卡尔曼滤波(Kalman Filter)
为什么需要卡尔曼滤波?
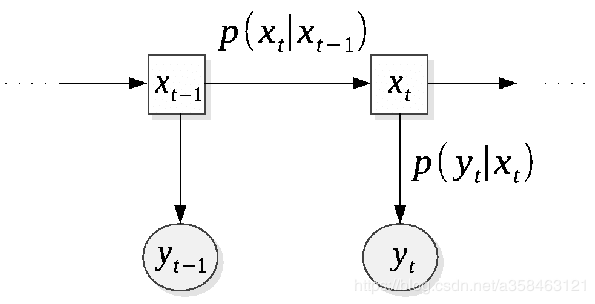
看上图,这其实是一个典型的测量模型,我们设y是观测到的值,x是隐变量。举个例子,x表示火箭燃料温度,可惜的是,燃料内部的温度太高,我们没有办法直接测量,只能测量他火箭外围的温度y,因此每一步的测量都伴随着随机误差,那么如何仅使用观测到的数据y来预测真实的x,这就是卡尔曼滤波(filter)所做的事情。
State Space Model
这个图模型有两类概率,第一类是 p ( y y ∣ x t ) \displaystyle p( y_{y} |x_{t}) p(yy∣xt),称为measurement probability,或者emission probability,另外还有 p ( x t ∣ x t − 1 ) \displaystyle p( x_{t} |x_{t-1}) p(xt∣xt−1),称为转移概率,再加上一个初始概率 p ( x 1 ) \displaystyle p( x_{1}) p(x1),就可以完全表示这个state space model了。通过定义这几个概率的形式,就可以得到不同的模型:
- HMM模型:(i) p ( x t ∣ x t − 1 ) = A x t − 1 , t \displaystyle p( x_{t} |x_{t-1}) =A_{x_{t-1,t}} p(xt∣xt−1)=Axt−1,t,A一个离散的转移矩阵,x是离散的。(ii) P ( y t ∣ x t ) \displaystyle P( y_{t} |x_{t}) P(yt∣xt)是任意的。(iii) p ( x 1 ) = π \displaystyle p( x_{1}) =\pi p(x1)=π
- 线性高斯SSM:(i) p ( x t ∣ x t − 1 ) = N ( A x t − 1 + B , Q ) \displaystyle p( x_{t} |x_{t-1}) =\mathcal{N}( Ax_{t-1} +B,Q) p(xt∣xt−1)=N(Axt−1+B,Q) (ii) P ( y t ∣ x t ) = N ( H x t − 1 + C , R ) \displaystyle P( y_{t} |x_{t}) =\mathcal{N}( Hx_{t-1} +C,R) P(yt∣xt)=N(Hxt−1+C,R)。(iii) p ( x 1 ) = N ( μ 0 , σ 0 ) \displaystyle p( x_{1}) =\mathcal{N}( \mu _{0} ,\sigma _{0}) p(x1)=N(μ0,σ0)
对于上述dynamic模型或者State Space Model(SSM)来说,主要有4种任务:
- Evaluation: p ( y 1 , y 2 , . . . , y t ) \displaystyle p( y_{1} ,y_{2} ,...,y_{t}) p(y1,y2,...,yt)
- 参数学习: arg max θ log p ( y 1 , y 2 , . . . , y ∣ θ ) \displaystyle \arg\max_{\theta }\log p( y_{1} ,y_{2} ,...,y|\theta ) argθmaxlogp(y1,y2,...,y∣θ)
- State decoding: p ( x 1 , x 2 , . . . , x t ∣ y 1 , y 2 , . . . , y t ) \displaystyle p( x_{1} ,x_{2} ,...,x_{t} |y_{1} ,y_{2} ,...,y_{t}) p(x1,x2,...,xt∣y1,y2,...,yt)
- Filtering: p ( x t ∣ y 1 , y 2 , . . . , y t ) \displaystyle p( x_{t} |y_{1} ,y_{2} ,...,y_{t}) p(xt∣y1,y2,...,yt)
其实HMM和线性高斯SSM都可以做这4种任务,但是,HMM可能会更多的涉及第1,2类任务,而线性高斯SSM更多是涉及滤波任务,现在我们要讲的卡尔曼滤波就是做第4个任务filtering.
