Tensorflow学习笔记(第三天)—卷积神经网络
对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组大小为32x32的RGB图像进行分类,这些图像涵盖了10个类别:
飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。
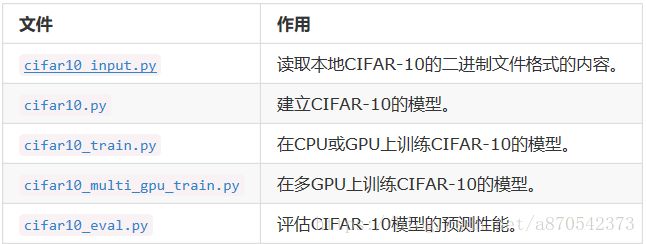
一、cifar10.py代码:

# Copyright 2015 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Builds the CIFAR-10 network.
Summary of available functions:
# Compute input images and labels for training. If you would like to run
# evaluations, use input() instead.
inputs, labels = distorted_inputs()
# Compute inference on the model inputs to make a prediction.
predictions = inference(inputs)
# Compute the total loss of the prediction with respect to the labels.
loss = loss(predictions, labels)
# Create a graph to run one step of training with respect to the loss.
train_op = train(loss, global_step)
"""
# pylint: disable=missing-docstring
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import re
import sys
import tarfile
import tensorflow.python.platform
from six.moves import urllib
import tensorflow as tf
import cifar10_input
FLAGS = tf.app.flags.FLAGS
# Basic model parameters.
tf.app.flags.DEFINE_integer('batch_size', 128,
"""Number of images to process in a batch.""")
tf.app.flags.DEFINE_string('data_dir', '/tmp/cifar10_data',
"""Path to the CIFAR-10 data directory.""")
# Global constants describing the CIFAR-10 data set.
IMAGE_SIZE = cifar10_input.IMAGE_SIZE
NUM_CLASSES = cifar10_input.NUM_CLASSES
NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN = cifar10_input.NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
NUM_EXAMPLES_PER_EPOCH_FOR_EVAL = cifar10_input.NUM_EXAMPLES_PER_EPOCH_FOR_EVAL
# Constants describing the training process.
MOVING_AVERAGE_DECAY = 0.9999 # The decay to use for the moving average.
NUM_EPOCHS_PER_DECAY = 350.0 # Epochs after which learning rate decays.
LEARNING_RATE_DECAY_FACTOR = 0.1 # Learning rate decay factor.
INITIAL_LEARNING_RATE = 0.1 # Initial learning rate.
# If a model is trained with multiple GPU's prefix all Op names with tower_name
# to differentiate the operations. Note that this prefix is removed from the
# names of the summaries when visualizing a model.
TOWER_NAME = 'tower'
DATA_URL = 'http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz'
def _activation_summary(x):
"""Helper to create summaries for activations.
Creates a summary that provides a histogram of activations.
Creates a summary that measure the sparsity of activations.
Args:
x: Tensor
Returns:
nothing
"""
# Remove 'tower_[0-9]/' from the name in case this is a multi-GPU training
# session. This helps the clarity of presentation on tensorboard.
tensor_name = re.sub('%s_[0-9]*/' % TOWER_NAME, '', x.op.name)
tf.summary.histogram(tensor_name + '/activations', x)
tf.summary.scalar(tensor_name + '/sparsity', tf.nn.zero_fraction(x))
def _variable_on_cpu(name, shape, initializer):
"""Helper to create a Variable stored on CPU memory.
Args:
name: name of the variable
shape: list of ints
initializer: initializer for Variable
Returns:
Variable Tensor
"""
with tf.device('/cpu:0'):
var = tf.get_variable(name, shape, initializer=initializer)
return var
def _variable_with_weight_decay(name, shape, stddev, wd):
"""Helper to create an initialized Variable with weight decay.
Note that the Variable is initialized with a truncated normal distribution.
A weight decay is added only if one is specified.
Args:
name: name of the variable
shape: list of ints
stddev: standard deviation of a truncated Gaussian
wd: add L2Loss weight decay multiplied by this float. If None, weight
decay is not added for this Variable.
Returns:
Variable Tensor
"""
var = _variable_on_cpu(name, shape,
tf.truncated_normal_initializer(stddev=stddev))
if wd:
weight_decay = tf.multiply(tf.nn.l2_loss(var), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
return var
def distorted_inputs():
"""Construct distorted input for CIFAR training using the Reader ops.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
Raises:
ValueError: If no data_dir
"""
if not FLAGS.data_dir:
raise ValueError('Please supply a data_dir')
data_dir = os.path.join(FLAGS.data_dir, 'cifar-10-batches-bin')
return cifar10_input.distorted_inputs(data_dir=data_dir,
batch_size=FLAGS.batch_size)
def inputs(eval_data):
"""Construct input for CIFAR evaluation using the Reader ops.
Args:
eval_data: bool, indicating if one should use the train or eval data set.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
Raises:
ValueError: If no data_dir
"""
if not FLAGS.data_dir:
raise ValueError('Please supply a data_dir')
data_dir = os.path.join(FLAGS.data_dir, 'cifar-10-batches-bin')
return cifar10_input.inputs(eval_data=eval_data, data_dir=data_dir,
batch_size=FLAGS.batch_size)
def inference(images):
"""Build the CIFAR-10 model.
