算法——图之加权有向图
这篇讨论加权有向图。
加权有向图是在有向图的基础上,边的赋予权重信息的。
加权有向图有很多应用。最典型的就是最短路径问题。我们日常生活中也经常遇到这种问题,例如从一个点出发,到达另外一个点,怎么过去才是最快的等等。
而由于图的复杂性,最短路径问题并不十分的容易。例如,给定图的边的权重可能是负权重等。
为了解决最短路径问题,我们首先要定义一种加权有向图的数据结构,良好的数据结构是成功的一半。
和之前一样,我们用邻接表矩阵的方式来存放图,链表中存放的是我们定义的数据结构的边。
如下图所示:
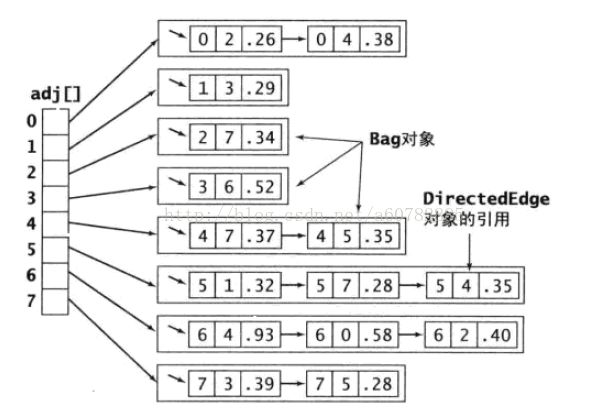
那么我们首先要做的就是定义边的数据结构。
如图,我们需要边的起始顶点,边的终止顶点,边的权重信息。
得到如下图的数据结构:
public class DirectedEdge {
private double weight;
private int from;
private int to;
public DirectedEdge(int from, int to, double weight) {
this.from = from;
this.to = to;
this.weight = weight;
}
public int getFrom() {
return from;
}
public int getTo() {
return to;
}
public double weight() {
return weight;
}
public int compareTo(DirectedEdge e) {
if (weight > e.weight()) return 1;
if (weight < e.weight()) return -1;
return 0;
}
public String toString() {
String s = from + " -> " + to + ", weight: " + weight;
return s;
}
}
加权有向图,我们首先需要一个邻接表矩阵,还需要顶点的数量,边的数量。
得到如下数据结构:
public class EdgeWeightDiGraph {
private List[] adj; // 邻接表矩阵
private int V; // 点的数目
private int E; // 边的数目
public EdgeWeightDiGraph(int V) {
this.V = V;
E = 0;
adj = (List[]) new List[V];
for (int i = 0; i < V; i++) {
adj[i] = new ArrayList<>();
}
}
public void addEdge(DirectedEdge e) {
adj[e.getFrom()].add(e);
E++;
}
public int V() {
return V;
}
public int E() {
return E;
}
public Iterable adj(int v) {
return adj[v];
}
public Iterable edges() {
List edges = new ArrayList<>();
for (int i = 0; i < V; i++) {
for (DirectedEdge e : adj[i]) {
edges.add(e);
}
}
return edges;
}
public String toString() {
String s = V + " 个顶点, " + E + " 条边\n";
for (int i = 0; i < V; i++) {
s += i + ": ";
for (DirectedEdge e : adj(i)) {
s += e.getTo() + " [" + e.weight() + "], ";
}
s += "\n";
}
return s;
}
} 首先我们来看最短路径中最出名的算法Dijkstra算法。
思路:
从起点开始,首先初始化到起点的距离为0,再初始化到其他顶点的路径为无穷大。
每次选择到达起点最近的那个顶点未被选择过的顶点,查看这个顶点作为起点的边,如果发现从这个顶点到边的另一个顶点的距离会更短,就更新它。
可以发现,每次选择到起点最近的那个没被选择过的顶点,最终会选择所有的顶点,而这些顶点的边也会被全部遍历一次。因为总是先计算距离最小的那个顶点,所以每个后来的顶点都是在前面最小路径的基础上得到的,无法更短的路径,也就是后来计算的顶点都是最短路径,这个可以用数学归纳法非常简单的理解。
那么我们就来实现Dijkstra算法。
我们发现这个算法有以下关键点:1.记录当前顶点到起点的距离 2.每次获取距离起点最近的顶点3.比较当前边到达的点的距离,如果更短就更新的操作。
1.记录当前顶点到起点的距离:这个记录十分的重要,因为我们的更新距离的操作,每次都要基于当前顶点的距离的比较结果来更新。我们使用一个double[]数组来存放。
