使用pandas进行数据清洗
本文转载自:蓝鲸的网站分析笔记
原文链接:使用python进行数据清洗
目录:
- 数据表中的重复值
- duplicated()
- drop_duplicated()
- 数据表中的空值/缺失值
- isnull()¬null()
- dropna()
- fillna()
- 数据间的空格
- 查看数据中的空格
- 去除数据中的空格
- 大小写转换
- 数据中的异常和极端值
- replace()
- 更改数据格式
- astype()
- to_datetime()
- 数据分组
- cut()
- 数据分列
- split()
数据清洗是一项复杂且繁琐(kubi)的工作,同时也是整个数据分析过程中最为重要的环节。有人说一个分析项目80%的时间都是在清洗数据,这听起来有些匪夷所思,但在实际的工作中确实如此。数据清洗的目的有两个,第一是通过清洗让数据可用。第二是让数据变的更适合进行后续的分析工作。换句话说就是有”脏”数据要洗,干净的数据也要洗。本篇文章将介绍几种简单的使用python进行数据清洗的方法。

开始之前还是先在python中导入需要使用的库文件,然后进行数据读取,并创建名为loandata的数据表。这里为了更好的展示清洗的步骤和结果,我们使用的是lendingclub公开数据中的一小部分。
|
1
2
3
|
import numpy as np
import pandas as pd
loandata=pd.DataFrame(pd.read_excel('loandata.xlsx'))
|
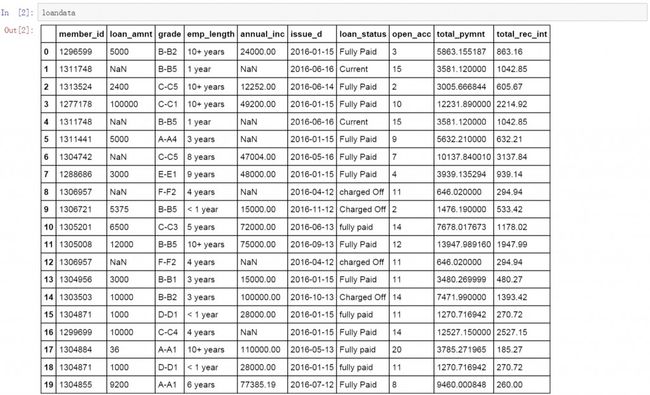
数据清洗的目的有两个,第一是通过清洗让脏数据变的可用。这也是我们首先要解决的问题。无论是线下人工填写的手工表,还是线上通过工具收集到的数据,又或者是CRM系统中导出的数据。很多数据源都有一些这样或者那样的问题,例如:数据中的重复值,异常值,空值,以及多余的空格和大小写错误的问题。下面我们逐一进行处理。
数据表中的重复值
第一个要处理的问题是数据表中的重复值,pandas中有两个函数是专门用来处理重复值的,第一个是duplicated函数。Duplicated函数用来查找并显示数据表中的重复值。下面是使用这个函数对数据表进行重复值查找后的结果。
|
1
|
loandata.duplicated()
|

这里有两点需要说明:第一,数据表中两个条目间所有列的内容都相等时duplicated才会判断为重复值。(Duplicated也可以单独对某一列进行重复值判断)。第二,duplicated支持从前向后(first),和从后向前(last)两种重复值查找模式。默认是从前向后进行重复值的查找和判断。换句话说就是将后出现的相同条件判断为重复值。在前面的表格中索引为4的1311748和索引为1的条目相同。默认情况下后面的条目在重复值判断中显示为True。
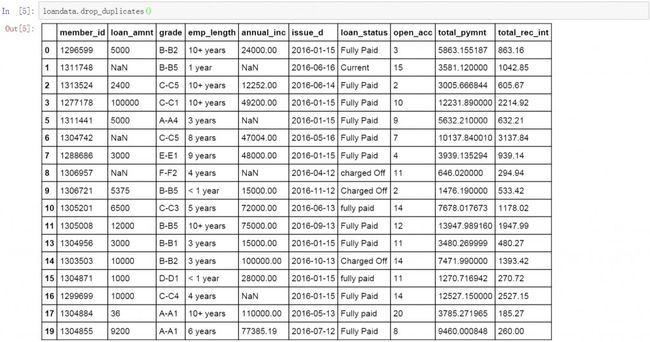
Pandas中的drop_duplicates函数用来删除数据表中的重复值,判断标准和逻辑与duplicated函数一样。使用drop_duplicates函数后,python将返回一个只包含唯一值的数据表。下面是使用drop_duplicates函数后的结果。与原始数据相比减少了3行,仔细观察可以发现,drop_duplicates默认也是使用了first模式删除了索引为4的重复值,以及后面的另外两个重复值。