Args:
images: Images returned from distorted_inputs() or inputs().
Returns:
Logits.
"""
# We instantiate all variables using tf.get_variable() instead of
# tf.Variable() in order to share variables across multiple GPU training runs.
# If we only ran this model on a single GPU, we could simplify this function
# by replacing all instances of tf.get_variable() with tf.Variable().
#
# conv1
with tf.variable_scope('conv1') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 3, 64],
stddev=1e-4, wd=0.0)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope.name)
_activation_summary(conv1)
# pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool1')
# norm1
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm1')
# conv2
with tf.variable_scope('conv2') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 64, 64],
stddev=1e-4, wd=0.0)
conv = tf.nn.conv2d(norm1, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.1))
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope.name)
_activation_summary(conv2)
# norm2
norm2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm2')
# pool2
pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME', name='pool2')
# local3
with tf.variable_scope('local3') as scope:
# Move everything into depth so we can perform a single matrix multiply.
dim = 1
for d in pool2.get_shape()[1:].as_list():
dim *= d
reshape = tf.reshape(pool2, [FLAGS.batch_size, dim])
weights = _variable_with_weight_decay('weights', shape=[dim, 384],
stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [384], tf.constant_initializer(0.1))
local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name)
_activation_summary(local3)
# local4
with tf.variable_scope('local4') as scope:
weights = _variable_with_weight_decay('weights', shape=[384, 192],
stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [192], tf.constant_initializer(0.1))
local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name=scope.name)
_activation_summary(local4)
# softmax, i.e. softmax(WX + b)
with tf.variable_scope('softmax_linear') as scope:
weights = _variable_with_weight_decay('weights', [192, NUM_CLASSES],
stddev=1/192.0, wd=0.0)
biases = _variable_on_cpu('biases', [NUM_CLASSES],
tf.constant_initializer(0.0))
softmax_linear = tf.add(tf.matmul(local4, weights), biases, name=scope.name)
_activation_summary(softmax_linear)
return softmax_linear
def loss(logits, labels):
"""Add L2Loss to all the trainable variables.
Add summary for for "Loss" and "Loss/avg".
Args:
logits: Logits from inference().
labels: Labels from distorted_inputs or inputs(). 1-D tensor
of shape [batch_size]
Returns:
Loss tensor of type float.
"""
# Reshape the labels into a dense Tensor of
# shape [batch_size, NUM_CLASSES].
sparse_labels = tf.reshape(labels, [FLAGS.batch_size, 1])
indices = tf.reshape(tf.range(FLAGS.batch_size), [FLAGS.batch_size, 1])
concated = tf.concat([indices, sparse_labels], 1)
dense_labels = tf.sparse_to_dense(concated,
[FLAGS.batch_size, NUM_CLASSES],
1.0, 0.0)
# Calculate the average cross entropy loss across the batch.
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = dense_labels, name='cross_entropy_per_example')
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
# The total loss is defined as the cross entropy loss plus all of the weight
# decay terms (L2 loss).
return tf.add_n(tf.get_collection('losses'), name='total_loss')
def _add_loss_summaries(total_loss):
"""Add summaries for losses in CIFAR-10 model.
Generates moving average for all losses and associated summaries for
visualizing the performance of the network.
Args:
total_loss: Total loss from loss().
Returns:
loss_averages_op: op for generating moving averages of losses.
"""
# Compute the moving average of all individual losses and the total loss.
loss_averages = tf.train.ExponentialMovingAverage(0.9, name='avg')
losses = tf.get_collection('losses')
loss_averages_op = loss_averages.apply(losses + [total_loss])
# Attach a scalar summary to all individual losses and the total loss; do the
# same for the averaged version of the losses.
for l in losses + [total_loss]:
# Name each loss as '(raw)' and name the moving average version of the loss
# as the original loss name.
tf.summary.scalar(l.op.name +' (raw)', l)
tf.summary.scalar(l.op.name, loss_averages.average(l))
return loss_averages_op
def train(total_loss, global_step):
"""Train CIFAR-10 model.
Create an optimizer and apply to all trainable variables. Add moving
average for all trainable variables.
Args:
total_loss: Total loss from loss().
global_step: Integer Variable counting the number of training steps
processed.
Returns:
train_op: op for training.
