机器学习笔记——KNN与Digit Recognizer问题
KNN算法
KNN算法采用多数表决,即由输入实例的k个临近的训练实例的多数类决定输入实例的类.
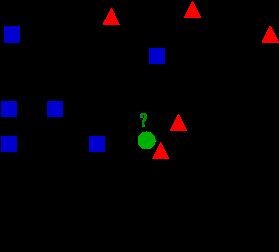
因此k值的选择会对结果产生较大影响.
k值较小:预测结果会对近邻的实例点非常敏感,整体模型变得复杂,容易过拟合.
k值较大:可以减小估计误差,但此时距离较远的实例也可能起预测作用,整体模型变得简单(极端情况:k=实例总数).
实验:
iris数据集分3类,每类50组数据,共150组.
每组数据包含花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性.
以下利用KNN对iris数据进行分析实验.
先将数据随机划分为训练集(120组)和测试集(30组),然后利用KNN对测试集中的30组数据的类别进行预测,并和实际结果进行比对.
手动实现KNN
#!/usr/bin/python
# -*-coding:utf-8-*-
import numpy as np
import operator
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
iris = load_iris()
# 区间缩放
data = MinMaxScaler().fit_transform(iris.data)
# 随机划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data, iris.target, test_size=3./15, random_state=1)
error = 0
for i in range(len(x_test)):
data = np.mat(x_test[i])
x_train = np.mat(x_train)
# 计算距离差
difMat = np.tile(data, (x_train.shape[0], 1)) - x_train
squareDifMat = np.array(difMat)**2
squaredistance = squareDifMat.sum(axis=1)
# 将距离按行从小到大排序的索引值
sortIndex = np.argsort(squaredistance)
# 选择前5个进行投票
vote = {}
for j in range(5):
label = y_train[sortIndex[j]]
vote[label] = vote.get(label, 0) + 1
# 按vote的第2维进行排序
sortVote = sorted(vote.iteritems(), key=operator.itemgetter(1), reverse=True)
# # 打印对比预测类别和实际类别
# print sortVote[0][0], y_test[i]
if sortVote[0][0] != y_test[i]:
error += 1
print 'the total number of errors: %d' % error
print 'the total error rate: %.4f' % (error/float(len(x_test)))输出:
the total number of errors: 1
the total error rate: 0.0333调用sklearn接口
#!/usr/bin/python
# -*-coding:utf-8-*-
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
# 区间缩放
data = MinMaxScaler().fit_transform(iris.data)
# 随机划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data, iris.target, test_size=3./15, random_state=1)
# 利用KNeighborsClassifier进行分类
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(x_train, y_train)
error = 0
for i in range(len(x_test)):
if neigh.predict(x_test[i])[0] != y_test[i]:
error += 1
# print neigh.predict(x_test[i])[0], y_test[i]
print error输出:
0Digit Recognizer问题
利用KNN尝试解决Kaggle中的Digit Recognizer问题.
Digit Recognizer 问题描述&数据下载
手动实现KNN
#!/usr/bin/python
# -*-coding:utf-8-*-
import numpy as np
import csv
import operator
def loaddata(path):
l = []
with open(r'%s'%path) as file:
lines = csv.reader(file)
for line in lines:
l.append(line)
# 去除第1行
l.remove(l[0])
data = []
for i in l:
# 将list内的字符串转化为int数据
data.append(map(int, i))
# 转换为矩阵
data = np.mat(np.array(data))
return data
train = loaddata('data/train.csv')
testData = loaddata('data/test.csv')
knn_benchmark = loaddata('data/knn_benchmark.csv')
trainData = train[:,1:]
trainLabel = train[:,0]
testLabel = knn_benchmark[:,-1]
m, n = np.shape(testData)
errorCount = 0
resultList = []
# 取m = m/100,这里只使用前280个测试数据
m = m/100
error = 0
for i in range(m):
data = np.mat(testData[i])
x_train = np.mat(trainData)
# 计算距离差
difMat = np.tile(data, (x_train.shape[0], 1)) - x_train
squareDifMat = np.array(difMat)**2
squaredistance = squareDifMat.sum(axis=1)
# 将距离按行从小到大排序的索引值
sortIndex = np.argsort(squaredistance)
# 选择前5个进行投票
vote = {}
for j in range(5):
label = trainLabel[sortIndex[j],0]
vote[label] = vote.get(label, 0) + 1
# 按vote的第2维进行排序
sortVote = sorted(vote.iteritems(), key=operator.itemgetter(1), reverse=True)
# # 打印对比预测类别和实际类别
# print sortVote[0][0], y_test[i]
if sortVote[0][0] != testLabel[i,0]:
error += 1
if sortVote[0][0] != testLabel[i, 0]:
print sortVote[0][0],testLabel[i, 0]
print 'the total number of errors: %d' % error
print 'the total error rate: %.4f' % (error/float(m))
输出:
9 4
4 9
7 1
8 9
8 1
9 4
3 7
9 4
5 4
the total number of errors: 9
the total error rate: 0.0321利用sklearn中的KNeighborsClassifier实现:
#!/usr/bin/python
# -*-coding:utf-8-*-
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import csv
import operator
# 'data/knn_benchmark.csv'
def loaddata(path):
l = []
with open(r'%s'%path) as file:
lines = csv.reader(file)
for line in lines:
l.append(line)
# 去除第1行
l.remove(l[0])
data = []
for i in l:
# 将list内的字符串转化为int数据
data.append(map(int, i))
# 转换为矩阵
data = np.mat(np.array(data))
return data
train = loaddata('data/train.csv')
testData = loaddata('data/test.csv')
knn_benchmark = loaddata('data/knn_benchmark.csv')
trainData = train[:,1:]
trainLabel = train[:,0]
testLabel = knn_benchmark[:,-1]
neigh = KNeighborsClassifier(n_neighbors=5)
neigh.fit(trainData, trainLabel)
error = 0
predict = []
for i in range(len(knn_benchmark)):
predict.append(neigh.predict(testData[i])[0])
if neigh.predict(testData[i])[0] != testLabel[i,0]:
error += 1
print neigh.predict(testData[i])[0], testLabel[i,0]
print 'the total number of errors: %d' % error
print 'the total error rate: %.4f' % (error/float(len(trainData)))
writer = csv.writer(file('predict.csv', 'wb'))
# 在首行写入对应数据名称
writer.writerow(['ImageId', 'Label'])
# 写入数据
for i in xrange(len(predict)):
l = np.hstack((np.array([i+1]), np.array(predict[i])))
writer.writerow(l)
输出:
9 4
4 9
7 1
8 9
.
.
.
7 1
4 9
9 7
6 1
the total number of errors: 415
the total error rate: 0.0099文件predict.csv内容为:

查看.csv文件中的数字:
#!/usr/bin/python
#coding:utf-8
import matplotlib.pyplot as plt
import pandas as pd
labeled_images = pd.read_csv(r'data/train.csv')
images = labeled_images.iloc[0:5000,1:]
labels = labeled_images.iloc[0:5000,:1]
for i in range(9):
img=images.iloc[i].as_matrix()
img=img.reshape((28,28))
plt.subplot(331+i), plt.imshow(img, cmap='gray'), plt.title(labels.iloc[i, 0])
plt.show()显示前9个数字的图像为:
