Shardingjdbc2.0.0之分库深度解析
Shardingjdbc2.0.0之分库深度解析
代码执行环境
Jdk1.8;shardingjdbc 2.0.0;MySQL5.7(应用中配置了2个数据源db1,db2);应用使用表字段shop分库;
本文是根据shardingjdbc2.0.0进行解析的,当时shardingjdbc还没有进入Apache,现在进入了Apache孵化,最新的4.0.0的估计很快就会发布,不管从源码还是项目结构上比较都发生很大的变化,但是分库核心思想都是一样的.
Select:
此处只解析简单的带查询条件的select语句.
Ex: select column1,column2,… from table where clumn3=? and clumn4=? …;
没有分库字段shop的DAO:
@Query(value = "from ShopItemProtectPricePo po")
@Conditions({
@Condition("po.productSaleId = :productSaleId")
})
ShopItemProtectPricePo getShopItemProtectPrice(@Parameter("shop") Long shop, @Parameter("productSaleId") Long productSaleId);
此DAO方法最终生成的查询SQL为:
select id , … , shop , starttime from shop_item_protect_price where productsaleid=?
注意:此处where条件后面只有productsaleid而没有shop,所以此处shardingjdbc 将不能执行按shop分库,shardingjdbc 将会在所有分库上都会执行一次这个查询SQL然后归并结果.
- 解析SQL;
- 执行SQL前shardingjdbc 会先生成路由结果RoutingResult:
io.shardingjdbc.core.routing.type.simple.SimpleRoutingEngine#getShardingValues:

此方法是根据配置的分库字段shardingColumns查找出分库字段的值,此处debug可以看到分库字段是shop,参数parameters中没有shop字段,故结果result的大小为0,即没有找到分库字段.如果找到了会将分库字段的值添加到condition中供后面执行分库路由使用.
io.shardingjdbc.core.routing.type.simple.SimpleRoutingEngine#routeDataSources:

此方法中排队分库值集合是否为空,为空的话就添加所有可用的分库,即此处直接返回我们所配置的所有分库;(此处我只配置了2个)
io.shardingjdbc.core.routing.type.simple.SimpleRoutingEngine#route:

io.shardingjdbc.core.routing.type.simple.SimpleRoutingEngine#generateRoutingResult:
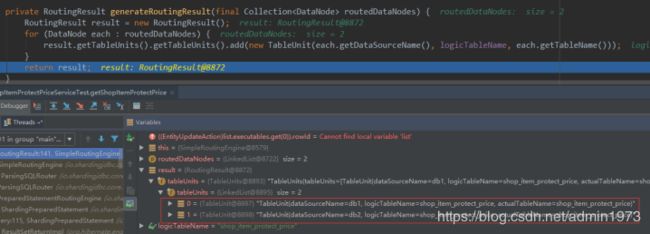
生成RoutingResult,我们debug可以看到最终有多少个分库就产生了多少个TableUnit;(此处为2个)
io.shardingjdbc.core.jdbc.core.statement.ShardingPreparedStatement#route:

根据前面产生的2个TableUnit,此处将生成2个PreparedStatementUnit;
io.shardingjdbc.core.executor.ExecutorEngine#execute

此方法是具体分库执行PreparedStatementUnit的方法,可以看到baseStatementUnits就是前面一个方法产生的2个PreparedStatementUnit,此方法会将第一个PreparedStatementUnit调用syncExecute()同步执行,其它的所有PreparedStatementUnit均调用asyncExecute()异步执行;故此处将会有一个PreparedStatementUnit同步执行,另一个异步执行;
io.shardingjdbc.core.executor.ExecutorEngine#asyncExecute

io.shardingjdbc.core.executor.ExecutorEngine#syncExecute

执行完之后我们可以看到有2个结果集:
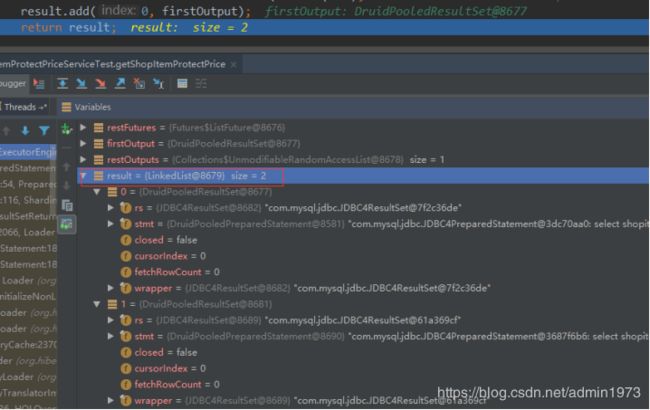

执行完之后此处会进行结果集归并merge,然后将归并后的结果返回;具体实现请看框架实现源码; - 第一次测试:在所有分库表shop_item_protect_price中只存在一条productsaleid = 10000001的数据,虽然返回有两个结果集,但是只有其中一个有值,故归并之后只有一个结果集,满足DAO接口返回参数,程序执行无误;
- 第二次测试:在另一个库中复制一条productsaleid = 10000001的数据,即两个分库中就存在两条数据,查询结果集大小为2,归并之后还是2,此时不满足DAO接口返回参数,Hibernate在绑定PO参数的时候就报以下错误:
org.hibernate.NonUniqueResultException: query did not return a unique result: 2
带有分库字段shop的DAO:
@Query(value = "from ShopItemProtectPricePo po")
@Conditions({
@Condition("po.shop = :shop"),
@Condition("po.productSaleId = :productSaleId")
})
ShopItemProtectPricePo getShopItemProtectPrice(@Parameter("shop") Long shop, @Parameter("productSaleId") Long productSaleId);