"""
# Variables that affect learning rate.
num_batches_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN / FLAGS.batch_size
decay_steps = int(num_batches_per_epoch * NUM_EPOCHS_PER_DECAY)
# Decay the learning rate exponentially based on the number of steps.
lr = tf.train.exponential_decay(INITIAL_LEARNING_RATE,
global_step,
decay_steps,
LEARNING_RATE_DECAY_FACTOR,
staircase=True)
tf.summary.scalar('learning_rate', lr)
# Generate moving averages of all losses and associated summaries.
loss_averages_op = _add_loss_summaries(total_loss)
# Compute gradients.
with tf.control_dependencies([loss_averages_op]):
opt = tf.train.GradientDescentOptimizer(lr)
grads = opt.compute_gradients(total_loss)
# Apply gradients.
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
# Add histograms for trainable variables.
for var in tf.trainable_variables():
tf.summary.histogram(var.op.name, var)
# Add histograms for gradients.
for grad, var in grads:
if grad is not None:
tf.summary.histogram(var.op.name + '/gradients', grad)
# Track the moving averages of all trainable variables.
variable_averages = tf.train.ExponentialMovingAverage(
MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([apply_gradient_op, variables_averages_op]):
train_op = tf.no_op(name='train')
return train_op
def maybe_download_and_extract():
"""Download and extract the tarball from Alex's website."""
dest_directory = FLAGS.data_dir
if not os.path.exists(dest_directory):
os.makedirs(dest_directory)
filename = DATA_URL.split('/')[-1]
filepath = os.path.join(dest_directory, filename)
if not os.path.exists(filepath):
def _progress(count, block_size, total_size):
sys.stdout.write('\r>> Downloading %s %.1f%%' % (filename,
float(count * block_size) / float(total_size) * 100.0))
sys.stdout.flush()
filepath, _ = urllib.request.urlretrieve(DATA_URL, filepath,
reporthook=_progress)
print()
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
tarfile.open(filepath, 'r:gz').extractall(dest_directory)
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Builds the CIFAR-10 network.
Summary of available functions:
# Compute input images and labels for training. If you would like to run
# evaluations, use input() instead.
inputs, labels = distorted_inputs()
# Compute inference on the model inputs to make a prediction.
predictions = inference(inputs)
# Compute the total loss of the prediction with respect to the labels.
loss = loss(predictions, labels)
# Create a graph to run one step of training with respect to the loss.
train_op = train(loss, global_step)
"""
# pylint: disable=missing-docstring
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import re
import sys
import tarfile
import tensorflow.python.platform
from six.moves import urllib
import tensorflow as tf
import cifar10_input
FLAGS = tf.app.flags.FLAGS
# Basic model parameters.
tf.app.flags.DEFINE_integer('batch_size', 128,
"""Number of images to process in a batch.""")
tf.app.flags.DEFINE_string('data_dir', '/tmp/cifar10_data',
"""Path to the CIFAR-10 data directory.""")
# Global constants describing the CIFAR-10 data set.
IMAGE_SIZE = cifar10_input.IMAGE_SIZE
NUM_CLASSES = cifar10_input.NUM_CLASSES
NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN = cifar10_input.NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN
NUM_EXAMPLES_PER_EPOCH_FOR_EVAL = cifar10_input.NUM_EXAMPLES_PER_EPOCH_FOR_EVAL
# Constants describing the training process.
MOVING_AVERAGE_DECAY = 0.9999 # The decay to use for the moving average.
NUM_EPOCHS_PER_DECAY = 350.0 # Epochs after which learning rate decays.
LEARNING_RATE_DECAY_FACTOR = 0.1 # Learning rate decay factor.
INITIAL_LEARNING_RATE = 0.1 # Initial learning rate.
# If a model is trained with multiple GPU's prefix all Op names with tower_name
# to differentiate the operations. Note that this prefix is removed from the
# names of the summaries when visualizing a model.
TOWER_NAME = 'tower'
DATA_URL = 'http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz'
def _activation_summary(x):
"""Helper to create summaries for activations.
Creates a summary that provides a histogram of activations.
Creates a summary that measure the sparsity of activations.
Args:
x: Tensor
Returns:
nothing
"""
# Remove 'tower_[0-9]/' from the name in case this is a multi-GPU training
# session. This helps the clarity of presentation on tensorboard.
tensor_name = re.sub('%s_[0-9]*/' % TOWER_NAME, '', x.op.name)
tf.summary.histogram(tensor_name + '/activations', x)
tf.summary.scalar(tensor_name + '/sparsity', tf.nn.zero_fraction(x))
def _variable_on_cpu(name, shape, initializer):
"""Helper to create a Variable stored on CPU memory.
Args:
name: name of the variable
shape: list of ints
initializer: initializer for Variable
Returns:
Variable Tensor
"""
with tf.device('/cpu:0'):
var = tf.get_variable(name, shape, initializer=initializer)
return var
def _variable_with_weight_decay(name, shape, stddev, wd):
"""Helper to create an initialized Variable with weight decay.
Note that the Variable is initialized with a truncated normal distribution.
A weight decay is added only if one is specified.
Args:
name: name of the variable
shape: list of ints
stddev: standard deviation of a truncated Gaussian
wd: add L2Loss weight decay multiplied by this float. If None, weight
decay is not added for this Variable.
