Deep & Cross模型

Deep&Cross显式地做高阶特征组合。就是说设计几层神经网络结构,每一层代表其不同阶的组合,最下面是二阶组合,再套一层,三阶组合,四阶组合,一层一层往上套,这就叫显式地捕获高阶特征组合,Deep&Cross是最开始做这个的。
Deep & Cross Network
对于低阶的组合特征的构造,线性模型使用人工特征工程,FM使用隐向量的内积,FFM引入field的概念,针对不同的field上使用不同隐向量构造组合特征。DNN可以一定程度上实现自动学习特征组合,学习到的特征都是高度非线性的高阶组合特征,这样的隐式的学习特征组合带来的不可解释性,以及低效率的学习,因为并不是所有的特征组合都是有用的。Deep&Cross Network(DCN)将Wide部分替换为由特殊网络结构实现的Cross,在学习特定阶数组合特征的时候效率非常高,自动构造有限高阶的交叉特征,并学习对应权重,告别了繁琐的人工叉乘。
一个DCN模型从嵌入和堆积层开始,然后是并行的是一个交叉网络和一个与之平行的深度网络,之后是最后的组合层,它结合了两个网络的输出。
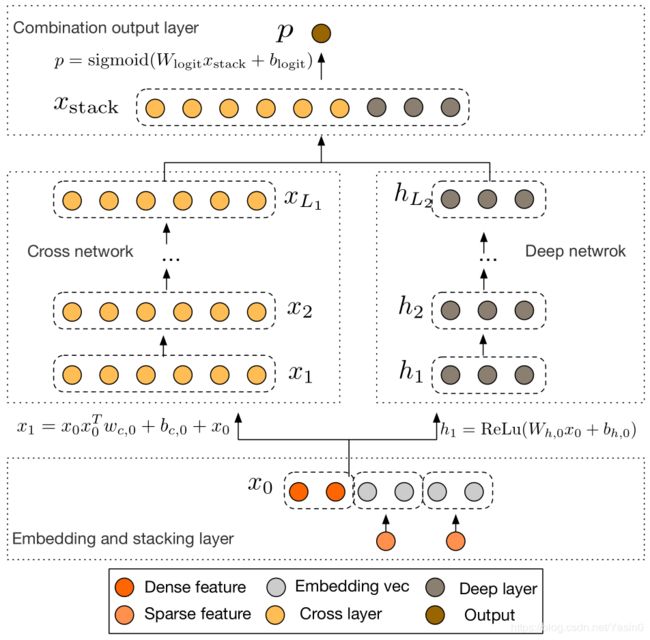
嵌入和堆叠层
文中对原始特征做如下处理:1) 对sparse特征进行embedding,对于multi-hot的sparse特征,embedding之后再做一个简单的average pooling;2) 对dense特征归一化,然后和embedding特征拼接,作为随后Cross层与Deep层的共同输入,即:
CTR预估中,输入的数据既有离散型特征又有连续特征,对于类别型的离散特征,一般进行one-hot处理,但是one-hot之后输入特征维度非常高非常系数。为了减少维数,我们采用Embedding将这些离散特征转换成实数值的稠密向量(通常称为嵌入向量):Embedding操作其实就是用一个矩阵和one-hot之后的输入相乘,也可以看成是一次查询(lookup)。这个Embedding矩阵跟网络中的其他参数是一样的,是需要随着网络一起学习的。
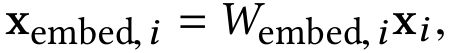
连续型特征规范化之后,和嵌入向量stacking到一起,就得到了原始的输入:然后,我们将嵌入向量与连续特征向量叠加起来形成一个向量: 拼接起来的向量X0将作为我们Cross Network和Deep Network的输入

Cross Network
交叉网络的核心思想是以有效的方式应用显式特征交叉。交叉网络由交叉层组成,每个层具有以下公式:

xl和xl+1 分别是第l层和第l+1层cross layer的输出,wl和bl是这两层之间的连接参数。注意上式中所有的变量均是列向量,W也是列向量,并不是矩阵。xl+1 = f(xl, wl, bl) + xl. 每一层的输出,都是上一层的输出加上feature crossing f。而f就是在拟合该层输出和上一层输出的残差。
Cross Layer 设计的巧妙之处全部体现在上面的计算公式中,我们先看一些明显的细节:1) 每层的神经元个数都相同,都等于输入 的维度
重新看原文章!!!!!!!!!!!!!!