现在,我们形式化写一下线性高斯SSM的定义:
x t = A x t − 1 + B + w , w ∼ N ( 0 , Q ) y t = H x t + C + v , v ∼ N ( 0 , R ) c o v ( x t − 1 , w ) = 0 , c o v ( x t , v ) = 0 , c o v ( w , v ) = 0 x_{t} =Ax_{t-1} +B+w,\ w\sim N( 0,Q)\\ y_{t} =Hx_{t} +C+v,\ v\sim N( 0,R)\\ cov( x_{t-1} ,w) =0,cov( x_{t} ,v) =0,cov( w,v) =0 xt=Axt−1+B+w, w∼N(0,Q)yt=Hxt+C+v, v∼N(0,R)cov(xt−1,w)=0,cov(xt,v)=0,cov(w,v)=0
于是 p ( x t ∣ x t − 1 ) = N ( A x t − 1 + B , Q ) , P ( y t ∣ x t ) = N ( H x t − 1 + C , R ) \displaystyle p( x_{t} |x_{t-1}) =\mathcal{N}( Ax_{t-1} +B,Q) ,P( y_{t} |x_{t}) =\mathcal{N}( Hx_{t-1} +C,R) p(xt∣xt−1)=N(Axt−1+B,Q),P(yt∣xt)=N(Hxt−1+C,R),为了推导的方便,我们暂时把B,C去掉。
卡尔曼滤波数学推导
现在我们看看怎么做滤波。考虑这个滤波的概率分布:
p ( x t ∣ y 1 , y 2 , . . . , y t ) ⏟ f i l t e r i n g a t t = p ( x t , y 1 , y 2 , . . . , y t ) p ( y 1 , y 2 , . . . , y t ) = p ( y t ∣ x t , y 1 , y 2 , . . . , y t − 1 ) p ( x t , y 1 , y 2 , . . . , y t − 1 ) p ( y 1 , y 2 , . . . , y t ) = p ( y t ∣ x t ) p ( x t ∣ y 1 , y 2 , . . . , y t − 1 ) p ( y 1 , y 2 , . . . , y t − 1 ) p ( y 1 , y 2 , . . . , y t ) ∝ p ( y t ∣ x t ) p ( x t ∣ y 1 , y 2 , . . . , y t − 1 ) ⏟ P r e d i c t i o n a t t \begin{aligned} \underbrace{p( x_{t} |y_{1} ,y_{2} ,...,y_{t})}_{filtering\ at\ t} & =\frac{p( x_{t} ,y_{1} ,y_{2} ,...,y_{t})}{p( y_{1} ,y_{2} ,...,y_{t})}\\ & =\frac{p( y_{t} |x_{t} ,y_{1} ,y_{2} ,...,y_{t-1}) p( x_{t} ,y_{1} ,y_{2} ,...,y_{t-1})}{p( y_{1} ,y_{2} ,...,y_{t})}\\ & =\frac{p( y_{t} |x_{t}) p( x_{t} |y_{1} ,y_{2} ,...,y_{t-1}) p( y_{1} ,y_{2} ,...,y_{t-1})}{p( y_{1} ,y_{2} ,...,y_{t})}\\ & \varpropto p( y_{t} |x_{t})\underbrace{p( x_{t} |y_{1} ,y_{2} ,...,y_{t-1})}_{Prediction\ at\ t} \end{aligned} filtering at t p(xt∣y1,y2,...,yt)=p(y1,y2,...,yt)p(xt,y1,y2,...,yt)=p(y1,y2,...,yt)p(yt∣xt,y1,y2,...,yt−1)p(xt,y1,y2,...,yt−1)=p(y1,y2,...,yt)p(yt∣xt)p(xt∣y1,y2,...,yt−1)p(y1,y2,...,yt−1)∝p(yt∣xt)Prediction at t p(xt∣y1,y2,...,yt−1)
那个正比是因为观测值y是确定的,所以p(y)可以看作常数,于是我们发现,一个滤波,其实是prediction和一个生成概率的乘积,而如果我们把prediction展开来写:
p ( x t ∣ y 1 , y 2 , . . . , y t − 1 ) ⏟ p r e d i c t i o n a t t = ∫ p ( x t ∣ x t − 1 ) p ( x t − 1 ∣ y 1 , y 2 , . . . , y t − 1 ) ⏟ f i l t e r i n g a t t − 1 d x t − 1 = N ( A E ( x t − 1 ∣ y 1 , y 2 , . . . , y t − 1 ) , A Σ ^ t − 1 A T + Q ) \underbrace{p( x_{t} |y_{1} ,y_{2} ,...,y_{t-1})}_{prediction\ at\ t} =\int p( x_{t} |x_{t-1})\underbrace{p( x_{t-1} |y_{1} ,y_{2} ,...,y_{t-1})}_{filtering\ at\ t-1} dx_{t-1} =N\left( AE( x_{t-1} |y_{1} ,y_{2} ,...,y_{t-1}) ,A\hat{\Sigma }_{t-1} A^{T} +Q\right) prediction at t p(xt∣y1,y2,...,yt−1)=∫p(xt∣xt−1)filtering at t−1 p(xt−1∣y1,y2,...,yt−1)dxt−1=N(AE(xt−1∣y1,y2,...,yt−1),AΣ^t−1AT+Q)