Returns:
Variable Tensor
"""
var = _variable_on_cpu(name, shape,
tf.truncated_normal_initializer(stddev=stddev))
if wd:
weight_decay = tf.multiply(tf.nn.l2_loss(var), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
return var
def distorted_inputs():
"""Construct distorted input for CIFAR training using the Reader ops.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
Raises:
ValueError: If no data_dir
"""
if not FLAGS.data_dir:
raise ValueError('Please supply a data_dir')
data_dir = os.path.join(FLAGS.data_dir, 'cifar-10-batches-bin')
return cifar10_input.distorted_inputs(data_dir=data_dir,
batch_size=FLAGS.batch_size)
def inputs(eval_data):
"""Construct input for CIFAR evaluation using the Reader ops.
Args:
eval_data: bool, indicating if one should use the train or eval data set.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
Raises:
ValueError: If no data_dir
"""
if not FLAGS.data_dir:
raise ValueError('Please supply a data_dir')
data_dir = os.path.join(FLAGS.data_dir, 'cifar-10-batches-bin')
return cifar10_input.inputs(eval_data=eval_data, data_dir=data_dir,
batch_size=FLAGS.batch_size)
def inference(images):
"""Build the CIFAR-10 model.
Args:
images: Images returned from distorted_inputs() or inputs().
Returns:
Logits.
"""
# We instantiate all variables using tf.get_variable() instead of
# tf.Variable() in order to share variables across multiple GPU training runs.
# If we only ran this model on a single GPU, we could simplify this function
# by replacing all instances of tf.get_variable() with tf.Variable().
#
# conv1
with tf.variable_scope('conv1') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 3, 64],
stddev=1e-4, wd=0.0)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope.name)
_activation_summary(conv1)
# pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool1')
# norm1
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm1')
# conv2
with tf.variable_scope('conv2') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 64, 64],
stddev=1e-4, wd=0.0)
conv = tf.nn.conv2d(norm1, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.1))
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope.name)
_activation_summary(conv2)
# norm2
norm2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm2')
# pool2
pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME', name='pool2')
# local3
with tf.variable_scope('local3') as scope:
# Move everything into depth so we can perform a single matrix multiply.
dim = 1
for d in pool2.get_shape()[1:].as_list():
dim *= d
reshape = tf.reshape(pool2, [FLAGS.batch_size, dim])
weights = _variable_with_weight_decay('weights', shape=[dim, 384],
stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [384], tf.constant_initializer(0.1))
local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name)
_activation_summary(local3)
# local4
with tf.variable_scope('local4') as scope:
weights = _variable_with_weight_decay('weights', shape=[384, 192],
stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [192], tf.constant_initializer(0.1))
local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name=scope.name)
_activation_summary(local4)
# softmax, i.e. softmax(WX + b)
with tf.variable_scope('softmax_linear') as scope:
weights = _variable_with_weight_decay('weights', [192, NUM_CLASSES],
stddev=1/192.0, wd=0.0)
biases = _variable_on_cpu('biases', [NUM_CLASSES],
tf.constant_initializer(0.0))
softmax_linear = tf.add(tf.matmul(local4, weights), biases, name=scope.name)
_activation_summary(softmax_linear)
return softmax_linear
def loss(logits, labels):
"""Add L2Loss to all the trainable variables.
Add summary for for "Loss" and "Loss/avg".
Args:
logits: Logits from inference().
labels: Labels from distorted_inputs or inputs(). 1-D tensor
of shape [batch_size]
Returns:
Loss tensor of type float.
"""
# Reshape the labels into a dense Tensor of
# shape [batch_size, NUM_CLASSES].
sparse_labels = tf.reshape(labels, [FLAGS.batch_size, 1])
indices = tf.reshape(tf.range(FLAGS.batch_size), [FLAGS.batch_size, 1])
concated = tf.concat([indices, sparse_labels], 1)
dense_labels = tf.sparse_to_dense(concated,
[FLAGS.batch_size, NUM_CLASSES],
1.0, 0.0)
# Calculate the average cross entropy loss across the batch.
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = dense_labels, name='cross_entropy_per_example')
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
# The total loss is defined as the cross entropy loss plus all of the weight
# decay terms (L2 loss).
return tf.add_n(tf.get_collection('losses'), name='total_loss')
def _add_loss_summaries(total_loss):
"""Add summaries for losses in CIFAR-10 model.
Generates moving average for all losses and associated summaries for
visualizing the performance of the network.
Args:
total_loss: Total loss from loss().
Returns:
loss_averages_op: op for generating moving averages of losses.
"""
# Compute the moving average of all individual losses and the total loss.
loss_averages = tf.train.ExponentialMovingAverage(0.9, name='avg')
losses = tf.get_collection('losses')
loss_averages_op = loss_averages.apply(losses + [total_loss])
# Attach a scalar summary to all individual losses and the total loss; do the
# same for the averaged version of the losses.
for l in losses + [total_loss]:
# Name each loss as '(raw)' and name the moving average version of the loss
# as the original loss name.
tf.summary.scalar(l.op.name +' (raw)', l)
tf.summary.scalar(l.op.name, loss_averages.average(l))
return loss_averages_op
def train(total_loss, global_step):
"""Train CIFAR-10 model.
Create an optimizer and apply to all trainable variables. Add moving
average for all trainable variables.
Args:
total_loss: Total loss from loss().
global_step: Integer Variable counting the number of training steps
processed.
