Kafka重复消费数据问题
kafka重复消费的问题,主要的原因还是在指定的时间内,没有进行kafka的位移提交,导致根据上一次的位移重新poll出新的数据,而这个数据就是上一次没有消费处理完全的(即没有进行offset提交的),这也是导致kafka重复数据的原因.
改为代码中就是,代码中会指定一个session-time来进行kafka数据的poll,供consumer进行消费处理..一次进行poll的数据量由maxpoolrecordsconfig来决定,这个数值就是决定了一次poll的数据量大小...
手动提交offset时,当第一次poll出maxrecords条记录给程序时,程序需要进行处理(数据清理什么的),在session-time内,程序没有处理完这些数据,即还没有进行offset的commit,kafka又会根据上一次的offset进行poll出数据,其实这个数据就是我们刚刚没有消费处理完成的,这就导致了我们这次会有maxrecords条数据是重复的了...
解决这个问题的简单方法,就是调整session-time和maxpollrecordsconfig的值,这个的均值,即最优化的方程式就是:
maxpollrecordsconfig/代码处理单条数据时间=session-time.
我们可以通过优化代码处理数据的时间,增大max和减少session来提高最优化的程序方式.
项目中使用是基于springcloud的JHipster开源框架.consumer消费kafka的基本配置文件如下.
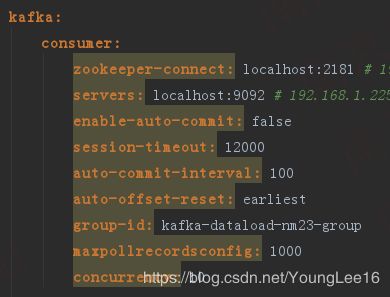
配置类如下:
package com.trs.idap.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.AbstractMessageListenerContainer;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class KafkaConsumerConfiguration {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Value("${spring.data.kafka.consumer.zookeeper-connect}")
private String zookeeper;
@Value("${spring.data.kafka.consumer.servers}")
private String servers;
@Value("${spring.data.kafka.consumer.enable-auto-commit}")
private boolean enableAutoCommit;
@Value("${spring.data.kafka.consumer.session-timeout}")
private String sessionTimeout;
@Value("${spring.data.kafka.consumer.auto-commit-interval}")
private String autoCommitInterval;
@Value("${spring.data.kafka.consumer.group-id}")
private String groupId;
@Value("${spring.data.kafka.consumer.auto-offset-reset}")
private String autoOffsetReset;
@Value("${spring.data.kafka.consumer.concurrency}")
private int concurrency;
@Value("${spring.data.kafka.consumer.maxpollrecordsconfig}")
private int maxPollRecordsConfig;
@Value("${zmAndHeartBeat.switch.kafkaListenerFlag:true}")
private Boolean kafkaListenerFlag;
@Bean
public KafkaListenerContainerFactory> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(concurrency);
factory.getContainerProperties().setPollTimeout(1500);
factory.setBatchListener(true);
factory.getContainerProperties().setAckMode(AbstractMessageListenerContainer.AckMode.MANUAL_IMMEDIATE);
//配置kafka监听默认为false,不监听;
factory.setAutoStartup(kafkaListenerFlag);
logger.info("kafka监听开启状态:"+kafkaListenerFlag);
return factory;
}
public ConsumerFactory consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
public Map consumerConfigs() {
Map propsMap = new HashMap<>(9);
//propsMap.put("zookeeper.connect", zookeeper);
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecordsConfig);//每个批次获取数
return propsMap;
}
}
TIPS:
1,在配置文件中,我们看到了一个concurrent 的数值10..原因是kafka本身是处理高并发和大数据的组件,所以本身是支持多线程操作的...即在poll出数据的时候都是可以支持多线程....是否进行多线程处理,取决于代码中的构建和kafka主题创建的时候给的broker数量.这个数量决定了可以进行多少多线程的数量...即代码中支持10个线程,但是kafka主题支持多少线程还看创建的..
2,配置文件中还有一个autostartup,这个是决定了是否启用kafka监听操作.这样可以通过配置文件来决定是否启用kafka的功能.
附录
常用kafka控制台命令
查看所有kafka主题
bin/kafka-topics.sh --zookeeper node0:2181 --list消费topic主题
bin/kafka-console-consumer.sh --zookeeper node0:2181 --topic zmfor4g1 --from-beginning生产kafka主题数据
./kafka-console-producer.sh --broker-list node0:9092 --topic devicefordingwei创建kafka主题
./kafka-topics.sh --create --zookeeper node0:2181,node2:2181,node4:2181 --replication-factor 2 --partitions 3 --topic ZmTopic查看kafka主题详情
./kafka-topics.sh --zookeeper trsnode0:2181,trsnode1:2181,trsnode2:2181 --describe --topic wifiTopic