神奇的事情发生了,那就是我们的prediction恰好可以用上一时刻的滤波来算,这就形成了一个递归的过程,只要我们迭代地来算,那么整个滤波的都可以算出来!所以,基本套路就是,
- 计算t时刻的prediction,然后t时刻的prediction就用到t-1时刻的filtering,
- 计算t时刻的filtering,而t时刻的filtering又用到了t时刻的prediction。
那么这个迭代的过程就是从t=1开始,往下迭代计算:
t = 1 : ( F i l t e r ) p ( x 1 ∣ y 1 ) ∼ N ( μ ^ 1 , σ ^ 1 ) t = 2 : ( P r e d i c t ) p ( x 2 ∣ y 1 ) ∼ N ( μ ‾ 2 , σ ‾ 2 ) ( F i l t e r ) p ( x 2 ∣ y 1 , y 2 ) ∼ N ( μ ^ 2 , σ ^ 2 ) t = 3 : ( P r e d i c t ) p ( x 3 ∣ y 1 , y 2 ) ∼ N ( μ ‾ 3 , σ ‾ 3 ) ( F i l t e r ) p ( x 3 ∣ y 1 , y 2 , y 3 ) ∼ N ( μ ^ 3 , σ ^ 3 ) \begin{aligned} t=1: & ( Filter) & p( x_{1} |y_{1}) \sim N\left(\hat{\mu }_{1} ,\hat{\sigma }_{1}\right)\\ t=2: & ( Predict) & p( x_{2} |y_{1}) \sim N\left(\overline{\mu }_{2} ,\overline{\sigma }_{2}\right)\\ & ( Filter) & p( x_{2} |y_{1} ,y_{2}) \sim N\left(\hat{\mu }_{2} ,\hat{\sigma }_{2}\right)\\ t=3: & ( Predict) & p( x_{3} |y_{1} ,y_{2}) \sim N\left(\overline{\mu }_{3} ,\overline{\sigma }_{3}\right)\\ & ( Filter) & p( x_{3} |y_{1} ,y_{2} ,y_{3}) \sim N\left(\hat{\mu }_{3} ,\hat{\sigma }_{3}\right) \end{aligned} t=1:t=2:t=3:(Filter)(Predict)(Filter)(Predict)(Filter)p(x1∣y1)∼N(μ^1,σ^1)p(x2∣y1)∼N(μ2,σ2)p(x2∣y1,y2)∼N(μ^2,σ^2)p(x3∣y1,y2)∼N(μ3,σ3)p(x3∣y1,y2,y3)∼N(μ^3,σ^3)
首先记住一个事实,只要随机变量组成的联合分布是高斯分布,那么这些变量的边缘概率分布,或者条件概率分布,都是服从高斯分布的。在这里,显然由于SSM服从线性高斯的模型,所以上面的这些条件概率分布都是服从高斯分布的。此外再记一个事实,当联合分布是高斯分布的时候,条件概率分布的高斯分布是这样的:
( x 1 x 2 ) ∼ N ( ( μ 1 μ 2 ) , ( Σ 11 Σ 12 Σ 21 Σ 22 ) ) p ( x 1 ∣ x 2 ) ∼ N ( μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) , Σ 11 − Σ 12 Σ 22 − 1 Σ 21 ) \left(\begin{array}{ c } \mathbf{x}_{1}\\ \mathbf{x}_{2} \end{array}\right) \sim N\left(\left(\begin{array}{ c } \boldsymbol{\mu }_{1}\\ \boldsymbol{\mu }_{2} \end{array}\right) ,\left(\begin{array}{ c c } \boldsymbol{\Sigma }_{11} & \boldsymbol{\Sigma }_{12}\\ \boldsymbol{\Sigma }_{21} & \mathbf{\Sigma }_{22} \end{array}\right)\right)\\ p(\mathbf{x}_{1} |\mathbf{x}_{2}) \sim N\left(\boldsymbol{\mu }_{1} +\boldsymbol{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2}) ,\boldsymbol{\Sigma }_{11} -\boldsymbol{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}\boldsymbol{\Sigma }_{21}\right) (x1x2)∼N((μ1μ2),(Σ11Σ21Σ12Σ22))p(x1∣x2)∼N(μ1+Σ12Σ22−1(x2−μ2),Σ11−Σ12Σ22−1Σ21)
那好现在,我们回顾一下,我们的目标就是要推导出一下两个公式的具体形式:
p r e d i c t i o n : p ( x t ∣ y 1 , y 2 , . . . , y t − 1 ) f i l t e r i n g : p ( x t ∣ y 1 , y 2 , . . . , y t ) prediction:\ p( x_{t} |y_{1} ,y_{2} ,...,y_{t-1})\\ filtering:\ p( x_{t} |y_{1} ,y_{2} ,...,y_{t}) prediction: p(xt∣y1,y2,...,yt−1)filtering: p(xt∣y1,y2,...,yt)