Returns:
train_op: op for training.
"""
# Variables that affect learning rate.
num_batches_per_epoch = NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN / FLAGS.batch_size
decay_steps = int(num_batches_per_epoch * NUM_EPOCHS_PER_DECAY)
# Decay the learning rate exponentially based on the number of steps.
lr = tf.train.exponential_decay(INITIAL_LEARNING_RATE,
global_step,
decay_steps,
LEARNING_RATE_DECAY_FACTOR,
staircase=True)
tf.summary.scalar('learning_rate', lr)
# Generate moving averages of all losses and associated summaries.
loss_averages_op = _add_loss_summaries(total_loss)
# Compute gradients.
with tf.control_dependencies([loss_averages_op]):
opt = tf.train.GradientDescentOptimizer(lr)
grads = opt.compute_gradients(total_loss)
# Apply gradients.
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
# Add histograms for trainable variables.
for var in tf.trainable_variables():
tf.summary.histogram(var.op.name, var)
# Add histograms for gradients.
for grad, var in grads:
if grad is not None:
tf.summary.histogram(var.op.name + '/gradients', grad)
# Track the moving averages of all trainable variables.
variable_averages = tf.train.ExponentialMovingAverage(
MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([apply_gradient_op, variables_averages_op]):
train_op = tf.no_op(name='train')
return train_op
def maybe_download_and_extract():
"""Download and extract the tarball from Alex's website."""
dest_directory = FLAGS.data_dir
if not os.path.exists(dest_directory):
os.makedirs(dest_directory)
filename = DATA_URL.split('/')[-1]
filepath = os.path.join(dest_directory, filename)
if not os.path.exists(filepath):
def _progress(count, block_size, total_size):
sys.stdout.write('\r>> Downloading %s %.1f%%' % (filename,
float(count * block_size) / float(total_size) * 100.0))
sys.stdout.flush()
filepath, _ = urllib.request.urlretrieve(DATA_URL, filepath,
reporthook=_progress)
print()
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
tarfile.open(filepath, 'r:gz').extractall(dest_directory)
二、
执行并训练模型
cifar10_train.py代码:
# Copyright 2015 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""A binary to train CIFAR-10 using a single GPU.
Accuracy:
cifar10_train.py achieves ~86% accuracy after 100K steps (256 epochs of
data) as judged by cifar10_eval.py.
Speed: With batch_size 128.
System | Step Time (sec/batch) | Accuracy
------------------------------------------------------------------
1 Tesla K20m | 0.35-0.60 | ~86% at 60K steps (5 hours)
1 Tesla K40m | 0.25-0.35 | ~86% at 100K steps (4 hours)
Usage:
Please see the tutorial and website for how to download the CIFAR-10
data set, compile the program and train the model.
http://tensorflow.org/tutorials/deep_cnn/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from datetime import datetime
import os.path
import time
import tensorflow.python.platform
from tensorflow.python.platform import gfile
import numpy as np
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
import cifar10
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('train_dir', '/tmp/cifar10_train',
"""Directory where to write event logs """
"""and checkpoint.""")
tf.app.flags.DEFINE_integer('max_steps', 1000000,
"""Number of batches to run.""")
tf.app.flags.DEFINE_boolean('log_device_placement', False,
"""Whether to log device placement.""")
def train():
"""Train CIFAR-10 for a number of steps."""
with tf.Graph().as_default():
global_step = tf.Variable(0, trainable=False)
# Get images and labels for CIFAR-10.
images, labels = cifar10.distorted_inputs()
# Build a Graph that computes the logits predictions from the
# inference model.
logits = cifar10.inference(images)
# Calculate loss.
loss = cifar10.loss(logits, labels)
# Build a Graph that trains the model with one batch of examples and
# updates the model parameters.
train_op = cifar10.train(loss, global_step)
# Create a saver.
saver = tf.train.Saver(tf.global_variables())
# Build the summary operation based on the TF collection of Summaries.
summary_op = tf.summary.merge_all()
# Build an initialization operation to run below.
init = tf.initialize_all_variables()
# Start running operations on the Graph.
sess = tf.Session(config=tf.ConfigProto(
log_device_placement=FLAGS.log_device_placement))
sess.run(init)
# Start the queue runners.
tf.train.start_queue_runners(sess=sess)
summary_writer = tf.summary.FileWriter(FLAGS.train_dir,
graph_def=sess.graph_def)
for step in xrange(FLAGS.max_steps):
start_time = time.time()
_, loss_value = sess.run([train_op, loss])
duration = time.time() - start_time
assert not np.isnan(loss_value), 'Model diverged with loss = NaN'
if step % 10 == 0:
num_examples_per_step = FLAGS.batch_size
examples_per_sec = num_examples_per_step / duration
sec_per_batch = float(duration)
format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
'sec/batch)')
print (format_str % (datetime.now(), step, loss_value,
examples_per_sec, sec_per_batch))
if step % 100 == 0:
summary_str = sess.run(summary_op)
summary_writer.add_summary(summary_str, step)
# Save the model checkpoint periodically.
if step % 1000 == 0 or (step + 1) == FLAGS.max_steps:
checkpoint_path = os.path.join(FLAGS.train_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step=step)
def main(argv=None): # pylint: disable=unused-argument
cifar10.maybe_download_and_extract()
if gfile.Exists(FLAGS.train_dir):
gfile.DeleteRecursively(FLAGS.train_dir)
gfile.MakeDirs(FLAGS.train_dir)
train()
if __name__ == '__main__':
tf.app.run()
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""A binary to train CIFAR-10 using a single GPU.