一个交叉层的可视化如图所示:

由上图可以看出,交叉网络的的总参数量非常少,假设一共有Lc层cross layer,起始输入x0的维度为d。那么整个cross network的参数个数为:![]() 因为每一层的W和b都是d维度的。从上式可以发现,复杂度是输入维度d的线性函数。所以相比于deep network,cross network引入的复杂度微不足道。 每一层的维度也都保持一致,最后的output依然与input维度相等。另一方面,特征交叉的概念体现在每一层,当前层的输出的交叉特征都要与第一层输入的原始特征做一次两两交叉,至于在最后又把xlxl 加上,应该是借鉴了ResNet的思想,模型最终拟合的是
因为每一层的W和b都是d维度的。从上式可以发现,复杂度是输入维度d的线性函数。所以相比于deep network,cross network引入的复杂度微不足道。 每一层的维度也都保持一致,最后的output依然与input维度相等。另一方面,特征交叉的概念体现在每一层,当前层的输出的交叉特征都要与第一层输入的原始特征做一次两两交叉,至于在最后又把xlxl 加上,应该是借鉴了ResNet的思想,模型最终拟合的是![]() 这一项的残差。从cross layer的表示公式中也能看出,实际的特征交叉部分
这一项的残差。从cross layer的表示公式中也能看出,实际的特征交叉部分![]() ,拟合就是残差。
,拟合就是残差。
可以看到,交叉网络的特殊结构使交叉特征的程度随着层深度的增加而增大。多项式的最高程度(就输入X0而言)为L层交叉网络L + 1。如果用Lc表示交叉层数,d表示输入维度。然后,参数的数量参与跨网络参数为:d * Lc * 2 (w和b)
交叉网络的少数参数限制了模型容量。为了捕捉高度非线性的相互作用,模型并行地引入了一个深度网络。
High-degree Interaction Across Features:
Cross Network特殊的网络结构使得cross feature的阶数随着layer depth的增加而增加。相对于输入x0来说,一个l层的cross network的cross feature的阶数为l+1。
论文中表示,Cross Network之所以能够高效的学习组合特征,就是因为x0 * xT的秩为1,使得我们不用计算并存储整个的矩阵就可以得到所有的cross terms。
1) 有限高阶:叉乘阶数由网络深度决定,深度 对应最高 阶的叉乘
2) 自动叉乘:Cross输出包含了原始特征从一阶(即本身)到 阶的所有叉乘组合,而模型参数量仅仅随输入维度成线性增长:
3) 参数共享:不同叉乘项对应的权重不同,但并非每个叉乘组合对应独立的权重(指数数量级), 通过参数共享,Cross有效降低了参数量。此外,参数共享还使得模型有更强的泛化性和鲁棒性。例如,如果独立训练权重,当训练集中 这个叉乘特征没有出现 ,对应权重肯定是零,而参数共享则不会,类似地,数据集中的一些噪声可以由大部分正常样本来纠正权重参数的学习这里有一点很值得留意,前面介绍过,文中将dense特征和embedding特征拼接后作为Cross层和Deep层的共同输入。这对于Deep层是合理的,但我们知道人工交叉特征基本是对原始sparse特征进行叉乘,那为何不直接用原始sparse特征作为Cross的输入呢?联系这里介绍的Cross设计,每层layer的节点数都与Cross的输入维度一致的,直接使用大规模高维的sparse特征作为输入,会导致极大地增加Cross的参数量。当然,可以畅想一下,其实直接拿原始sparse特征喂给Cross层,才是论文真正宣称的“省去人工叉乘”的更完美实现,但是现实条件不太允许。所以将高维sparse特征转化为低维的embedding,再喂给Cross,实则是一种trade-off的可行选择。
Deep Network
深度网络就是一个全连接的前馈神经网络,每个深度层具有如下公式:![]()
Combination Layer
Combination Layer把Cross Network和Deep Network的输出拼接起来,然后经过一个加权求和后得到logits,然后经过sigmoid函数得到最终的预测概率。形式化如下: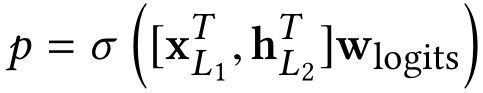
p是最终的预测概率;XL1是d维的,表示Cross Network的最终输出;hL2是m维的,表示Deep Network的最终输出;Wlogits是Combination Layer的权重;最后经过sigmoid函数,得到最终预测概率。
使用带L2正则项的对数损失函数进行联合训练:
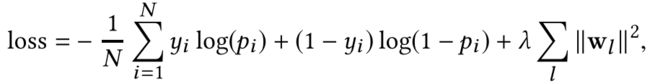
复杂度分析:
假设所有的层都是一样的大小,d为输入X0的维度,m表示每一层的神经元个数,Ld表示层的深度,在深度网络中,总参数量:
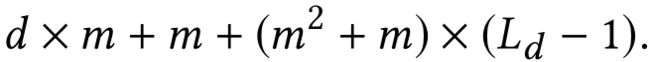
可以看出整个网络结构的参数量主要还是在深度网络一侧。但是,正是因为cross network的参数比较少导致它的表达能力受限,为了能够学习高度非线性的组合特征,DCN并行的引入了Deep Network。
设初始输入 维度为 ,Deep和Cross层数分别为 和 ,为便于分析,设Deep每层神经元个数为 ,则两部分的参数量为:
Cross: Deep:
可以看到Cross的参数量随 增大仅呈“线性增长”!相比于Deep部分,对整体模型的复杂度影响不大,这得益于Cross的特殊网络设计,对于模型在业界落地并实际上线来说,这是一个相当诱人的特点。
DCN特点如下:
提出一种新型的交叉网络结构 DCN,可以显示、自动地构造有限高阶的特征叉乘,一定程度上告别人工特征叉乘,说一定程度是因为文中出于模型复杂度的考虑
Cross部分的复杂度与输入维度呈线性关系,相比DNN非常节约内存。
跟FM一样,DCN同样也是基于参数共享机制的,参数共享不仅仅使得模型更加高效而且使得模型可以泛化到之前没有出现过的特征组合,并且对噪声的抵抗性更加强。
FM是一个非常浅的结构,并且限制在表达二阶组合特征上,DeepCrossNetwork(DCN)把这种参数共享的思想从一层扩展到多层,并且可以学习高阶的特征组合。但是和FM的高阶版本的变体不同,DCN的参数随着输入维度的增长是线性增长的。
DCN能够有效地捕获有限度的有效特征的相互作用,学会高度非线性的相互作用,不需要人工特征工程或遍历搜索,并具有较低的计算成本。
1)提出了一种新的交叉网络,在每个层上明确地应用特征交叉,有效地学习有界度的预测交叉特征,并且不需要手工特征工程或穷举搜索。
2)跨网络简单而有效。通过设计,各层的多项式级数最高,并由层深度决定。网络由所有的交叉项组成,它们的系数各不相同。
3)跨网络内存高效,易于实现。
4)实验结果表明,交叉网络(DCN)在LogLoss上与DNN相比少了近一个量级的参数量。
DCN能有效地找出有限度的有效特征的相互作用,学会高度非线性的相互作用,不需要人工特征或遍历搜索,并具有较低的计算成本。实验结果表明,DCN在对数损失函数上与DNN相比,少了近一个量级的参数量。
使用cross network,在每一层都应用feature crossing。高效的学习了bounded degree组合特征。不需要人工特征工程。
网络结构简单且高效。多项式复杂度由layer depth决定。
相比于DNN,DCN的logloss更低,而且参数的数量将近少了一个数量级。