我们先考虑prediction,想要预测t时刻f的真实状态 x t \displaystyle x_{t} xt,那么根据SSM的定义,自然是需要t-1时刻的真实值 x t − 1 \displaystyle x_{t-1} xt−1来预测的,而这个真实值是用t-1时刻的filtering得到的。那么t-1时刻的真实值(filter)是怎样的呢?设t-1时刻的filter为 p ( x t − 1 ∣ y 1 , y 2 , . . . , y t − 1 ) ∼ N ( μ ^ t − 1 , σ ^ t − 1 ) \displaystyle p( x_{t-1} |y_{1} ,y_{2} ,...,y_{t-1}) \sim N\left(\hat{\mu }_{t-1} ,\hat{\sigma }_{t-1}\right) p(xt−1∣y1,y2,...,yt−1)∼N(μ^t−1,σ^t−1),对其做重参数化:
x t − 1 ∣ y 1 , y 2 , . . . , y t − 1 = E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) + Δ x t − 1 , Δ x t − 1 ∼ N ( 0 , σ ^ t − 1 ) x_{t-1} |y_{1} ,y_{2} ,...,y_{t-1} =E( x_{t-1} |y_{1} ,...,y_{t-1}) +\Delta x_{t-1} ,\ \Delta x_{t-1} \sim N\left( 0,\hat{\sigma }_{t-1}\right) xt−1∣y1,y2,...,yt−1=E(xt−1∣y1,...,yt−1)+Δxt−1, Δxt−1∼N(0,σ^t−1)
因为这个分布是高斯分布,所以我们将他可以写成是均值加上一个随机变量来表示。于是t时刻的预测值可以通过下面的公式进行计算:
x t ∣ y 1 , y 2 , . . . , y t − 1 = A x t − 1 + w = A ( E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) + Δ x t − 1 ) + w = A E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) ⏟ E ( x t ∣ y 1 , . . . , y t − 1 ) + A Δ x t − 1 + w ⏟ Δ x t \begin{aligned} x_{t} |y_{1} ,y_{2} ,...,y_{t-1} & =Ax_{t-1} +w\\ & =A( E( x_{t-1} |y_{1} ,...,y_{t-1}) +\Delta x_{t-1}) +w\\ & =\underbrace{AE( x_{t-1} |y_{1} ,...,y_{t-1})}_{E( x_{t} |y_{1} ,...,y_{t-1})} +\underbrace{A\Delta x_{t-1} +w}_{\Delta x_{t}} \end{aligned} xt∣y1,y2,...,yt−1=Axt−1+w=A(E(xt−1∣y1,...,yt−1)+Δxt−1)+w=E(xt∣y1,...,yt−1) AE(xt−1∣y1,...,yt−1)+Δxt AΔxt−1+w
好了现在t时刻prediction有了,那么t时刻filtering怎么得到呢?刚才介绍的用联合高斯分布来求条件概率分布的技巧就可以用上了,我们发现,如果能够写出这个联合分布的形式:
p ( x t , y t ∣ y 1 , y 2 , . . . , y t − 1 ) p( x_{t} ,y_{t} |y_{1} ,y_{2} ,...,y_{t-1}) p(xt,yt∣y1,y2,...,yt−1)
那不就能够用公式算出 p ( x t ∣ y 1 , y 2 , . . . , y t − 1 , y t ) \displaystyle p( x_{t} |y_{1} ,y_{2} ,...,y_{t-1} ,y_{t}) p(xt∣y1,y2,...,yt−1,yt)的形式了吗?所以为了知道这个联合分布,我们还需要知道分布 p ( y t ∣ y 1 , y 2 , . . . , y t − 1 ) \displaystyle p( y_{t} |y_{1} ,y_{2} ,...,y_{t-1}) p(yt∣y1,y2,...,yt−1)的形式,于是同样的套路:
y t ∣ y 1 , y 2 , . . . , y t − 1 = H x t + v = H ( A x t − 1 + w ) + v = H ( A E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) + A Δ x t − 1 + w ) + v = H A E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) ⏟ E ( y t ∣ y 1 , y 2 , . . . , y t − 1 ) + H A Δ x t − 1 + H w + v ⏟ Δ y t \begin{aligned} y_{t} |y_{1} ,y_{2} ,...,y_{t-1} & =Hx_{t} +v\\ & =H( Ax_{t-1} +w) +v\\ & =H( AE( x_{t-1} |y_{1} ,...,y_{t-1}) +A\Delta x_{t-1} +w) +v\\ & =\underbrace{HAE( x_{t-1} |y_{1} ,...,y_{t-1})}_{E( y_{t} |y_{1} ,y_{2} ,...,y_{t-1})} +\underbrace{HA\Delta x_{t-1} +Hw+v}_{\Delta y_{t}} \end{aligned} yt∣y1,y2,...,yt−1=Hxt+v=H(Axt−1+w)+v=H(AE(xt−1∣y1,...,yt−1)+AΔxt−1+w)+v=E(yt∣y1,y2,...,yt−1) HAE(xt−1∣y1,...,yt−1)+Δyt HAΔxt−1+Hw+v