Accuracy:
cifar10_train.py achieves ~86% accuracy after 100K steps (256 epochs of
data) as judged by cifar10_eval.py.
Speed: With batch_size 128.
System | Step Time (sec/batch) | Accuracy
------------------------------------------------------------------
1 Tesla K20m | 0.35-0.60 | ~86% at 60K steps (5 hours)
1 Tesla K40m | 0.25-0.35 | ~86% at 100K steps (4 hours)
Usage:
Please see the tutorial and website for how to download the CIFAR-10
data set, compile the program and train the model.
http://tensorflow.org/tutorials/deep_cnn/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from datetime import datetime
import os.path
import time
import tensorflow.python.platform
from tensorflow.python.platform import gfile
import numpy as np
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
import cifar10
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('train_dir', '/tmp/cifar10_train',
"""Directory where to write event logs """
"""and checkpoint.""")
tf.app.flags.DEFINE_integer('max_steps', 1000000,
"""Number of batches to run.""")
tf.app.flags.DEFINE_boolean('log_device_placement', False,
"""Whether to log device placement.""")
def train():
"""Train CIFAR-10 for a number of steps."""
with tf.Graph().as_default():
global_step = tf.Variable(0, trainable=False)
# Get images and labels for CIFAR-10.
images, labels = cifar10.distorted_inputs()
# Build a Graph that computes the logits predictions from the
# inference model.
logits = cifar10.inference(images)
# Calculate loss.
loss = cifar10.loss(logits, labels)
# Build a Graph that trains the model with one batch of examples and
# updates the model parameters.
train_op = cifar10.train(loss, global_step)
# Create a saver.
saver = tf.train.Saver(tf.global_variables())
# Build the summary operation based on the TF collection of Summaries.
summary_op = tf.summary.merge_all()
# Build an initialization operation to run below.
init = tf.initialize_all_variables()
# Start running operations on the Graph.
sess = tf.Session(config=tf.ConfigProto(
log_device_placement=FLAGS.log_device_placement))
sess.run(init)
# Start the queue runners.
tf.train.start_queue_runners(sess=sess)
summary_writer = tf.summary.FileWriter(FLAGS.train_dir,
graph_def=sess.graph_def)
for step in xrange(FLAGS.max_steps):
start_time = time.time()
_, loss_value = sess.run([train_op, loss])
duration = time.time() - start_time
assert not np.isnan(loss_value), 'Model diverged with loss = NaN'
if step % 10 == 0:
num_examples_per_step = FLAGS.batch_size
examples_per_sec = num_examples_per_step / duration
sec_per_batch = float(duration)
format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
'sec/batch)')
print (format_str % (datetime.now(), step, loss_value,
examples_per_sec, sec_per_batch))
if step % 100 == 0:
summary_str = sess.run(summary_op)
summary_writer.add_summary(summary_str, step)
# Save the model checkpoint periodically.
if step % 1000 == 0 or (step + 1) == FLAGS.max_steps:
checkpoint_path = os.path.join(FLAGS.train_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step=step)
def main(argv=None): # pylint: disable=unused-argument
cifar10.maybe_download_and_extract()
if gfile.Exists(FLAGS.train_dir):
gfile.DeleteRecursively(FLAGS.train_dir)
gfile.MakeDirs(FLAGS.train_dir)
train()
if __name__ == '__main__':
tf.app.run()
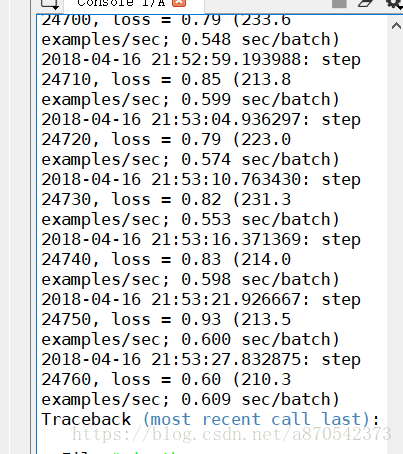
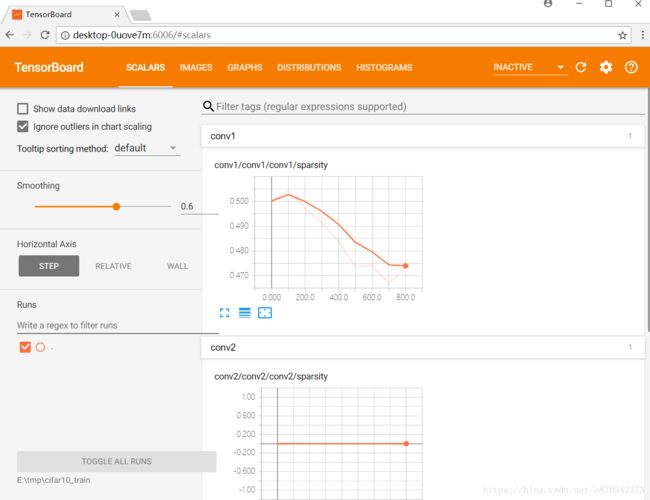
三
、使用tensorboard
1.键入命令行,启动TensorBoard
输入tensorboard --logdir=E:\tmp\cifar10_train
这个后面的地址是这个函数的地址
tf.app.flags.DEFINE_string('train_dir', '/tmp/cifar10_train',
"""Directory where to write event logs """
"""and checkpoint.""")
