","join_date":"2000-06-30"}
{ "create": { "_index": "crm", "_type": "user", "_id": "4" }}
{ "title": "我发布的博客4","name":"qian","age":13,"sex":"男","join_date":"1909-09-30"}
{ "create": { "_index": "crm", "_type": "user", "_id": "5" }}
{ "title": "我发布的博客5","name":"you","age":29,"sex":"男","join_date":"1996-08-30"}
{ "create": { "_index": "crm", "_type": "user", "_id": "6" }}
{ "title": "我发布的博客6","name":"ai","age":15,"sex":"男","join_date":"2018-07-30"}
DELETE crm
# dsl搜索 必须是男 过滤条件 name是liu的数据 范围在12~29 并按age排序 按1-4显示分页
GET crm/user/_search
{
"query": {
"bool": {
"must": [
{"match": {
"sex":"男"
}}
],
"filter":[
{
"term": {"name":"liu"}
},
{
"range":{
"age": {
"gte": 12,
"lt": 29
}
}
}
]
}
},
"size":4,
"from":1,
"_source": ["name","age"],
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
#range search 范围搜索
GET crm/user/_search
{
"query":{
"range": {
"age": {
"gte": 12,
"lt": 29}
}}}
#make use of analyzer ik分词器的使用
需要给ElasticSearch添加ik分词插件
解压到以下位置 重启即可
ES的IK分词器插件源码地址:
https://github.com/medcl/elasticsearch-analysis-ik
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
GET crm/user/search
#mapping 添加字段时映射后的字段数据类型
GET crm/user/_mapping
{
"user": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
DELETE crm
POST crm/user/1
{
"id":1,
"name":"wa",
"age":15
}
#object mapping 对象映射
POST crm/user/2
{
"id": 2,
"girl.name":"王小花",
"girl.age":26
}
GET crm/user/_mapping
# object array mapping 对象数组映射
POST crm/user/3
{
"id" : 3,
"girl":[{"name":"林志玲","age":32},{"name":"赵丽颖","age":22}]
}
#global variable mapping,confirm part of need to participle全局映射,确定哪些字段需要分词
#利用全局模板覆盖自带的默认模板(不分词) 以_txt结尾的字段就判断需要分词
PUT _template/global_template
{
"template": "*",
"settings": { "number_of_shards": 1 },
"mappings": {
"_default_": {
"_all": {
"enabled": false
},
"dynamic_templates": [
{
"string_as_text": {
"match_mapping_type": "string",
"match": "*_txt",
"mapping": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}}
#删除索引库
DELETE crm
#对crm索引库里的user文档进行字段映射
GET crm/user/_mapping
GET crm/user/_search2)java api对es的管理
创建一个Maven项目
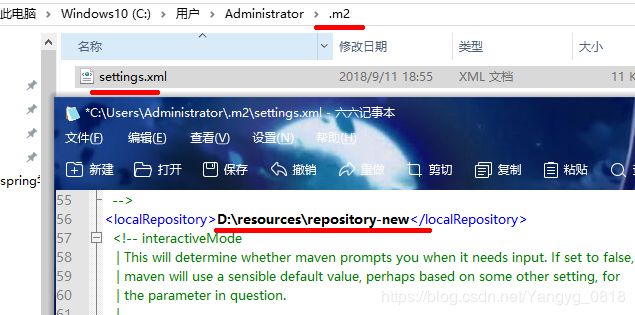
本地仓库配置(阿里云镜像配置)

依赖包
//客户端核心jar
org.elasticsearch.client
transport
5.2.2
//日志依赖jar
org.apache.logging.log4j
log4j-api
2.7
//java测试jar
junit
junit
4.12
test
测试(使用api操作)
package cn.yyg.es;
import static org.junit.Assert.*;
import java.net.InetAddress;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequestBuilder;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexRequestBuilder;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.bytes.BytesReference;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
/*
* java api 操作ElasticSearch 边测试 边查看Kibana执行结果
*/
public class ESTest {
public static TransportClient getClient() throws Exception {
// on startup
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300));
// on shutdown
return client;
}
/**
* @throws Exception
* 功能: 获取索引数据
*/
@Test
public void testGetClient() throws Exception {
//获取客户端对象
TransportClient client = getClient();
//获取索引库数据
GetResponse getResponse = client.prepareGet("crm","user","5").get();
System.out.println(getResponse.getSource());
//关闭索引库资源
client.close();
}
//增加一条索引数据
@Test
public void testAdd() throws Exception {
Map map=new HashMap();
map.put("id",8);
map.put("name","yyy");
map.put("age",18);
//获取客户端对象
TransportClient client = getClient();
//增加索引库数据
IndexRequestBuilder requestBuilder = client.prepareIndex("crm","user","8");
IndexResponse response = requestBuilder.setSource(map).get();
System.out.println(response);
//关闭索引库资源
client.close();
}
//删除
@Test
public void testDelete() throws Exception {
//获取客户端对象
TransportClient client = getClient();
//增加索引库数据
DeleteResponse deleteResponse = client.prepareDelete("crm","user","8").get();
System.out.println(deleteResponse);
//关闭索引库资源
client.close();
}
//修改
@Test
public void testUpdate() throws Exception {
Map map=new HashMap();
map.put("id",8);
map.put("name","tangtang");
map.put("age",21);
//获取客户端对象
TransportClient client = getClient();
//修改 数据 部分修改 也是修改全部
UpdateResponse updateResponse = client.prepareUpdate("crm","user","8").setDoc(map).get();
System.out.println(updateResponse);
//关闭索引库资源
client.close();
}
//修改保存 有就修改 没有就保存
// 修改
@Test
public void getsaveUpdate() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
Map map=new HashMap();
map.put("id",2);
map.put("name","666wdw");
map.put("age",18);
IndexRequest indexRequest = new IndexRequest("crm", "user", "4")
.source(map);
UpdateRequest updateRequest = new UpdateRequest("crm", "user", "4")
.doc(map).upsert(indexRequest);
client.update(updateRequest).get();
// 关闭资源
client.close();
}
//批量增加操作
@Test
public void testManyAdd() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
//得到批量操作的对象
BulkRequestBuilder request=client.prepareBulk();
for(int i=0;i<20;i++){
Map map=new HashMap();
map.put("id",i);
map.put("name","666wdw"+i);
map.put("age",15+i);
map.put("provence","sichuan");
request.add(client.prepareIndex("crm","user",i+"").setSource(map));
}
//提交请求
BulkResponse bulkResponse = request.get();
if (bulkResponse.hasFailures()) {
//处理错误
System.out.println("error");
}
// 关闭资源
client.close();
}
// 搜索
@Test
public void testSearch() throws Exception {
// 获取客户端的es对象
TransportClient client = getClient();
//bool筛选查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 必须
List mustList = boolQueryBuilder.must();
mustList.add(QueryBuilders.termQuery("provence","sichuan"));
//过滤 搜索 sichuan 过滤 age 20-25 分页 0, 4 sort id desc
List filter = boolQueryBuilder.filter();
filter.add(QueryBuilders.rangeQuery("age").gte(18).lte(25));
// 设置分页 排序
SearchResponse searchResponse = client.prepareSearch("crm")
.setFrom(0)
.setSize(2)
.setQuery(boolQueryBuilder)
.addSort("id", SortOrder.DESC)
.get();
System.out.println("总条数:"+searchResponse.getHits().getTotalHits());
SearchHits hits = searchResponse.getHits();
// 循环数据结构
for (SearchHit searchHit : hits) {
System.out.println(searchHit);
}
// 关闭资源
client.close();
}
}