现在我们已经知道了两个高斯的概率形式了:
p ( x t ∣ y 1 , y 2 , . . . , y t − 1 ) ∼ N ( A E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) , E ( Δ x t Δ x t T ) ⏟ Σ ‾ t ) p ( y t ∣ y 1 , y 2 , . . . , y t − 1 ) ∼ N ( H A E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) , E ( Δ y t Δ y t T ) ⏟ Σ ^ t ) p( x_{t} |y_{1} ,y_{2} ,...,y_{t-1}) \sim N\left( AE( x_{t-1} |y_{1} ,...,y_{t-1}) ,\underbrace{E\left( \Delta x_{t} \Delta x^{T}_{t}\right)}_{\overline{\Sigma }_{t}}\right)\\ p( y_{t} |y_{1} ,y_{2} ,...,y_{t-1}) \sim N\left( HAE( x_{t-1} |y_{1} ,...,y_{t-1}) ,\underbrace{E\left( \Delta y_{t} \Delta y^{T}_{t}\right)}_{\hat{\Sigma }_{t}}\right) p(xt∣y1,y2,...,yt−1)∼N⎝⎜⎛AE(xt−1∣y1,...,yt−1),Σt E(ΔxtΔxtT)⎠⎟⎞p(yt∣y1,y2,...,yt−1)∼N⎝⎜⎛HAE(xt−1∣y1,...,yt−1),Σ^t E(ΔytΔytT)⎠⎟⎞
所以
p ( x t , y t ∣ y 1 , y 2 , . . . , y t − 1 ) = N ( ( A E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) H A E ( x t − 1 ∣ y 1 , . . . , y t − 1 ) ) , ( E ( Δ x t Δ x t T ) E ( Δ x t Δ y t T ) E ( Δ y t T Δ x t T ) E ( Δ y t Δ y t T ) ) ) p( x_{t} ,y_{t} |y_{1} ,y_{2} ,...,y_{t-1}) =N\left(\left(\begin{array}{ c } AE( x_{t-1} |y_{1} ,...,y_{t-1})\\ HAE( x_{t-1} |y_{1} ,...,y_{t-1}) \end{array}\right) ,\left(\begin{array}{ c c } E\left( \Delta x_{t} \Delta x^{T}_{t}\right) & E\left( \Delta x_{t} \Delta y^{T}_{t}\right)\\ E\left( \Delta y^{T}_{t} \Delta x^{T}_{t}\right) & E\left( \Delta y_{t} \Delta y^{T}_{t}\right) \end{array}\right)\right) p(xt,yt∣y1,y2,...,yt−1)=N((AE(xt−1∣y1,...,yt−1)HAE(xt−1∣y1,...,yt−1)),(E(ΔxtΔxtT)E(ΔytTΔxtT)E(ΔxtΔytT)E(ΔytΔytT)))
现在,我们终于能够算 p ( x t ∣ y 1 , y 2 , . . . , y t ) \displaystyle \ p( x_{t} |y_{1} ,y_{2} ,...,y_{t}) p(xt∣y1,y2,...,yt)了,剩下的问题就是的他协方差是什么,我们可以化简一下:
Δ x t Δ x t T = ( A Δ x t − 1 + w ) ( A Δ x t − 1 + w ) T = ( A Δ x t − 1 + w ) ( Δ x t − 1 T A T + w T ) = A Δ x t − 1 Δ x t − 1 T A T + w Δ x t − 1 T A T + w Δ x t − 1 T A T ⏟ c o v = 0 + w w T E ( Δ x t Δ x t T ) = A E ( Δ x t − 1 Δ x t − 1 T ) A T + E ( w w T ) = A Σ ^ t − 1 A T + Q \begin{aligned} \Delta x_{t} \Delta x^{T}_{t} & =( A\Delta x_{t-1} +w)( A\Delta x_{t-1} +w)^{T}\\ & =( A\Delta x_{t-1} +w)\left( \Delta x^{T}_{t-1} A^{T} +w^{T}\right)\\ & =A\Delta x_{t-1} \Delta x^{T}_{t-1} A^{T} +\underbrace{w\Delta x^{T}_{t-1} A^{T} +w\Delta x^{T}_{t-1} A^{T}}_{cov=0} +ww^{T}\\ E\left( \Delta x_{t} \Delta x^{T}_{t}\right) & =AE\left( \Delta x_{t-1} \Delta x^{T}_{t-1}\right) A^{T} +E\left( ww^{T}\right)\\ & =A\hat{\Sigma }_{t-1} A^{T} +Q \end{aligned} ΔxtΔxtTE(ΔxtΔxtT)=(AΔxt−1+w)(AΔxt−1+w)T=(AΔxt−1+w)(Δxt−1TAT+wT)=AΔxt−1Δxt−1TAT+cov=0 wΔxt−1TAT+wΔxt−1TAT+wwT=AE(Δxt−1Δxt−1T)AT+E(wwT)=AΣ^t−1AT+Q