SQL where条件带上了shop字段此处就只会产生一个TableUnits并且后面也只会生产一个PreparedStatementUnit,且也只会在一个分库上执行一次,最后还是归并结果.这就是完美无误的根据shop分库.
Insert:
@Save
void save(ShopItemProtectPricePo shopItemProtectPricePo);
io.shardingjdbc.core.parsing.parser.clause.InsertValuesClauseParser#parseValues

此方法shardingjdbc会判断插入的字段中是否包含有分库规则shardingRule中定义的分库字段shop,我们看insertStatemnet中conditions的值中包含有shop这个条件,很明显我们的PO中是有shop这个字段的,满足分库.

io.shardingjdbc.core.routing.type.simple.SimpleRoutingEngine#generateRoutingResult

当然最后也就只会生成一个tableUnits;
io.shardingjdbc.core.routing.router.ParsingSQLRouter#route(java.lang.String, java.util.List

在此route()中我们可以看到shardingjdbc已经按照我们的设置的id生成策略给我们生成好了id即generateKeys中的值,此处我们也可以看到只有一个执行单元executionUnits.后续就只会在一个分库db1里面执行这个插入操作.
接下来我们把PO中的shop字段删除试试:
此时我们就看到分库需要的条件集合是空的:

也就会根据分库数量生成2个tableUnits:

也就会生成2个执行单元:

执行完之后两个分库中将各自生成一条记录,且这两条记录是一样的,大家也可以自己验证一下.
Update:
@Update
void update(ShopItemProtectPricePo shopItemProtectPricePo);
@SaveOrUpdate
void save(ShopItemProtectPricePo shopItemProtectPricePo);
这两个注解在po中主键id不为空时生成的SQL是一样的,会生成以下SQL:
update shop_item_protect_price set basesellprice=?, correct=?, createtime=?, endtime=?, errormsg=?, lastprocesstime=?, onebiteprice=?, outeritemid=?, productsaleid=?, protectprice=?, sellprice=?, starttime=? where id=?
Shardingjdbc会像分析select语句一样分析where后面的条件是否包含有分库字段shop,有的话就只生成对应分库执行单元,并且也就执行在一个分库上,此处生产的where条件只有id不包含shop,故会与上述分析的一样生成2个执行单元.
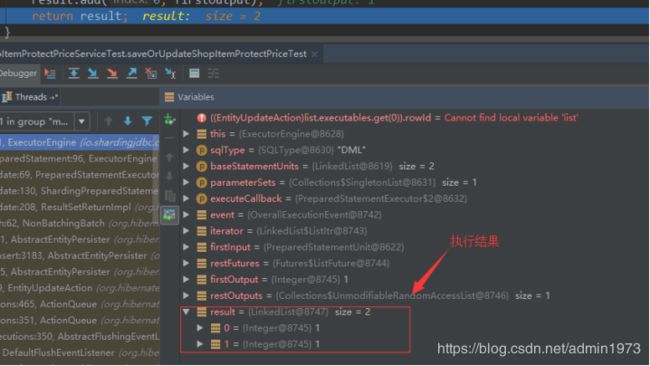
这是归并前的执行结果,可以and两个分库均执行成功了,且都返回影响行数是1,故总共修改了2条数据(这儿之所有修改了两条数据是因为我人为的在两个分库中创建了两条id一样的数据,正常生产情况下我们的id生成策略是唯一的,所以全局不会出现重复的id,也就是说再执行以下SQL结果集也是两个但是一个影响行数是1其它都是0,此时事务可以正常提交)
io.shardingjdbc.core.executor.type.prepared.PreparedStatementExecutor#executeUpdate

此处shardingjdbc将归并结果,当然1+1=2,此时就该轮到提交事务了,提交事务是报了以下错误,意思就是期望修改1条数据,实际上是修改了2条数据,事务提交失败,两个分库的数据均回滚.
org.springframework.orm.hibernate4.HibernateSystemException: Batch update returned unexpected row count from update [0]; actual row count: 2; expected: 1; nested exception is org.hibernate.jdbc.BatchedTooManyRowsAffectedException: Batch update returned unexpected row count from update [0]; actual row count: 2; expected: 1
结论:
没有包含分库字段的SQL会执行在所有分库,会占用大量的连接,严重影响正常业务数据流转.
- 在使用shardingjdbc作为分库组件时执行的insert SQL中插入字段必须包含分库字段(此文中是shop);
- 在使用shardingjdbc作为分库组件时执行的update/select SQL中where条件段必须包含分库字段(此文中是shop);
- 禁止在Hibernate同一session范围内修改同一PO对象,因为此时Hibernate会检查到PO内容发生变化会发送一个PRE_UPDATE事件通知,此通知会执行一个条件只有id(即where id = ?)的SQL,此时就会执行在多个分库上.
应用调整意见:
1.检查应用中是否存在使用Hibernate注解@Update @SaveOrUpdate,存在请使用自定义SQL替换且SQL中where条件必须包含分库字段(此文是shop);
2.检查应用在同一Hibernate session范围内是否存在修改PO的内容,如果存在可以将被hibernate管理的那个PO对象的值拷贝到一个新new 的PO对象,然后使用新对象去做修改.
3.在应用中主键id生成策略是全局唯一的,所以直接使用@Update 和 @SaveOrUpdate注解更新数据,数据完整性是一致的,不会存在乱更新数据,但是存在浪费数据库连接资源.