2.每次获取距离起点最近的顶点:我们如何获取当前距离起点最近的顶点呢?最容易想到的方法就是遍历一次,这并不难实现,不过我们这里采用另一种方式,使用优先队列的方法来存放到起点的点,他们会根据距离来进行排序。
3.更新边的距离操作: 这是算法的核心操作了,不过也是十分容易的,例如现在拿到了边v->w,我们只需要进行一次比较disTo[w] > disTo[v] + e.weight(),也就是说,如果发现从这条边去到顶点w会使得disTo[w]更小的话,我们就更新它。否则就不更新。
我们得到如下的实现:
public class DijkstraSP {
class QueueItem {
int node;
double distance;
public QueueItem(int node, double distance) {
this.node = node;
this.distance = distance;
}
public int compareTo(QueueItem t) {
if (node > t.node) return 1;
if (node < t.node) return -1;
return 0;
}
}
Comparator itemComparator = new Comparator() {
public int compare(QueueItem t1, QueueItem t2) {
return t1.compareTo(t2);
}
};
private Queue pq; // 获取当前distance中最小值
private double[] disTo; // 到起点的距离
private DirectedEdge[] edgeTo; // 路径
public DijkstraSP(EdgeWeightDiGraph g, int begin) {
pq = new PriorityQueue<>(itemComparator);
disTo = new double[g.V()];
edgeTo = new DirectedEdge[g.V()];
for (int i = 0; i < g.V(); i++) {
disTo[i] = Double.POSITIVE_INFINITY;
}
pq.add(new QueueItem(0, 0.0));
disTo[0] = 0;
while (!pq.isEmpty()) { // 获取Queue顶元素,松弛对应的顶点的边
QueueItem t = pq.poll();
relax(g, t.node);
}
}
private void relax(EdgeWeightDiGraph g, int v) {
for (DirectedEdge e : g.adj(v)) {
int to = e.getTo();
if (disTo[to] > disTo[v] + e.weight()) {
disTo[to] = disTo[v] + e.weight();
edgeTo[to] = e;
pq.offer(new QueueItem(to, disTo[to]));
}
}
}
public double disTo(int v) {
return disTo[v];
}
public boolean hasPath(int v) {
return disTo[v] < Double.POSITIVE_INFINITY;
}
public Iterable pathTo(int v) {
if (!hasPath(v)) return null;
List path = new ArrayList<>();
for (DirectedEdge e = edgeTo[v]; e != null; e = edgeTo[e.getFrom()]) {
path.add(0, e);
}
return path;
}
} 我们会发现,Dijkstra算法和Prim算法非常的类似,都是从起点出发,对附近的顶点进行操作。不同的是,Dijkstra算法是根据到地点的距离来遍历顶点的,而Prim算法是根据顶点到生成树的距离来遍历顶点的。
Dijkstra算法虽然很不错,但是他有局限性。
Dijkstra算法不能处理负权重的边。
为什么呢?我们来看这个图:

用Dijkstra算法来处理这张图,会发生什么问题呢?
我们使用这种格式表明到顶点的距离:[顶点 距离]
第一步,最近的距离的点为0,更新得到[2, 10]和[3, 1]。
第二步,最近的距离的点为3,更新得到[4, 2]。
第三步,最近的距离的点为4,没有可以更新的点。
第四步,最近的距离的点为2,更新得到[3, -1]。
结束。
我们就会发现,原本到顶点4的最短距离应该为0,但是却得到2。这就是负权重在Dijkstra中得到的结果。
也就是说,如果某个节点v已经被确定了的情况下,v之前的节点被更新,v得不到更新。
当然,对于有些情况来说,是可以得到正确结果的,但是这只是碰巧而已,这种不稳定性不是我们希望看到的。
我们会发现,更新的顶点的顺序是非常重要的,如果我们先更新了顶点2,再更新顶点3和4,那么我们就可以得到正确的结果了。
可是我们如何能得到正确的更新顺序呢?
