ElasticSearch父子关系查询
1 建表
PUT comppro
{
"mappings" : {
"member" : {},
"supply" : {
"_parent" : {
"type" : "member"
}
}
}
}
如果创建Parent-Child关系,需要先创建index和type。如果不先创建type,先导入数据的话,就不能再添加Parent-Child关系。
代码中,comppro为index
member为父type
supply为子type
1 数据导入
例子中使用spark想elasticSearch导入数据
package com.wk.comppro
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
import org.elasticsearch.spark._
object DataToES {
def main(args: Array[String]) {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val sqlContext = new HiveContext(sc)
import sqlContext.implicits._
val memberDF = sqlContext.sql("select * from report.comppro_tmp_member_full").repartition(1000)
val memberRDD = memberDF.map(row => {
val member_id = row.getAs[String]("member_id")
···
val from_ui = row.getAs[String]("from_ui")
(MemberBean(member_id, corporation_name, company_address, area_code, company_type, deal_in_id, business_supply, role_id, brokerage_type, label_label_type, label_status, member_add_time, link_man, email: String, mobile, telephone, from_ui))
})
memberRDD.saveToEs("comppro/member", Map("es.mapping.id" -> "member_id"))
val supplyDF = sqlContext.sql("select * from report.comppro_result").repartition(1000)
val supplyRDD = supplyDF.map(row => {
val pro_id = row.getAs[String]("pro_id")
···
val null_flag = row.getAs[Int]("null_flag")
(SupplyBean(pro_id, pro_name, promotion_price, pro_addtime, member_id, category_code, category_name, category_fullname), null_flag)
})
supplyRDD.filter(_._2 == 1).map(_._1).saveToEs("comppro/supply", Map("es.mapping.id" -> "pro_id", "es.mapping.parent" -> "member_id"))
}
case class SupplyBean(pro_id: String, pro_name: String, promotion_price: Double, pro_addtime: String, member_id: String, category_code: String, category_name: String, category_fullname: String)
case class MemberBean(member_id: String, corporation_name: String, company_address: String, area_code: String, company_type: String, deal_in_id: String, business_supply: String, role_id: Int, brokerage_type: String, label_label_type: String, label_status: String, member_add_time: String, link_man: String, email: String, mobile: String, telephone: String, from_ui: String)
}
往父表导数据的时候只需指定index/type和主键id
memberRDD.saveToEs("comppro/member",Map("es.mapping.id" -> "member_id")
往子表导数据的时候需要额外指定父id
supplyRDD.filter(_._2 ==1).map(_._1).saveToEs("comppro/supply", Map("es.mapping.id"-> "pro_id", "es.mapping.parent" ->"member_id"))
提交脚本:
spark-submit --master yarn --deploy-modecluster --class com.wk.comppro.DataToES --conf spark.es.nodes=192.16.3.147 --jars./lib/elasticsearch-spark-13_2.10-5.3.1.jar --executor-cores 2--executor-memory 3g --driver-memory 4g --num-executors 20 comppro.jar
我在提交脚本中指定的es地址spark.es.nodes=192.16.3.147
3 查询
3.1 Parent-Child关联查询
GET /comppro/member/_search
{
"from" : 0, "size" : 10,
"query": {
"has_child": {
"type": "supply",
"query": {
"range": {
"pro_addtime": {
"gte": "2012-01-01"
}
}
},
"inner_hits" : {"size" : 0 }
}
}
}
结果:
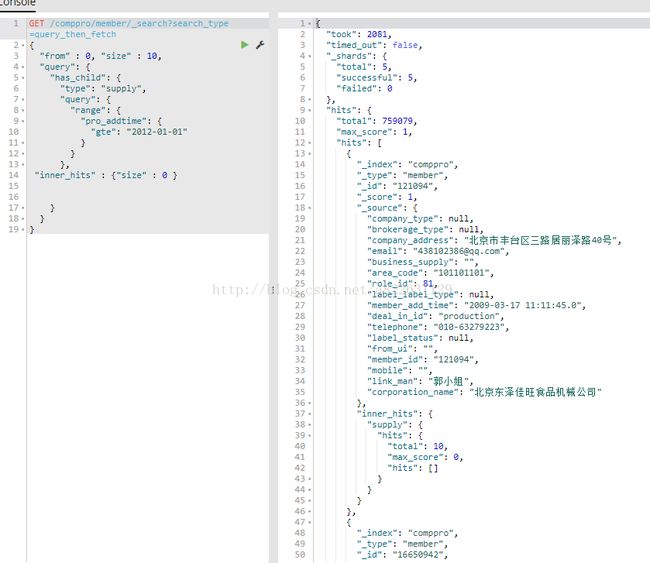
性能:
supply表:1664万
member表865万
关联查询:获取需要2081ms
3.2 通过Child查询Parent

查询只需要675ms
3.3 通过Parent查询Child

查询需要720ms
3.4 Parent Children 聚合
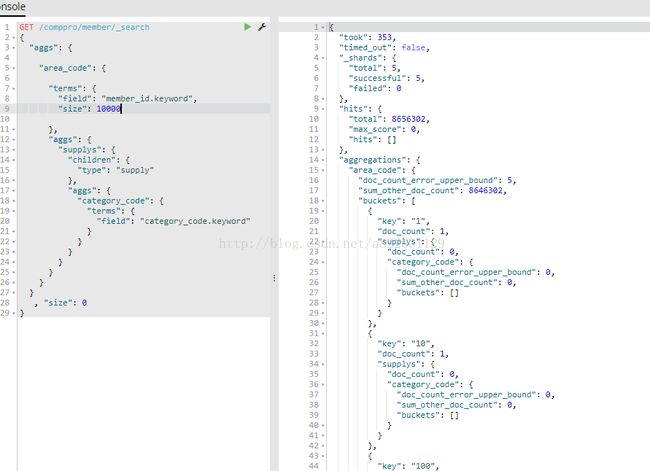
根据Parent的member_id字段和Child的category_code字段进行聚合,由于es aggs操作不能使用from进行分页,取了Parent 10000条记录,用时352ms
GET /comppro/member/_search
{
"aggs": {
"area_code": {
"terms": {
"field": "member_id.keyword",
"size": 100000
},
"aggs": {
"supplys": {
"children": {
"type": "supply"
},
"aggs": {
"category_code": {
"terms": {
"field": "category_code.keyword"
}
}
}
}
}
}
}
, "size": 0
}
取10万条记录,用时3428ms