同理,对于y
Δ y t Δ y t T = ( H A Δ x t − 1 + H w + v ) ( H A Δ x t − 1 + H w + v ) T = ( H A Δ x t − 1 + H w + v ) ( Δ x t − 1 T A T H T + w T H T + v T ) = H A Δ x t − 1 Δ x t − 1 T A T H T + H w w T H T + v v T + . . . ⏟ c o v = 0 E ( Δ y t Δ y t T ) = H A ( Δ x t − 1 Δ x t − 1 T ) A T H T + H E ( w w T ) H T + E ( v v T ) = H A Σ ^ t − 1 A T H T + H Q H T + R \begin{aligned} \Delta y_{t} \Delta y^{T}_{t} & =( HA\Delta x_{t-1} +Hw+v)( HA\Delta x_{t-1} +Hw+v)^{T}\\ & =( HA\Delta x_{t-1} +Hw+v)\left( \Delta x^{T}_{t-1} A^{T} H^{T} +w^{T} H^{T} +v^{T}\right)\\ & =HA\Delta x_{t-1} \Delta x^{T}_{t-1} A^{T} H^{T} +Hww^{T} H^{T} +vv^{T} +\underbrace{...}_{cov=0}\\ E\left( \Delta y_{t} \Delta y^{T}_{t}\right) & =HA\left( \Delta x_{t-1} \Delta x^{T}_{t-1}\right) A^{T} H^{T} +HE\left( ww^{T}\right) H^{T} +E\left( vv^{T}\right)\\ & =HA\hat{\Sigma }_{t-1} A^{T} H^{T} +HQH^{T} +R \end{aligned} ΔytΔytTE(ΔytΔytT)=(HAΔxt−1+Hw+v)(HAΔxt−1+Hw+v)T=(HAΔxt−1+Hw+v)(Δxt−1TATHT+wTHT+vT)=HAΔxt−1Δxt−1TATHT+HwwTHT+vvT+cov=0 ...=HA(Δxt−1Δxt−1T)ATHT+HE(wwT)HT+E(vvT)=HAΣ^t−1ATHT+HQHT+R
对于交叉项:
Δ x t Δ y t T = ( A Δ x t − 1 + w ) ( H A Δ x t − 1 + H w + v ) T = ( A Δ x t − 1 + w ) ( Δ x t − 1 T A T H T + w T H T + v T ) = A Δ x t − 1 Δ x t − 1 T A T H T + w w T H T + . . . ⏟ c o v = 0 E ( Δ y t Δ y t T ) = A ( Δ x t − 1 Δ x t − 1 T ) A T H T + E ( w w T ) H T = ( A Σ ^ t − 1 A T + Q ) H T = Σ ‾ t H T \begin{aligned} \Delta x_{t} \Delta y^{T}_{t} & =( A\Delta x_{t-1} +w)( HA\Delta x_{t-1} +Hw+v)^{T}\\ & =( A\Delta x_{t-1} +w)\left( \Delta x^{T}_{t-1} A^{T} H^{T} +w^{T} H^{T} +v^{T}\right)\\ & =A\Delta x_{t-1} \Delta x^{T}_{t-1} A^{T} H^{T} +ww^{T} H^{T} +\underbrace{...}_{cov=0}\\ E\left( \Delta y_{t} \Delta y^{T}_{t}\right) & =A\left( \Delta x_{t-1} \Delta x^{T}_{t-1}\right) A^{T} H^{T} +E\left( ww^{T}\right) H^{T}\\ & =\left( A\hat{\Sigma }_{t-1} A^{T} +Q\right) H^{T}\\ & =\overline{\Sigma }_{t} H^{T} \end{aligned} ΔxtΔytTE(ΔytΔytT)=(AΔxt−1+w)(HAΔxt−1+Hw+v)T=(AΔxt−1+w)(Δxt−1TATHT+wTHT+vT)=AΔxt−1Δxt−1TATHT+wwTHT+cov=0 ...=A(Δxt−1Δxt−1T)ATHT+E(wwT)HT=(AΣ^t−1AT+Q)HT=ΣtHT
至此推导完成,我们可以不停地迭代计算卡尔曼滤波了!总结一下,基本流程就是 f i l t e r i n g 1 → p r e d i c t i o n 2 → f i l t e r i n g 2 → p r e d i c t i o n 3 → . . . \displaystyle filtering_{1}\rightarrow prediction_{2}\rightarrow filtering_{2}\rightarrow prediction_{3}\rightarrow ... filtering1→prediction2→filtering2→prediction3→...