之后得到这个地址在浏览器中打开。最好是使用谷歌浏览器
四、评估模型
cifar10_eval.py代码:# Copyright 2015 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Evaluation for CIFAR-10.
Accuracy:
cifar10_train.py achieves 83.0% accuracy after 100K steps (256 epochs
of data) as judged by cifar10_eval.py.
Speed:
On a single Tesla K40, cifar10_train.py processes a single batch of 128 images
in 0.25-0.35 sec (i.e. 350 - 600 images /sec). The model reaches ~86%
accuracy after 100K steps in 8 hours of training time.
Usage:
Please see the tutorial and website for how to download the CIFAR-10
data set, compile the program and train the model.
http://tensorflow.org/tutorials/deep_cnn/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from datetime import datetime
import math
import time
import tensorflow.python.platform
from tensorflow.python.platform import gfile
import numpy as np
import tensorflow as tf
import cifar10
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('eval_dir', '/tmp/cifar10_eval',
"""Directory where to write event logs.""")
tf.app.flags.DEFINE_string('eval_data', 'test',
"""Either 'test' or 'train_eval'.""")
tf.app.flags.DEFINE_string('checkpoint_dir', '/tmp/cifar10_train',
"""Directory where to read model checkpoints.""")
tf.app.flags.DEFINE_integer('eval_interval_secs', 60 * 5,
"""How often to run the eval.""")
tf.app.flags.DEFINE_integer('num_examples', 10000,
"""Number of examples to run.""")
tf.app.flags.DEFINE_boolean('run_once', False,
"""Whether to run eval only once.""")
def eval_once(saver, summary_writer, top_k_op, summary_op):
"""Run Eval once.
Args:
saver: Saver.
summary_writer: Summary writer.
top_k_op: Top K op.
summary_op: Summary op.
"""
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(FLAGS.checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
# Restores from checkpoint
saver.restore(sess, ckpt.model_checkpoint_path)
# Assuming model_checkpoint_path looks something like:
# /my-favorite-path/cifar10_train/model.ckpt-0,
# extract global_step from it.
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
else:
print('No checkpoint file found')
return
# Start the queue runners.
coord = tf.train.Coordinator()
try:
threads = []
for qr in tf.get_collection(tf.GraphKeys.QUEUE_RUNNERS):
threads.extend(qr.create_threads(sess, coord=coord, daemon=True,
start=True))
num_iter = int(math.ceil(FLAGS.num_examples / FLAGS.batch_size))
true_count = 0 # Counts the number of correct predictions.
total_sample_count = num_iter * FLAGS.batch_size
step = 0
while step < num_iter and not coord.should_stop():
predictions = sess.run([top_k_op])
true_count += np.sum(predictions)
step += 1
# Compute precision @ 1.
precision = true_count / total_sample_count
print('%s: precision @ 1 = %.3f' % (datetime.now(), precision))
summary = tf.Summary()
summary.ParseFromString(sess.run(summary_op))
summary.value.add(tag='Precision @ 1', simple_value=precision)
summary_writer.add_summary(summary, global_step)
except Exception as e: # pylint: disable=broad-except
coord.request_stop(e)
coord.request_stop()
coord.join(threads, stop_grace_period_secs=10)
def evaluate():
"""Eval CIFAR-10 for a number of steps."""
with tf.Graph().as_default():
# Get images and labels for CIFAR-10.
eval_data = FLAGS.eval_data == 'test'
images, labels = cifar10.inputs(eval_data=eval_data)
# Build a Graph that computes the logits predictions from the
# inference model.
logits = cifar10.inference(images)
# Calculate predictions.
top_k_op = tf.nn.in_top_k(logits, labels, 1)
# Restore the moving average version of the learned variables for eval.
variable_averages = tf.train.ExponentialMovingAverage(
cifar10.MOVING_AVERAGE_DECAY)
variables_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
# Build the summary operation based on the TF collection of Summaries.
summary_op = tf.summary.merge_all()
graph_def = tf.get_default_graph().as_graph_def()
summary_writer = tf.summary.FileWriter(FLAGS.eval_dir,
graph_def=graph_def)
while True:
eval_once(saver, summary_writer, top_k_op, summary_op)
if FLAGS.run_once:
break
time.sleep(FLAGS.eval_interval_secs)
def main(argv=None): # pylint: disable=unused-argument
cifar10.maybe_download_and_extract()
if gfile.Exists(FLAGS.eval_dir):
gfile.DeleteRecursively(FLAGS.eval_dir)
gfile.MakeDirs(FLAGS.eval_dir)
evaluate()
if __name__ == '__main__':
tf.app.run()
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Evaluation for CIFAR-10.