对于无环的加权有向图,我们可以采用这种方式:
我们首先得到加权有向图的拓扑排序,使用这个拓扑排序的顺序来更新顶点。更新之后得到的就是最短路径。当然,在这种无环图中,最短路径的起点是拓扑排序的起点。
为什么可以这样呢?
使用拓扑排序得到的节点的顺序是根据依赖的,最前面的节点没有依赖,所以很显然我们可以直接得到最短路径0。而对于后面的某个节点v,v的被依赖的节点的距离已经确定了,是不会被改变的了,所以v的最短路径可以被确定下来。
这种基于拓扑排序的方法,我们是可以对具有负权重的图进行最短路径的计算的,因为负权重在其中并不会影响什么。
实现如下:
首先是计算拓扑排序,前面的几篇中提到,使用深搜就可以得到拓扑排序了:
public class Topological { // 深搜解决图的可达性和路径,保存拓扑排序
private boolean[] isMarked; // 是否可达
private Integer[] edgeTo; // 记录路径
private List begin; // 开始节点们
private List reversePost; // 拓扑排序顺序
public Topological(EdgeWeightDiGraph g) { // 所有节点遍历
reversePost = new ArrayList<>();
isMarked = new boolean[g.V()];
edgeTo = new Integer[g.V()];
List begins = new ArrayList<>();
for (int i = 0; i < g.V(); i++) {
begins.add(i);
}
this.begin = begins;
for (int i = 0; i < g.V(); i++) {
if (!isMarked[i]) {
dfs(g, i);
}
}
}
public void dfs(EdgeWeightDiGraph g, int begin) { // 深搜将所有节点遍历,标记被访问过的节点
isMarked[begin] = true;
for (DirectedEdge e : g.adj(begin)) {
int node = e.getTo();
if (!isMarked[node]) {
edgeTo[node] = begin;
dfs(g, node);
}
}
reversePost.add(0, begin);
}
public boolean hasPath(int v) {
return isMarked[v];
}
public String pathTo(int v) {
if (!hasPath(v)) {
return "";
}
Stack stack = new Stack<>();
stack.push(v);
for (int i = v; !begin.contains(i); i = edgeTo[i]) {
stack.push(edgeTo[i]);
}
return stack.toString();
}
public Iterable reversePost() {
return reversePost;
}
} public class AcycleSP { // 无环加权有向图最短路径
private double[] disTo;
private DirectedEdge[] edgeTo;
public AcycleSP(EdgeWeightDiGraph g) {
disTo = new double[g.V()];
edgeTo = new DirectedEdge[g.V()];
for (int i = 0; i < g.V(); i++) {
disTo[i] = Double.POSITIVE_INFINITY;
}
int count = 0;
Topological topo = new Topological(g);
for (Integer node : topo.reversePost()) {
if (count == 0) disTo[node] = 0;
relax(g, node);
count++;
}
}
private void relax(EdgeWeightDiGraph g, int v) {
for (DirectedEdge e : g.adj(v)) {
int to = e.getTo();
if (disTo[to] > disTo[v] + e.weight()) {
disTo[to] = disTo[v] + e.weight();
edgeTo[to] = e;
}
}
}
public double disTo(int v) {
return disTo[v];
}
public boolean hasPath(int v) {
return disTo[v] < Double.POSITIVE_INFINITY;
}
public Iterable pathTo(int v) {
if (!hasPath(v)) return null;
List path = new ArrayList<>();
for (DirectedEdge e = edgeTo[v]; e != null; e = edgeTo[e.getFrom()]) {
path.add(0, e);
}
return path;
}
} 在无环加权图的最短路径的计算中,使用拓扑排序的方法是最快的了,在方法上已经没有什么可以改进的空间,比Dijkstra算法快数倍。
同样的,我们可以使用这个方法来计算最长路径,只需要将更新算法的比较反向一下,就可以做到了。
虽然这个方法处理了负权重,但是前提是无环加权图,这个限制很大啊,并不具备通用性。有没有更加通用的,可以处理负权重的算法呢?
有的,使用Bellman-Ford算法就可以解决负权重的问题。
我们继续关注Dijkstra算法在负权重中出现的问题,并且更一般化的话,图是有环的,也就是我们无法知道更新节点的顺序。
在不知道顺序的情况下,我们如何得到最短路径呢?
一种非常简单的想法就是:按照任意顺序更新节点,只需要更新V轮,就能得到最短路径。
因为负权重会使得前面更新的节点无法得到更新,所以我们就多运行一次程序,就能将更新往前推一个乃至多个节点,最多更新V次,就能将结果完全更新到终点去。
这样很显然,需要的时间复杂度为O(EV),E是边数,V为节点数。这样的时间复杂度有点难以接受。我们需要改进一下。
基于队列的Bellman-Ford算法:
我们发现,在一轮运行中,许多边的更新都是不会成功的,只有那些disTo距离发生变化的顶点所指出的边才能改变其他的顶点的距离。
所以我们使用一个队列来保存更新的节点。
例如:
在这个图中。
1.将1加入队列。
2.得到队列头1,更新对应的边的节点[2, 10], [3, 1]。按照任意顺序加入队列,例如增加3, 2.
3.得到队列头3,更新对应的边的节点[4, 2],将4增加进入队列。
4.得到队列头2,更新对应的边的节点[3, -1],将3增加进入队列。
5.得到队列头4,没有边可以更新,没有节点加入队列。
6.得到队列头3,更新对应的边的节点[4,0].将4增加进入队列。
7.得到队列头4,没有边可以更新,没有节点加入队列。
可以发现,这里采用了队列的方式,当某个节点被更新了,那么依赖他的节点也会被更新的这么一个策略。
实现:
public class BellmanFordSP {
private Queue queue; // 需要被放松的顶点
private boolean[] onQueue; // 顶点是否在队列中
private DirectedEdge[] edgeTo;
private double[] disTo;
public BellmanFordSP(EdgeWeightDiGraph g, int begin) {
queue = new LinkedList();
onQueue = new boolean[g.V()];
edgeTo = new DirectedEdge[g.V()];
disTo = new double[g.V()];
for (int i = 0; i < g.V(); i++) {
disTo[i] = Double.POSITIVE_INFINITY;
}
disTo[begin] = 0;
onQueue[begin] = true;
queue.offer(begin);
while (!queue.isEmpty()) {
Integer node = queue.poll();
onQueue[node] = false;
relax(g, node);
}
}
private void relax(EdgeWeightDiGraph g, int v) {
for (DirectedEdge e : g.adj(v)) {
int to = e.getTo();
if (disTo[to] > disTo[v] + e.weight()) {
disTo[to] = disTo[v] + e.weight();
edgeTo[to] = e;
if (!onQueue[to]) {
queue.offer(to);
onQueue[to] = true;
}
}
}
}
public double disTo(int v) {
return disTo[v];
}
public boolean hasPath(int v) {
return disTo[v] < Double.POSITIVE_INFINITY;
}
public Iterable pathTo(int v) {
if (!hasPath(v)) return null;
List path = new ArrayList<>();
for (DirectedEdge e = edgeTo[v]; e != null; e = edgeTo[e.getFrom()]) {
path.add(0, e);
}
return path;
}
} 这个算法在最坏情况下,时间复杂度也是O(VE),但是最坏情况下并不容易出现。
相对于Dijkstra算法来说,Bellman-Ford算法时间复杂度大得多,所以虽然Bellman-Ford算法通用,但是在没有负权重的时候,我们一定会采用Dijkstra算法的。
最后,因为Bellman-Ford算法中不能出现负权重的环,应该说负权重的环在最短路径问题中没有任意意义。因为我可以一直绕着负权重的环,来不断减小最短路径,所以最短路径没有意义。
我们在Bellman-Ford中应该判断一下是不是会出现负权重的环。
其实这点非常容易做到,因为我们记录了最短路径,这个最短路径一般来说是不会出现环的,只有在出现负权重环的时候,最短路径中才会出现环。所以我们仅仅需要判断一下最短路径中是不是有环就可以了,而不需要去计算每个环的权重和。
环的检测十分的容易,我们前几篇就提到过,只需要判断有向图中是否有环就可以了,使用深搜可以简单的实现这一点。
public class DirectedCycle { // 判断图是否有环
private boolean[] inStack;
private Stack cycle;
private Integer[] edgeTo;
private boolean[] isMarked;
public DirectedCycle(EdgeWeightDiGraph g) {
inStack = new boolean[g.V()];
edgeTo = new Integer[g.V()];
isMarked = new boolean[g.V()];
for (int i = 0; i < g.V(); i++) {
if (!isMarked[i]) {
dfs(g, i);
}
}
}