附录:多元高斯分布
假设 x = ( x 1 , x 2 ) \mathbf{x} =(\mathbf{x}_{1} ,\mathbf{x}_{2}) x=(x1,x2)是联合高斯分布,并且参数为:
μ = ( μ 1 μ 2 ) , Σ = ( Σ 11 Σ 12 Σ 21 Σ 22 ) , Λ = Σ − 1 = ( Λ 11 Λ 12 Λ 21 Λ 22 ) \boldsymbol{\mu } =\left(\begin{array}{ c } \boldsymbol{\mu }_{1}\\ \boldsymbol{\mu }_{2} \end{array}\right) ,\boldsymbol{\Sigma } =\left(\begin{array}{ c c } \boldsymbol{\Sigma }_{11} & \boldsymbol{\Sigma }_{12}\\ \boldsymbol{\Sigma }_{21} & \mathbf{\Sigma }_{22} \end{array}\right) ,\boldsymbol{\Lambda } =\mathbf{\Sigma }^{-1} =\left(\begin{array}{ c c } \boldsymbol{\Lambda }_{11} & \mathbf{\Lambda }_{12}\\ \boldsymbol{\Lambda }_{21} & \mathbf{\Lambda }_{22} \end{array}\right) μ=(μ1μ2),Σ=(Σ11Σ21Σ12Σ22),Λ=Σ−1=(Λ11Λ21Λ12Λ22)
那么他们的边缘分布为
p ( x 1 ) = N ( x 1 ∣ μ 1 , Σ 11 ) p ( x 2 ) = N ( x 2 ∣ μ 2 , Σ 22 ) \begin{aligned} p(\mathbf{x}_{1}) & =\mathcal{N}(\mathbf{x}_{1} |\boldsymbol{\mu }_{1} ,\mathbf{\Sigma }_{11})\\ p(\mathbf{x}_{2}) & =\mathcal{N}(\mathbf{x}_{2} |\boldsymbol{\mu }_{2} ,\boldsymbol{\Sigma }_{22}) \end{aligned} p(x1)p(x2)=N(x1∣μ1,Σ11)=N(x2∣μ2,Σ22)
以及其条件分布为:
p ( x 1 ∣ x 2 ) = N ( x 1 ∣ μ 1 ∣ 2 , Σ 1 ∣ 2 ) μ 1 ∣ 2 = μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) = μ 1 − Λ 11 − 1 Λ 12 ( x 2 − μ 2 ) = Σ 1 ∣ 2 ( Λ 11 μ 1 − Λ 12 ( x 2 − μ 2 ) ) Σ 1 ∣ 2 = Σ 11 − Σ 12 Σ 22 − 1 Σ 21 \begin{aligned} p(\mathbf{x}_{1} |\mathbf{x}_{2}) & =\mathcal{N}(\mathbf{x}_{1} |\boldsymbol{\mu }_{1|2} ,\boldsymbol{\Sigma }_{1|2})\\ \boldsymbol{\mu }_{1|2} & =\boldsymbol{\mu }_{1} +\boldsymbol{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2})\\ & =\boldsymbol{\mu }_{1} -\boldsymbol{\Lambda }^{-1}_{11}\boldsymbol{\Lambda }_{12}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2})\\ & =\boldsymbol{\Sigma }_{1|2}(\boldsymbol{\Lambda }_{11}\boldsymbol{\mu }_{1} -\boldsymbol{\Lambda }_{12}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2}))\\ \boldsymbol{\Sigma }_{1|2} & =\boldsymbol{\Sigma }_{11} -\boldsymbol{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}\boldsymbol{\Sigma }_{21} \end{aligned} p(x1∣x2)μ1∣2Σ1∣2=N(x1∣μ1∣2,Σ1∣2)=μ1+Σ12Σ22−1(x2−μ2)=μ1−Λ11−1Λ12(x2−μ2)=Σ1∣2(Λ11μ1−Λ12(x2−μ2))=Σ11−Σ12Σ22−1Σ21
以上条件分布非常重要!
这个东西是怎么推出来的呢?他的推导比较直接,那就是利用概率分解:
p ( x 1 , x 2 ) = p ( x 1 ∣ x 2 ) p ( x 2 ) p(\mathbf{x}_{1} ,\mathbf{x}_{2}) =p(\mathbf{x}_{1} |\mathbf{x}_{2}) p(\mathbf{x}_{2}) p(x1,x2)=p(x1∣x2)p(x2)
只要我们把 p ( x 1 , x 2 ) \displaystyle p(\mathbf{x}_{1} ,\mathbf{x}_{2}) p(x1,x2)和 p ( x 2 ) \displaystyle p(\mathbf{x}_{2}) p(x2)都写出来,自然就知道 p ( x 1 ∣ x 2 ) \displaystyle p(\mathbf{x}_{1} |\mathbf{x}_{2}) p(x1∣x2)是什么了。首先对于 p ( x 1 , x 2 ) \displaystyle p(\mathbf{x}_{1} ,\mathbf{x}_{2}) p(x1,x2)的分布如下:
E = exp { − 1 2 ( x 1 − μ 1 x 2 − μ 2 ) T ( Σ 11 Σ 12 Σ 21 Σ 22 ) − 1 ( x 1 − μ 1 x 2 − μ 2 ) } E=\exp\left\{-\frac{1}{2}\left(\begin{array}{ c } \mathbf{x}_{1} -\boldsymbol{\mu }_{1}\\ \mathbf{x}_{2} -\boldsymbol{\mu }_{2} \end{array}\right)^{T}\left(\begin{array}{ c c } \boldsymbol{\Sigma }_{11} & \boldsymbol{\Sigma }_{12}\\ \boldsymbol{\Sigma }_{21} & \boldsymbol{\Sigma }_{22} \end{array}\right)^{-1}\left(\begin{array}{ c } \mathbf{x}_{1} -\boldsymbol{\mu }_{1}\\ \mathbf{x}_{2} -\boldsymbol{\mu }_{2} \end{array}\right)\right\} E=exp{−21(x1−μ1x2−μ2)T(Σ11Σ21Σ12Σ22)−1(x1−μ1x2−μ2)}