Accuracy:
cifar10_train.py achieves 83.0% accuracy after 100K steps (256 epochs
of data) as judged by cifar10_eval.py.
Speed:
On a single Tesla K40, cifar10_train.py processes a single batch of 128 images
in 0.25-0.35 sec (i.e. 350 - 600 images /sec). The model reaches ~86%
accuracy after 100K steps in 8 hours of training time.
Usage:
Please see the tutorial and website for how to download the CIFAR-10
data set, compile the program and train the model.
http://tensorflow.org/tutorials/deep_cnn/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from datetime import datetime
import math
import time
import tensorflow.python.platform
from tensorflow.python.platform import gfile
import numpy as np
import tensorflow as tf
import cifar10
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('eval_dir', '/tmp/cifar10_eval',
"""Directory where to write event logs.""")
tf.app.flags.DEFINE_string('eval_data', 'test',
"""Either 'test' or 'train_eval'.""")
tf.app.flags.DEFINE_string('checkpoint_dir', '/tmp/cifar10_train',
"""Directory where to read model checkpoints.""")
tf.app.flags.DEFINE_integer('eval_interval_secs', 60 * 5,
"""How often to run the eval.""")
tf.app.flags.DEFINE_integer('num_examples', 10000,
"""Number of examples to run.""")
tf.app.flags.DEFINE_boolean('run_once', False,
"""Whether to run eval only once.""")
def eval_once(saver, summary_writer, top_k_op, summary_op):
"""Run Eval once.
Args:
saver: Saver.
summary_writer: Summary writer.
top_k_op: Top K op.
summary_op: Summary op.
"""
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(FLAGS.checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
# Restores from checkpoint
saver.restore(sess, ckpt.model_checkpoint_path)
# Assuming model_checkpoint_path looks something like:
# /my-favorite-path/cifar10_train/model.ckpt-0,
# extract global_step from it.
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
else:
print('No checkpoint file found')
return
# Start the queue runners.
coord = tf.train.Coordinator()
try:
threads = []
for qr in tf.get_collection(tf.GraphKeys.QUEUE_RUNNERS):
threads.extend(qr.create_threads(sess, coord=coord, daemon=True,
start=True))
num_iter = int(math.ceil(FLAGS.num_examples / FLAGS.batch_size))
true_count = 0 # Counts the number of correct predictions.
total_sample_count = num_iter * FLAGS.batch_size
step = 0
while step < num_iter and not coord.should_stop():
predictions = sess.run([top_k_op])
true_count += np.sum(predictions)
step += 1
# Compute precision @ 1.
precision = true_count / total_sample_count
print('%s: precision @ 1 = %.3f' % (datetime.now(), precision))
summary = tf.Summary()
summary.ParseFromString(sess.run(summary_op))
summary.value.add(tag='Precision @ 1', simple_value=precision)
summary_writer.add_summary(summary, global_step)
except Exception as e: # pylint: disable=broad-except
coord.request_stop(e)
coord.request_stop()
coord.join(threads, stop_grace_period_secs=10)
def evaluate():
"""Eval CIFAR-10 for a number of steps."""
with tf.Graph().as_default():
# Get images and labels for CIFAR-10.
eval_data = FLAGS.eval_data == 'test'
images, labels = cifar10.inputs(eval_data=eval_data)
# Build a Graph that computes the logits predictions from the
# inference model.
logits = cifar10.inference(images)
# Calculate predictions.
top_k_op = tf.nn.in_top_k(logits, labels, 1)
# Restore the moving average version of the learned variables for eval.
variable_averages = tf.train.ExponentialMovingAverage(
cifar10.MOVING_AVERAGE_DECAY)
variables_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
# Build the summary operation based on the TF collection of Summaries.
summary_op = tf.summary.merge_all()
graph_def = tf.get_default_graph().as_graph_def()
summary_writer = tf.summary.FileWriter(FLAGS.eval_dir,
graph_def=graph_def)
while True:
eval_once(saver, summary_writer, top_k_op, summary_op)
if FLAGS.run_once:
break
time.sleep(FLAGS.eval_interval_secs)
def main(argv=None): # pylint: disable=unused-argument
cifar10.maybe_download_and_extract()
if gfile.Exists(FLAGS.eval_dir):
gfile.DeleteRecursively(FLAGS.eval_dir)
gfile.MakeDirs(FLAGS.eval_dir)
evaluate()
if __name__ == '__main__':
tf.app.run()
要注意这个注意事项,最好挂起训练程序先
注意:不要在同一块GPU上同时运行训练程序和评估程序,因为可能会导致内存耗尽。尽可能的在其它单独的GPU上运行评估程序,或者在同一块GPU上运行评估程序时先挂起训练程序。