|
1
|
loandata.drop_duplicates()
|
数据表中的空值/缺失值
第二个要处理的问题是数据表中的空值,在python中空值被显示为NaN。在处理空值之前我们先来检查下数据表中的空值数量。对于一个小的数据表,我们可以人工查找,但对于较为庞大的数据表,就需要寻找一个更为方便快捷的方法了。首先,对关键字段进行空值查找。这里我们分别选择了对loan_amnt字段和annual_inc字段查找空值。
Pandas中查找数据表中空值的函数有两个,一个是函数isnull,如果是空值就显示True。另一个函数notnull正好相反,如果是空值就显示False。以下两个函数的使用方法以及通过isnull函数获得的空值数量。
|
1
|
loandata.isnull()
|
|
1
|
loandata.notnull()
|
通过isnull函数和value_counts函数分别获得了loan_amnt列和annual_inc列中的空值数据量。


对于空值有两种处理的方法,第一种是使用fillna函数对空值进行填充,可以选择填充0值或者其他任意值。第二种方法是使用dropna函数直接将包含空值的数据删除。
|
1
|
loandata.fillna(0)
|
|
1
|
loandata.dropna()
|
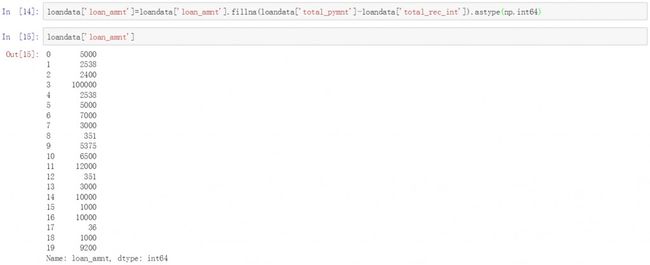
这里我们选择对空值数据进行填充,首先处理loan_amnt列中的空值。通过totalpymnt字段和total_tec_int字段值相减计算出loan_amnt列中的近似值。因为这里除了利息以外还可能包括一些逾期费,手续费和罚息等,所以只能获得一个实际贷款金额近似值。由于贷款金额通常是一个整数,因此我们在代码的最后对格式进行了转换。
|
1
|
loandata['loan_amnt']=loandata['loan_amnt'].fillna(loandata['total_pymnt']-loandata['total_rec_int']).astype(np.int64)
|
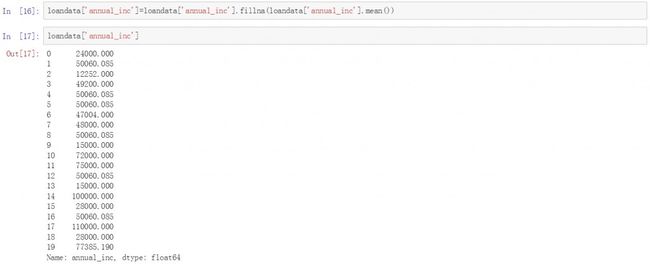
对于annual_inc列,在原始数据表中没有可用的辅助列进行计算,因此我们选择用现有数据的均值进行填充。这里可以看到贷款用户的收入均值为50060美金。使用这个值对annual_inc中的空值进行填充。
|
1
|
loandata['annual_inc']=loandata['annual_inc'].fillna(loandata['annual_inc'].mean())
|
数据间的空格
第三个要处理的是数据中的空格。空格会影响我们后续会数据的统计和计算。从下面的结果中就可以看出空格对于常规的数据统计造成的影响。
查看数据中的空格
我们再对loan_status列进行频率统计时,由于空格的问题,相同的贷款状态被重复计算。造成统计结果不可用。因此,我们需要解决字段中存在的空格问题。
|
1
|
loandata['loan_status'].value_counts()
|

去除数据中的空格
Python中去除空格的方法有三种,第一种是去除数据两边的空格,第二种是单独去除左边的空格,第三种是单独去除右边的空格。
|
1
|