于是我们用公式将逆矩阵展开得到:
E = exp { − 1 2 ( x 1 − μ 1 x 2 − μ 2 ) T ( I 0 Σ 22 − 1 Σ 21 I ) ( ( Σ / Σ 22 ) − 1 0 0 Σ 22 − 1 ) × ( I − Σ 12 Σ 22 − 1 0 I ) ( x 1 − μ 1 x 2 − μ 2 ) } = exp { − 1 2 ( x 1 − μ 1 − Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) ) ⏟ μ 1 ∣ 2 T ( Σ / Σ 22 ⏟ Σ 1 ∣ 2 ) − 1 ( x 1 − μ 1 − Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) ) ⏟ μ 1 ∣ 2 } × exp { − 1 2 ( x 2 − μ 2 ) T Σ 22 − 1 ( x 2 − μ 2 ) } = p ( x 1 ∣ x 2 ) p ( x 2 ) \begin{aligned} E= & \exp\{-\frac{1}{2}\left(\begin{array}{ c } \mathbf{x}_{1} -\boldsymbol{\mu }_{1}\\ \mathbf{x}_{2} -\boldsymbol{\mu }_{2} \end{array}\right)^{T}\left(\begin{array}{ c c } \mathbf{I} & \mathbf{0}\\ \mathbf{\Sigma }^{-1}_{22}\boldsymbol{\Sigma }_{21} & \mathbf{I} \end{array}\right)\left(\begin{array}{ c c } (\boldsymbol{\Sigma } /\boldsymbol{\Sigma }_{22})^{-1} & \mathbf{0}\\ \mathbf{0} & \mathbf{\Sigma }^{-1}_{22} \end{array}\right)\\ & \times \left(\begin{array}{ c c } \mathbf{I} & -\boldsymbol{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}\\ \mathbf{0} & \mathbf{I} \end{array}\right)\left(\begin{array}{ l } \mathbf{x}_{1} -\boldsymbol{\mu }_{1}\\ \mathbf{x}_{2} -\boldsymbol{\mu }_{2} \end{array}\right)\}\\ = & \exp\left\{-\frac{1}{2}\underbrace{\left(\mathbf{x}_{1} -\boldsymbol{\mu }_{1} -\boldsymbol{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2})\right)}_{\boldsymbol{\mu }_{1|2}}^{T}\left(\underbrace{\boldsymbol{\Sigma } /\mathbf{\Sigma }_{22}}_{\mathbf{\Sigma }_{1|2}}\right)^{-1}\underbrace{\left(\mathbf{x}_{1} -\boldsymbol{\mu }_{1} -\mathbf{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2})\right)}_{\boldsymbol{\mu }_{1|2}}\right\}\\ & \times \exp\left\{-\frac{1}{2}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2})^{T}\boldsymbol{\Sigma }^{-1}_{22}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2})\right\}\\ = & p(\mathbf{x}_{1} |\mathbf{x}_{2}) p(\mathbf{x}_{2}) \end{aligned} E===exp{−21(x1−μ1x2−μ2)T(IΣ22−1Σ210I)((Σ/Σ22)−100Σ22−1)×(I0−Σ12Σ22−1I)(x1−μ1x2−μ2)}exp⎩⎪⎨⎪⎧−21T (x1−μ1−Σ12Σ22−1(x2−μ2))⎝⎜⎛Σ1∣2 Σ/Σ22⎠⎟⎞−1μ1∣2 (x1−μ1−Σ12Σ22−1(x2−μ2))⎭⎪⎬⎪⎫×exp{−21(x2−μ2)TΣ22−1(x2−μ2)}p(x1∣x2)p(x2)
最终我们发现,条件高斯分布的期望和方差分别就是
μ 1 ∣ 2 = μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) Σ 1 ∣ 2 = Σ / Σ 22 = Σ 11 − Σ 12 Σ 22 − 1 Σ 21 \begin{aligned} \boldsymbol{\mu }_{1|2} & =\boldsymbol{\mu }_{1} +\boldsymbol{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}(\mathbf{x}_{2} -\boldsymbol{\mu }_{2})\\ \boldsymbol{\Sigma }_{1|2} & =\boldsymbol{\Sigma } /\boldsymbol{\Sigma }_{22} =\boldsymbol{\Sigma }_{11} -\boldsymbol{\Sigma }_{12}\boldsymbol{\Sigma }^{-1}_{22}\boldsymbol{\Sigma }_{21} \end{aligned} μ1∣2Σ1∣2=μ1+Σ12Σ22−1(x2−μ2)=Σ/Σ22=Σ11−Σ12Σ22−1Σ21
参考资料
文本思路主要参考了徐亦达老师的课程:徐亦达 卡尔曼滤波
https://en.wikipedia.org/wiki/Kalman_filter