private void dfs(EdgeWeightDiGraph g, int begin) {
isMarked[begin] = true;
inStack[begin] = true;
for (DirectedEdge e : g.adj(begin)) {
Integer node = e.getTo();
if (hasCycle()) return;
if (!isMarked[node]) {
edgeTo[node] = begin;
dfs(g, node);
} else if (inStack[node]) { // 如果当前路径Stack中含有node,又再次访问的话,说明有环
// 将环保存下来
cycle = new Stack<>();
for (int i = begin; i != node; i = edgeTo[i]) {
cycle.push(i);
}
cycle.push(node);
cycle.push(begin);
}
}
inStack[begin] = false;
}
public boolean hasCycle() {
return cycle != null;
}
public Stack cycle() {
return cycle;
}
} 最终Bellman-Ford算法如下:
public class BellmanFordSP {
private Queue queue; // 需要被放松的顶点
private boolean[] onQueue; // 顶点是否在队列中
private DirectedEdge[] edgeTo;
private double[] disTo;
private List cycle;
private int cost;
public BellmanFordSP(EdgeWeightDiGraph g, int begin) {
queue = new LinkedList();
onQueue = new boolean[g.V()];
edgeTo = new DirectedEdge[g.V()];
disTo = new double[g.V()];
cost = 0;
for (int i = 0; i < g.V(); i++) {
disTo[i] = Double.POSITIVE_INFINITY;
}
disTo[begin] = 0;
onQueue[begin] = true;
queue.offer(begin);
while (!queue.isEmpty() && !hasNagetiveCycle()) {
Integer node = queue.poll();
onQueue[node] = false;
relax(g, node);
}
if (hasNagetiveCycle()) {
System.out.println("Nagetive cycle!!");
}
}
private void relax(EdgeWeightDiGraph g, int v) {
for (DirectedEdge e : g.adj(v)) {
int to = e.getTo();
if (disTo[to] > disTo[v] + e.weight()) {
disTo[to] = disTo[v] + e.weight();
edgeTo[to] = e;
if (!onQueue[to]) {
queue.offer(to);
onQueue[to] = true;
}
}
if (cost++ % g.V() == 0) {
findNagativeCycle();
}
}
}
public double disTo(int v) {
return disTo[v];
}
public boolean hasPath(int v) {
return disTo[v] < Double.POSITIVE_INFINITY;
}
public Iterable pathTo(int v) {
if (!hasPath(v)) return null;
List path = new ArrayList<>();
for (DirectedEdge e = edgeTo[v]; e != null; e = edgeTo[e.getFrom()]) {
path.add(0, e);
}
return path;
}
private void findNagativeCycle() {
EdgeWeightDiGraph tempG = new EdgeWeightDiGraph(edgeTo.length);
for (int i = 0; i < edgeTo.length; i++) {
DirectedEdge e = edgeTo[i];
if (e != null) {
tempG.addEdge(e);
}
}
DirectedCycle directedCycle = new DirectedCycle(tempG);
if (directedCycle.hasCycle()) {
for (Integer v : directedCycle.cycle()) {
cycle = new ArrayList<>();
cycle.add(edgeTo[v]);
}
}
}
public boolean hasNagetiveCycle() {
return cycle != null;
}
public Iterable nagetiveCycle() {
return cycle;
}
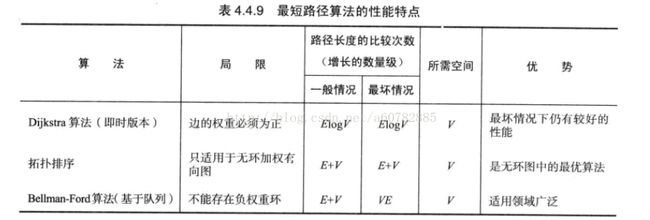
} 最后,汇总一下上面提到的最短路径算法的特点:
到这里算法就先放一下了,所有的练习代码都放在github中。