loandata['term']=loandata['term'].map(str.strip)
|
|
1
|
loandata['term']=loandata['term'].map(str.lstrip)
|
|
1
|
loandata['term']=loandata['term'].map(str.rstrip)
|
这里我们使用去除两边的空格来处理loan_status列中的空格。以下是具体的代码和去除空格后的结果。
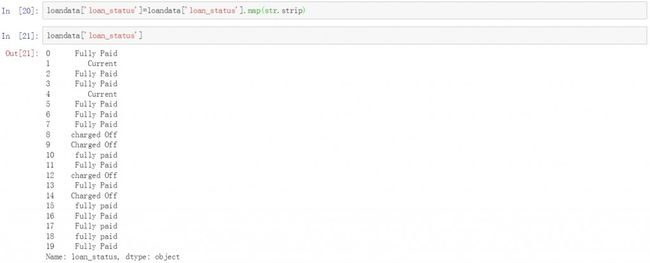
重新查看loan_status列中每种贷款状态的频率,之前空格造成的影响已经没有了,但这里还有个问题,就是大小写的问题。因此,我们还需要对每种贷款状态的大小写进行统一化处理。这是我们第四个要处理的问题。

大小写转换
大小写转换的方法也有三种可以选择,分别为全部转换为大写,全部转换为小写,和转换为首字母大写。
|
1
|
loandata['term']=loandata['term'].map(str.upper)
|
|
1
|
loandata['term']=loandata['term'].map(str.lower)
|
|
1
|
loandata['term']=loandata['term'].map(str.title)
|
这里我们将所有贷款状态转换为首字母大写模式,并再次进行频率统计。从下面的结果中可以看出,结果以及消除了空格和大小写字母混乱的影响。清晰的显示了贷款的三种状态出现的频率。

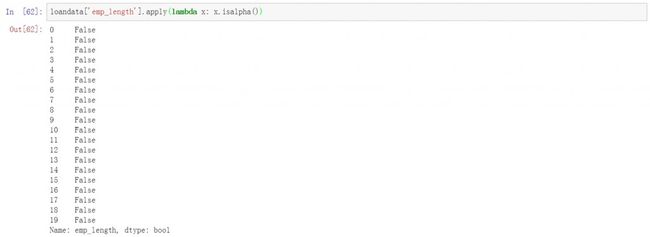
最后我们还需要对数据表中关键字段的内容进行检查,确保关键字段中内容的统一。主要包括数据是否全部为字符,或数字。下面我们对emp_length列进行检验,此列内容由数字和字符组成,如果只包括字符,说明可能存在问题。下面的代码中我们检查该列是否全部为字符。答案全部为False。
|
1
|
loandata['emp_length'].apply(lambda x: x.isalpha())
|
除此之外,还能检验该列的内容是否全部为字母或数字。或者是否全部为数字。
|
1
|
loandata['emp_length'].apply(lambda x: x. isalnum ())
|
|
1
|
loandata['emp_length'].apply(lambda x: x. isdigit ())
|
数据中的异常和极端值
第五个要处理的问题是数据中的异常值和极端值,发现异常值和极端值的方法是对数据进行描述性统计。使用describe函数可以生成描述统计结果。其中我们主要关注最大值(max)和最小值(min)情况。
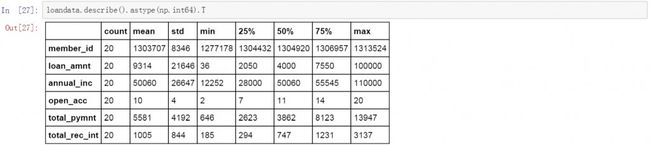
检查异常和极端值
下面是对数据表进行描述统计的结果,其中loan_amnt的最大值和最小值分别为100000美金和36美金,这不符合业务逻辑,因此可以判断为异常值。
|
1
|
loandata.describe().astype(np.int64).T
|
异常数据替换
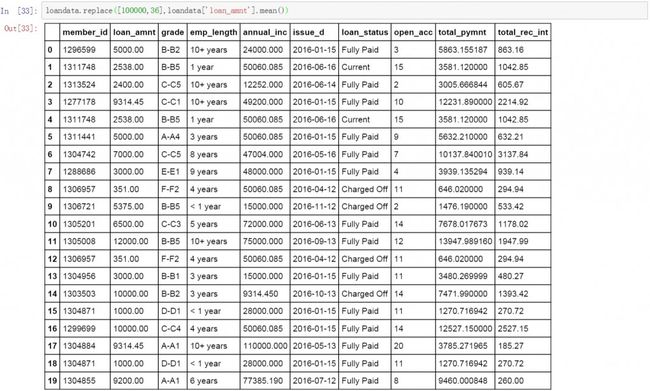
对于异常值数据我们这里选择使用replace函数对loan_amnt的异常值进行替换,这里替换值选择为loan_amnt的均值。下面是具体的代码和替换结果。
|
1
|
loandata.replace([100000,36],loandata['loan_amnt'].mean())
|
数据清洗的第二个目的是让数据更加适合后续的分析工作。提前对数据进行预处理,后面的挖掘和分析工作会更加高效。这些预处理包括数据格式的处理,数据分组和对有价值信息的提取。下面我们逐一来介绍这部分的操作过程和使用到的函数。
更改数据格式
第一步是更改和规范数据格式,所使用的函数是astype。下面是更改数据格式的代码。对loan_amnt列中的数据,由于贷款金额通常为整数,因此我们数据格式改为int64。如果是利息字段,由于会有小数,因此通常设置为float64。
|
1
|
loandata['loan_amnt']=loandata['loan_amnt'].astype(np.int64)
|
在数据格式中还要特别注意日期型的数据。日期格式的数据需要使用to_datatime函数进行处理。下面是具体的代码和处理后的结果。
|
1
|
loandata['issue_d']=pd.to_datetime(loandata['issue_d'])
|
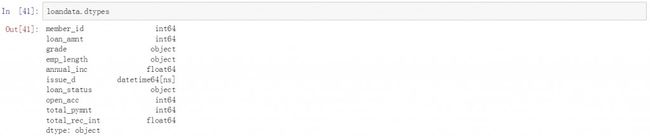
格式更改后可以通过dtypes函数来查看,下面显示了每个字段的数据格式。
|
1
|
loandata.dtypes
|
数据分组
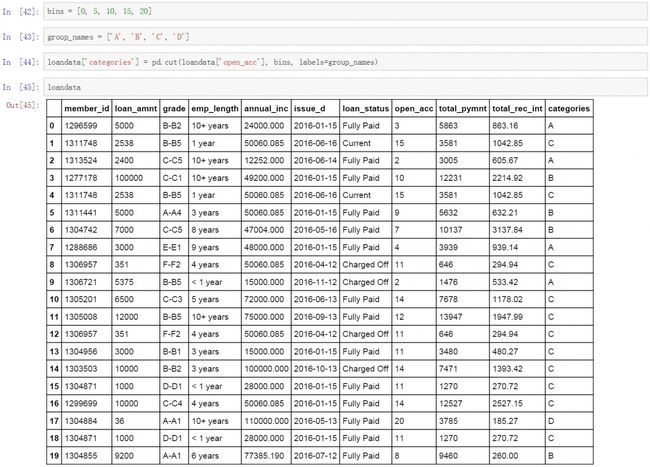
第二步是对数据进行分组处理,在数据表的open_acc字段记录了贷款用户的账户数量,这里我们可以根据账户数量的多少对用户进行分级,5个账户以下为A级,5-10个账户为B级,依次类推。下面是具体的代码和处理结果。
|
1
2
3
|
bins = [0, 5, 10, 15, 20]
group_names = ['A', 'B', 'C', 'D']
loandata['categories'] = pd.cut(loandata['open_acc'], bins, labels=group_names)
|
首先设置了数据分组的依据,然后设置每组对应的名称。最后使用cut函数对数据进行分组并将分组后的名称添加到数据表中。
数据分列
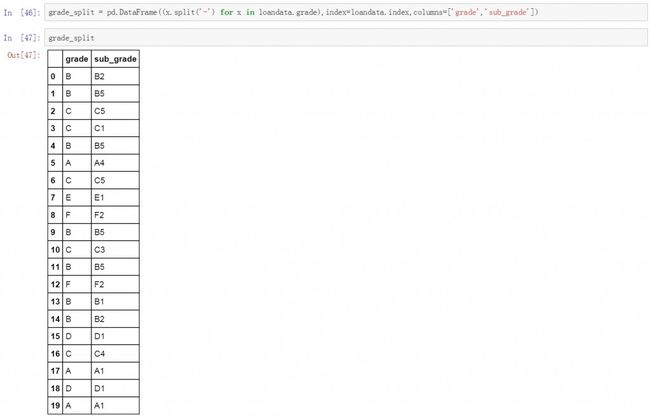
第四步是数据分列,这个操作和Excel中的分列功能很像,在原始数据表中grade列中包含了两个层级的用户等级信息,现在我们通过数据分列将分级信息进行拆分。数据分列操作使用的是split函数,下面是具体的代码和分列后的结果。
|
1
|
grade_split = pd.DataFrame((x.split('-') for x in loandata.grade),index=loandata.index,columns=['grade','sub_grade'])
|
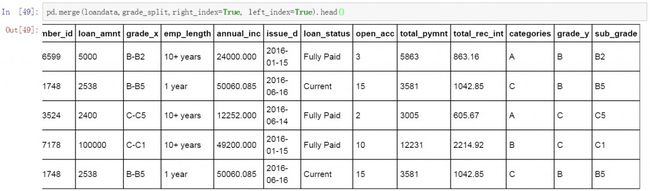
完成数据分列操作后,使用merge函数将数据匹配会原始数据表,这个操作类似Excel中的Vlookup函数的功能。通过匹配原始数据表中包括了分列后的等级信息。以下是具体的代码和匹配后的结果。
|
1
|
loandata=pd.merge(loandata,grade_split,right_index=True, left_index=True)
|